ON-THE-FLY 实时生成!Wan-AI 万相/ Wan2.1 Video Model (multi-specs) - CausVid&Comfy&Kijai - workflow included

详情
下载文件
关于此版本
模型描述
万相一体,万象归一
我们很高兴向才华横溢的创作者社区推出我们的最新模型:
Wan2.1-VACE,一体化视频创作与编辑模型。
模型大小:1.3B、14B 许可证:Apache-2.0
如果我们在万相世界,会是什么样子?
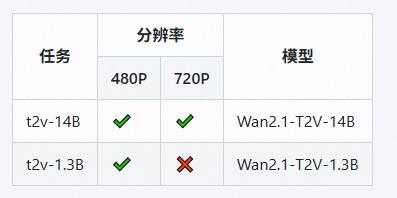
模型支持两种文本到视频模型(1.3B 和 14B)和两种分辨率(480P 和 720P)。
WAN-VACE 本身并非T2V模型,而是 R(参考)2V,可理解为 WAN 的视频 ControlNet,因此无法提供 T2V 工作流。CausVid 加速器是一种蒸馏加速技术,可用于 WAN-VACE,实现 4–8 步加速生成。
WAN-VACE 本身不是 T2V 模型,而是 R(参考)2V,可理解为 WAN 的视频 CN,因此无法提供 T2V 工作流。CausVid 加速器是一种蒸馏加速技术,可用于 WAN-VACE,提供 4–8 步加速生成。
简介
VACE 是一款专为视频创作与编辑设计的一体化模型,涵盖多种任务,包括参考到视频生成(R2V)、视频到视频编辑(V2V)和掩码视频到视频编辑(MV2V),允许用户自由组合这些任务。该功能使用户能够探索多样化的创作可能,并有效简化工作流程,提供诸如“移动任意内容”、“交换任意内容”、“引用任意内容”、“扩展任意内容”、“动画化任意内容”等多种能力。

VACE 是一款专为视频创作和编辑而设计的一体化模型。它包括各种任务,包括视频生成(R2V)、视频到视频编辑(V2V)和屏蔽视频到视频剪辑(MV2V),允许用户自由组合这些任务。此功能使用户能够探索各种可能性,并有效地简化他们的工作流程,提供一系列功能,如移动任何内容、交换任何内容、引用任何内容、扩展任何内容、为任何内容设置动画等。
关于 CausVid**-Wan2-1**:
5–16 Kijai 提供的 CausVid 的完美解决方案(最佳实践)
Wan21_CausVid_14B_T2V_lora_rank32.safetensors · Kijai/WanVideo_comfy
通过权重提取和模块分离,
KJ 为我们提供了一个适用于任何 14B WAN 模型的通用 CausVid LoRA(rank32),
甚至包括微调模型和 I2V 模型!
尽管这可能并非 CausVid 的初衷,但通过灵活调整 LoRA 参数(0.3~0.5),我们在消费级显卡上实现了前所未有的可用性!
KJ-神级还提供了一个1.3B 双向推理版本的 LoRA 导出文件:
Wan21_CausVid_bidirect2_T2V_1_3B_lora_rank32.safetensors
同时,我们也注意到 xunhuang1995 上传了来自 tianweiy/CausVid 的 Warp-4Step_cfg2 自回归版本 1.3B CausVid 模型:
相与为壹,全部在万
WAN-VACE 全模型的最佳适配
5/15 REDCausVid**-Wan2-1**-14B-DMD2-FP8 上传了 8–15 步 CFG 1
本页右侧下载列表为 Safetensors 格式,工作流包含在 Training data 压缩包内
本页右侧的下载列表为 Safetensors 格式,工作流包含在 Training data 压缩包内。示例图片和视频中也包含工作流(是的,你可以直接将原始视频文件导入 ComfyUI 并尝试捕获工作流)
5/15 Aiwood 的 WAN-ACE 全功能工作流已上传
5/15 ComfyUI KJ-WanVideoWrapper 已更新
5/14 autoregressive_checkpoint.pt 1.3b 已上传,PT UNET 加载器
5/14 bidirectional_checkpoint2.pt 1.3b 已上传,PT UNET 加载器
新采样器 Flowmatch_causvid 来自 KJ-WanVideoWrapper
发布来源:
⭐ 点个 star ⭐
[WAN1.2 LoRAs] 对 VACE 的适配测试结果表明,约 75% 的 I2V/T2V LoRA 权重可生效,但敏感性降低(尝试提高 LoRA 权重至 100% 以上,有时会更有效)
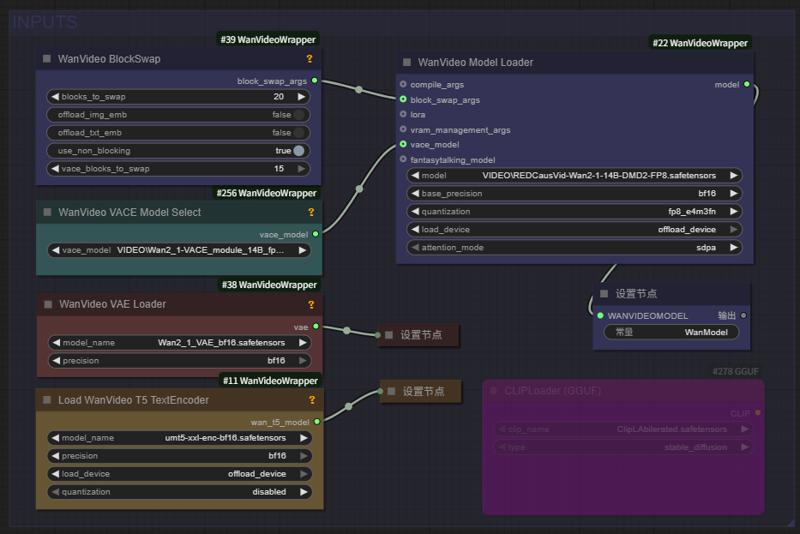
Aiwood WAN-ACE 全功能工作流完整视图:

来源:https://www.bilibili.com/video/BV1FGE6zGEDK ⭐ 点个 star ⭐
 CausVid 加速器项目页 https://causvid.github.io/
