Illustrious XL 1.0







详情
下载文件
模型描述
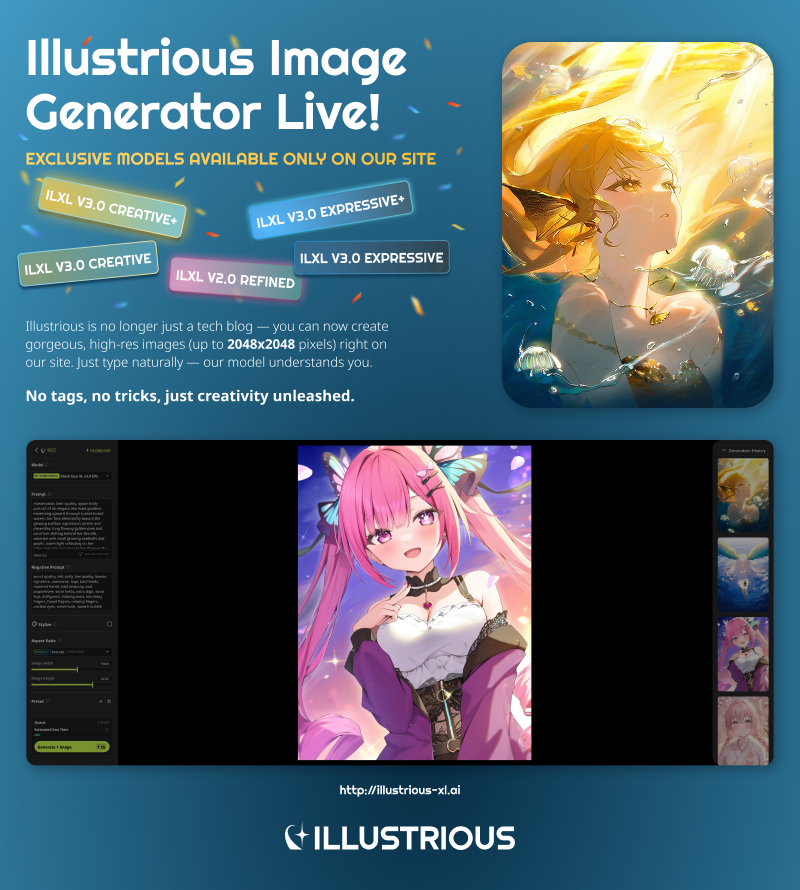 访问我们的网站,了解我们最新的工作成果并探索我们的最新模型!
访问我们的网站,了解我们最新的工作成果并探索我们的最新模型!
→https://www.illustrious-xl.ai/
我们很高兴地宣布,您现在可以直接在我们的官方网站上使用 Illustrious XL 模型生成图像:[illustrious-xl.ai]。我们已推出一个完整的图像生成平台,支持高分辨率输出、自然语言提示和自定义预设——此外,还有数款独家模型,其他平台均无法获得。请查阅我们更新的模型层级与命名:[Model Series]。需要帮助入门?请参阅我们的生成用户指南:[ILXL Image Generation User Guide]。
Illustrious XL v1.0——专注于高分辨率的插画生成模型
概述
Illustrious XL v1.0 是由 OnomaAI 开发的前沿生成模型,基于 Stable Diffusion XL 架构,由我们先前的检查点 Illustrious XL v0.1 训练而来,专为生成惊艳的高分辨率图像而设计。它在 SDXL 框架内实现了前所未有的原生 1536×1536 分辨率,突破了以往在细节与清晰度方面的限制。该模型无缝融合了自然语言理解与基于标签的提示(Danbooru 风格),允许用户使用描述性语句或具体标签(或两者结合),实现灵活且强大的提示处理方式。因此,Illustrious XL v1.0 是追求内容生成多样性同时不牺牲保真度的创作者的强力基础。
知识截止时间
Illustrious XL v1.0 于 2024 年 7 月训练完成,知识截止至 2024 年 6 月。
然而,由于其原生支持 v0.1 LoRA,您可能无需担心知识限制!
主要特性
1536×1536 原生分辨率:
首个原生支持 1536 像素分辨率的 Stable Diffusion XL 模型。可在以前 SDXL 无法实现的高分辨率下生成具有卓越细节、锐度和清晰度的图像。它支持 512x512 至 1536x1536 之间的广泛分辨率范围——例如 1248x1824 无需任何高分辨率修饰即可生成。
NLP + 基于标签的提示:
将先进的自然语言处理与 Danbooru 风格的标签提示相结合。尽管标签方式更加简洁精准,但这种混合提示系统允许您使用纯英文描述、精确标签(或两者兼用)——模型能理解并充分利用每种方式,从而在图像生成中提供更大的控制力和细腻度。
广泛兼容性:
完全兼容多种扩展与插件。在 Illustrious v0.1 上训练的 LoRA、ControlNet 模块及其他适配方法均可无缝与 v1.0 配合使用。您可以自由组合增强功能,微调风格、姿势或构图,而不会破坏兼容性。
预训练基础模型:
Illustrious XL v1.0 提供为未经特定美学或偏见微调的预训练基础检查点。这一“原始”模型为进一步训练提供了坚实基础——非常适合希望自行进行微调(例如 LoRA 训练)以实现特定艺术风格或专业输出的创作者。它是新创意的灵活起点。
未来计划
v2/v3 版本支持更高分辨率:
计划发布后续版本(Illustrious XL v2 和 v3),支持更大的分辨率,目标高达 2K 及以上。预计将带来更丰富的细节和更强的缩放能力,实现超清晰的大尺寸图像。
v-parameterization 模型与色彩控制:
一种专用的 v-parameterization 变体已准备就绪,突破了 SD XL 既往被认为的理论与实践极限。同时,未来版本将聚焦增强色彩控制,让用户对生成图像的色彩平衡与一致性拥有更精细的调节能力。
持续改进:
Illustrious 的路线图充满雄心——每次迭代都将整合社区反馈与最新研究。我们将继续在高分辨率领域深耕,以谨慎而精密的方法突破以往被认为的界限。