SD XL




















세부 정보
파일 다운로드
모델 설명
원래 Hugging Face에 게시됨이며, Stability AI의 허가를 받아 여기에 공유됩니다.
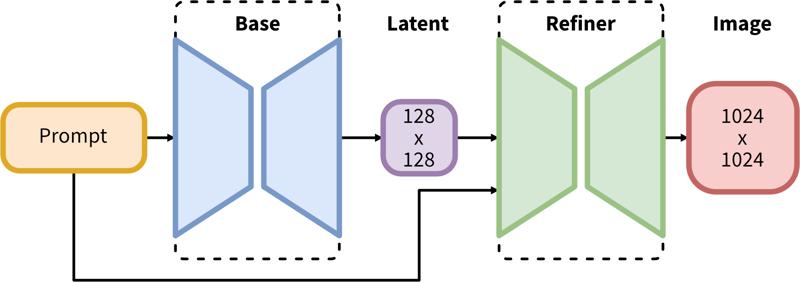
SDXL은 잠재 공간 확산을 위한 두 단계 파이프라인으로 구성됩니다. 먼저, 원하는 출력 크기의 잠재 변수를 생성하기 위해 기본 모델을 사용합니다. 두 번째 단계에서는 고해상도 전용 모델을 사용하여 첫 번째 단계에서 생성된 잠재 변수에 동일한 프롬프트를 기반으로 SDEdit 기법(https://arxiv.org/abs/2108.01073, 'img2img'로도 알려짐)을 적용합니다.
모델 설명
개발자: Stability AI
모델 유형: 확산 기반 텍스트-이미지 생성 모델
모델 설명: 이 모델은 텍스트 프롬프트를 기반으로 이미지를 생성하고 수정하는 데 사용할 수 있습니다. 잠재 공간 확산 모델로, 두 개의 고정된 사전 학습된 텍스트 인코더(OpenCLIP-ViT/G 및 CLIP-ViT/L)를 사용합니다.
추가 정보 리소스: GitHub 저장소.
모델 출처
데모 [선택 사항]: https://clipdrop.co/stable-diffusion
사용 용도
직접 사용
이 모델은 연구 목적으로만 사용되도록 설계되었습니다. 가능한 연구 분야 및 작업은 다음과 같습니다:
예술 작품 생성 및 디자인 및 기타 예술적 프로세스에서의 활용
교육 또는 창의적 도구에서의 적용
생성 모델에 대한 연구
해로운 콘텐츠를 생성할 잠재력을 가진 모델의 안전한 배포
생성 모델의 한계와 편향 탐색 및 이해
제외된 사용 사례는 아래에 기술되어 있습니다.
범위 외 사용
이 모델은 사람이나 사건에 대한 사실적이거나 진실된 표현을 생성하도록 학습되지 않았으므로, 이러한 콘텐츠를 생성하는 데 사용하는 것은 이 모델의 능력 범위를 벗어납니다.
한계와 편향
한계
모델은 완벽한 사진적 사실성을 달성하지 못합니다.
모델은 가독성 있는 텍스트를 렌더링할 수 없습니다.
모델은 "파란 구체 위에 빨간 큐브"와 같은 구성적 작업을 포함하는 더 어려운 작업에 어려움을 겪습니다.
얼굴 및 일반적으로 사람의 생성이 제대로 이루어지지 않을 수 있습니다.
모델의 자동 인코딩 부분은 손실이 있습니다.
편향
이미지 생성 모델의 능력은 인상적이지만, 사회적 편향을 강화하거나 악화시킬 수도 있습니다.
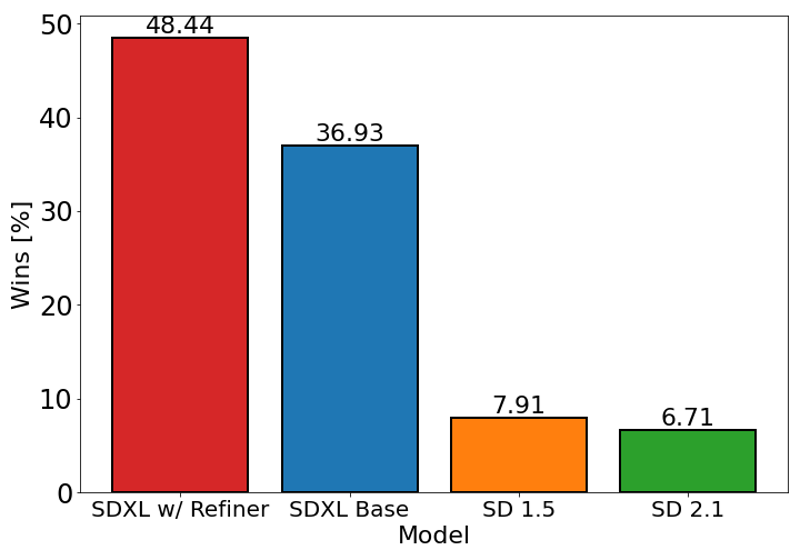
위 차트는 SDXL(정제 여부에 따라)이 Stable Diffusion 1.5 및 2.1보다 사용자에게 더 선호되는지를 평가합니다. SDXL 기본 모델은 이전 버전보다 훨씬 우수하며, 정제 모듈과 결합된 모델이 가장 뛰어난 종합 성능을 보입니다.