CausVid 加速器项目页 https://causvid.github.io/
WAN-VACE 模型参数与配置如下:
📌 Wan2.1-VACE 提供多种任务解决方案,包括参考到视频生成(R2V)、视频到视频编辑(V2V)和掩码视频到视频编辑(MV2V),允许创作者自由组合功能实现复杂任务。
👉 多模态输入增强视频生成的可控性。
👉 统一单一模型,实现跨任务的一致性方案。
👉 自由组合功能,释放更深层创造力
📌 Wan2.1-VACE为各种任务提供解决方案,包括参考视频生成(R2V)、视频到视频编辑(V2V)和屏蔽视频到视频剪辑(MV2V),允许创作者自由组合这些功能来实现复杂的任务。
👉 多模态输入增强了视频生成的可控性。
👉 统一的单一模型,实现跨任务的一致解决方案。
👉 自由组合功能,释放更深层次的创造力
WAN实时生成来了**!Hybrid** AI 模型数秒内生成流畅高清视频
CausVid 生成式 AI 工具使用扩散模型,教导自回归(逐帧)系统快速生成稳定、高分辨率视频。
基于 Wan2.1 的混合 AI 模型在数秒内(9帧/秒)生成流畅、高质量视频
CausVid 生成式 AI 工具使用扩散模型来指导自回归(逐帧)系统快速生成稳定的高分辨率视频。
从慢速双向到快速自回归视频扩散模型
CausVid https://causvid.github.io/
tianweiy (Tianwei Yin)
RedCaus/REDCausVid**-Wan2-1**-14B-DMD2-FP8 上传 / WAN-VACE14B 最佳适配
CausVid**/autoregressive_checkpoint** 已收录 / 自回归模型基于 WAN1.3B
CausVid**/bidirectional_checkpoint2** 已收录 / 双向推导模型基于 WAN1.3B
Kijai/Wan2_1-T2V-14B_CausVid_fp8_e4m3fn.safetensors / HF 仓库 WanVideo_comfy
⭐ 点个 star ⭐

授权:知识共享署名-非商业性使用 4.0
感谢这位朋友的补充评论。我昨晚太兴奋没睡,更新到一半就停了:
我们需要使用官方基于 Python 的推理代码:
克隆 https://github.com/tianweiy/CausVid 并按说明安装依赖
将 https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B 克隆至 wan_models/Wan2.1-T2V-1.3B
将 pt 文件放入 checkpoint_folder/model.pt
运行推理代码:python minimal_inference/autoregressive_inference.py --config_path configs/wan_causal_dmd.yaml --checkpoint_folder XXX --output_folder XXX --prompt_file_path XXX
关于 CausVid 的 Reddit 帖子:https://www.reddit.com/r/StableDiffusion/comments/1khjy4o/causvid_generate_videos_in_seconds_not_minutes/
https://www.reddit.com/r/StableDiffusion/comments/1k0gxer/causvid_from_slow_bidirectional_to_fast/
我们已测试基于 Wan1.3b 的 CausVid,其速度惊人,目前正测试由 lightx2v 生成的 14B 版本。
 LightX2V:轻量视频生成推理框架
LightX2V:轻量视频生成推理框架
支持模型列表
如何运行
请参阅 lightx2v 的 文档。
⭐ 点个 star ⭐
通义实验室 WAN 2.1 模型库
智能计算研究院专注于各领域大模型技术研发与创新应用,研究方向覆盖自然语言处理、多模态、视觉AIGC、语音等多个领域,并积极推动研究成果产业化落地。我们同时积极参与开源社区建设,全面拥抱开源,共同探索AI模型的开放与共享。
开发者/ 模型名称 / Kijai 的 ComfyUI 模型
RedCaus/REDCausVid**-Wan2-1**-14B-DMD2-FP8 上传 / WAN-VACE14B 最佳适配
CausVid**/autoregressive_checkpoint** 已收录 / 自回归模型基于 WAN1.3B
CausVid**/bidirectional_checkpoint2** 已收录 / 双向推导模型基于 WAN1.3B
CausVid**/wan_causal_ode_checkpoint_model** 测试中 / 自回归因果推导 测试中
