SD XL




















詳細
ファイルをダウンロード
モデル説明
元々はHugging Faceに掲載され、Stability AIの許可を得てここに共有されています。
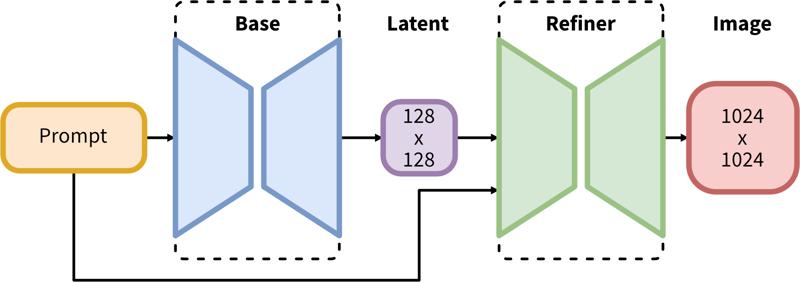
SDXLは潜在的拡散の2段階パイプラインで構成されています。まず、ベースモデルを使用して目的の出力サイズの潜在変数を生成します。次に、2番目のステップで、専用の高解像度モデルを使用し、同じプロンプトを用いて最初のステップで生成された潜在変数にSDEditという技術(https://arxiv.org/abs/2108.01073、別名「img2img」)を適用します。
モデルの説明
開発者: Stability AI
モデルの種類: 拡散ベースのテキストから画像への生成モデル
モデルの説明: このモデルは、テキストプロンプトに基づいて画像を生成・変更するために使用できます。潜在的拡散モデルであり、2つの固定された事前学習済みのテキストエンコーダー(OpenCLIP-ViT/G および CLIP-ViT/L)を使用しています。
詳細情報のリソース: GitHubリポジトリ。
モデルのソース
デモ[オプション]: https://clipdrop.co/stable-diffusion
利用用途
直接的な利用
このモデルは研究目的での使用を想定しています。可能な研究分野やタスクには以下が含まれます。
アート作品の生成およびデザインその他の芸術的プロセスへの利用。
教育ツールや創造的ツールへの応用。
生成モデルに関する研究。
危険なコンテンツを生成する可能性のあるモデルの安全な展開。
生成モデルの限界やバイアスの調査と理解。
除外される利用については以下に記載します。
適用外の利用
このモデルは、人物や出来事の事実的または真実的な表現を学習するように訓練されていないため、そのようなコンテンツを生成することを目的とした利用は、このモデルの能力の範囲外です。
制限とバイアス
制限
モデルは完璧な写実性を達成できません。
モデルは読み取れるテキストを描画できません。
「青い球の上に赤い立方体がある」のような複合的な構成を伴うより困難なタスクで課題を抱えています。
顔や人物全般が適切に生成されないことがあります。
モデルの自己符号化部分は損失を伴います。
バイアス
画像生成モデルの能力は驚異的ですが、社会的バイアスを強化または悪化させる可能性もあります。
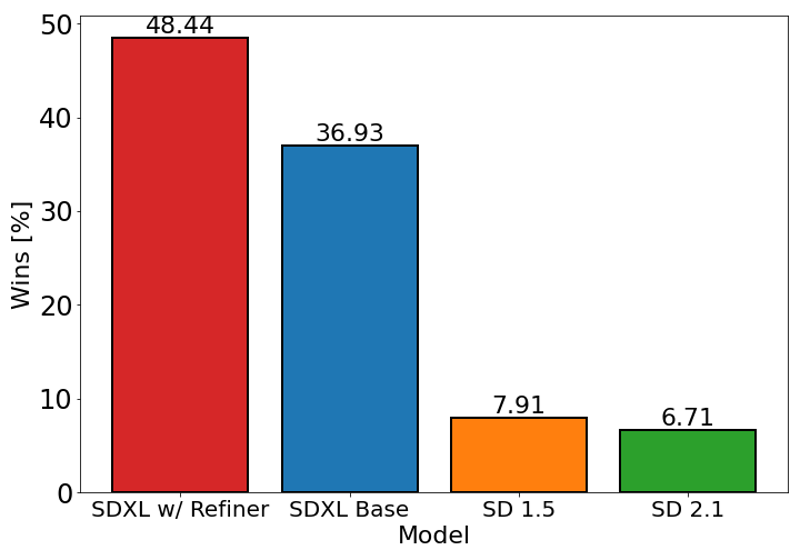
上記のチャートは、SDXL(微調整あり・なし)とStable Diffusion 1.5および2.1に対するユーザーの好ましさを評価しています。SDXLベースモデルは、以前のバージョンよりも顕著に優れており、微調整モジュールと組み合わせたモデルが最も優れた全体的なパフォーマンスを達成しています。