CausVid**/wan_i2v_causal_ode_checkpoint_model** 测试中 / 图生视频模型 测试中
lightx2v**/Wan2.1-T2V-14B-CausVid** 不达标 / 自回归模型14B AiWood实测不达标
lightx2v**/Wan2.1-T2V-14B-CausVid quant** 不达标 / 自回归模型14B量化版 实测不达标
Wan Team**/1.3B 文本到视频** 已收录 / 文生视频1.3B
Wan Team**/14B 文本到视频** 已收录 / 文生视频14B
Wan Team**/14B 图像到视频 480P** 已收录 / 图生视频14B
Wan Team**/14B 图像到视频 720P** 已收录 / 图生视频14B
Wan Team**/14B 首尾帧到视频 720P** 已收录 / 视频首尾帧
Wan Team**/Wan2_1_VAE** 已收录 / Kijai 的 WAN视频VAE
ComfyORG**/Wan2.1_VAE** 已收录 / Comfy 的 WAN视频VAE
google/umt5-xxl umt5-xxl-enc safetensors 已收录 / TE编码器
mlf/open-clip-xlm-roberta-large-vit-huge-14 safetensors 已收录 / CLIP编码器
DiffSynth-Studio Team/1.3B 美学 LoRA 美学蒸馏-通义万相2.1-1.3B-LoRA-v1
DiffSynth-Studio Team/1.3B 高分辨率修复 LoRA 高分辨率修复-通义万相2.1-1.3B-LoRA-v1
DiffSynth-Studio Team/1.3B ExVideo LoRA 长度扩展-通义万相2.1-1.3B-LoRA-v1
DiffSynth-Studio Team/1.3B 速度控制 适配器 速度控制-通义万相2.1-1.3B-适配器-v1
PAI Team/ WAN2.1 Fun 1.3B InP 支持首尾帧 / Kijai/WanVideo_comfy
PAI Team/ WAN2.1 Fun 14B InP 支持首尾帧 / Kijai/WanVideo_comfy
PAI Team/ WAN2.1 Fun 1.3B 控制器 / Kijai/WanVideo_comfy
PAI Team/ WAN2.1 Fun 14B 控制器 / Kijai/WanVideo_comfy
PAI Team/ WAN2.1 Fun 14B 控制器 / Kijai/WanVideo_comfy
PAI Team/ WAN2.1-Fun-V1_1-14B-Control-Camera / Kijai/WanVideo_comfy
IIC Team/ VACE-通义万相2.1-1.3B-Preview / Kijai/WanVideo_comfy
IC(上下文)控制器 多模态控制器:
ali-vilab/ VACE:一体化视频创作与编辑 / Kijai/WanVideo_comfy
Phantom-video/Phantom 跨模态对齐实现主体一致性
KwaiVGI/ ReCamMaster 摄像头控制多角度镜头 / Kijai/WanVideo_comfy
通过 Wan2.1 实现的数字角色:
ali-vilab/ UniAnimate-DiT 长序列骨骼角色视频 / Kijai/WanVideo_comfy
Fantasy-AMAP/ 音频驱动数字人 FantasyTalking / Kijai/WanVideo_comfy
Fantasy-AMAP/ 角色一致性身份保留 FantasyID / Fantasy-AMAP/fantasy-id
无限制 NSFW 解锁版本:
REDCraft AIGC / WAN2.1 720P NSFW 解锁版 / 仅供私人使用【非公开】
CubeyAI / WAN General NSFW model (FIXED) / 最佳通用 LoRA
昆仑万维发布基于 Wan2.1 的 SkyReels
Skywork / SkyReels-V2-I2V-14B-720P / 图像到视频 / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-I2V-14B-540P / 图像到视频 / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-T2V-14B-540P / 文本到视频 / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-T2V-14B-720P / 文本到视频 / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-I2V-1.3B-540P / 图像到视频 / Kijai/WanVideo_comfy
自回归扩散强制-无限长度生成架构
Skywork / SkyReels-V2-DF-14B-720P / 文本到视频 / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-DF-14B-540P / 文本到视频 / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-DF-1.3B-540P / 文本到视频 / Kijai/WanVideo_comfy
昆仑万维发布 SkyReels 视频标注模型:
Skywork / SkyCaptioner-V1 Skywork (Skywork) / Skywork/SkyCaptioner-V1
微型 自动编码器 / taew2_1 safetensors / Kijai/WanVideo_comfy
一个用于将图像编码为潜在表示、并将潜在表示解码为图像的微型蒸馏VAE模型
WAN Comfy-Org/Wan_2.1_ComfyUI_repackaged
【示例页面蓝色Nodes或下载webp文件——可复现视频工作流】
画廊示例图像/视频(WEBP格式),包含ComfyUI原生工作流
这是一个简洁清晰的 GGUF 模型加载 与 分块采样 工作流:
Wan 2.1 Low vram Comfy UI Workflow (GGUF) 4gb Vram - v1.1 | Wan Video Workflows | Civitai
节点:(或使用 comfyui manager 安装自定义节点)
https://github.com/city96/ComfyUI-GGUF
https://github.com/kijai/ComfyUI-WanVideoWrapper
https://github.com/BlenderNeko/ComfyUI_TiledKSampler
* 注意需更新至最新版本的 comfyui-KJNodes GitHub - kijai/ComfyUI-KJNodes: Various custom nodes for ComfyUI,更新至最新版本的 Comfyui KJNodes
Kijai 为 WanVideo 开发的 ComfyUI 封装节点
进行中
@kijaidesign 的作品
Huggingface - Kijai/WanVideo_comfy
GitHub - kijai/ComfyUI-WanVideoWrapper
主图视频来自 AiWood
https://www.bilibili.com/video/BV1TKP3eVEue
将 text encoders 放入 ComfyUI/models/text_encoders
将 Transformer 放入 ComfyUI/models/diffusion_models
将 Vae 放入 ComfyUI/models/vae
目前仅成功运行了 I2V 模型。
无法使帧数低于 81 的情况工作,此为 512x512x81
使用约16GB显存,20/40块被卸载
DiffSynth-Studio 推理 GUI
Wan-Video LoRA 及微调训练
DiffSynth-Studio/examples/wanvideo at main · modelscope/DiffSynth-Studio · GitHub
![]()
💜 Wan | 🖥️ GitHub | 🤗 Hugging Face | 🤖 ModelScope | 📑 论文(即将发布) | 📑 博客 | 💬 微信社群 | 📖 Discord
通义万相Wan2.1视频模型开源!视频生成模型新标杆,支持中文字效+高质量视频生成
本仓库发布 Wan2.1,一套全面开放的视频基础模型,推动视频生成技术的边界。Wan2.1 具备以下核心特性:
👍 SOTA 性能:Wan2.1 在多个基准测试中持续超越现有开源模型及顶尖商业解决方案。
👍 支持消费级显卡:T2V-1.3B 模型仅需 8.19GB 显存,兼容几乎所有消费级 GPU。在 RTX 4090 上可约 4 分钟生成一段 5 秒 480P 视频(未使用量化等优化技术),其性能甚至可媲美部分闭源模型。
👍 多任务支持:Wan2.1 在文本到视频、图像到视频、视频编辑、文本到图像、视频到音频等多个任务中表现卓越,推动视频生成领域发展。
👍 视觉文本生成:Wan2.1 是首个能生成中文与英文文本的视频模型,具备强大的文字生成能力,显著提升实际应用价值。
👍 强大视频 VAE:Wan-VAE 实现卓越效率与性能,可编码与解码任意长度的 1080P 视频并保留时间信息,是视频与图像生成的理想基础。
本仓库包含我们的 T2V-14B 模型,该模型在开源与闭源模型中均建立了新的 SOTA 性能基准,展现出卓越的高质量视觉生成能力和显著运动动态。它也是唯一能同时生成中英文文本的视频模型,并支持 480P 与 720P 分辨率的视频生成。
