WAN 2.1 IMAGE to VIDEO with Caption and Postprocessing

세부 정보
파일 다운로드
이 버전에 대해
모델 설명
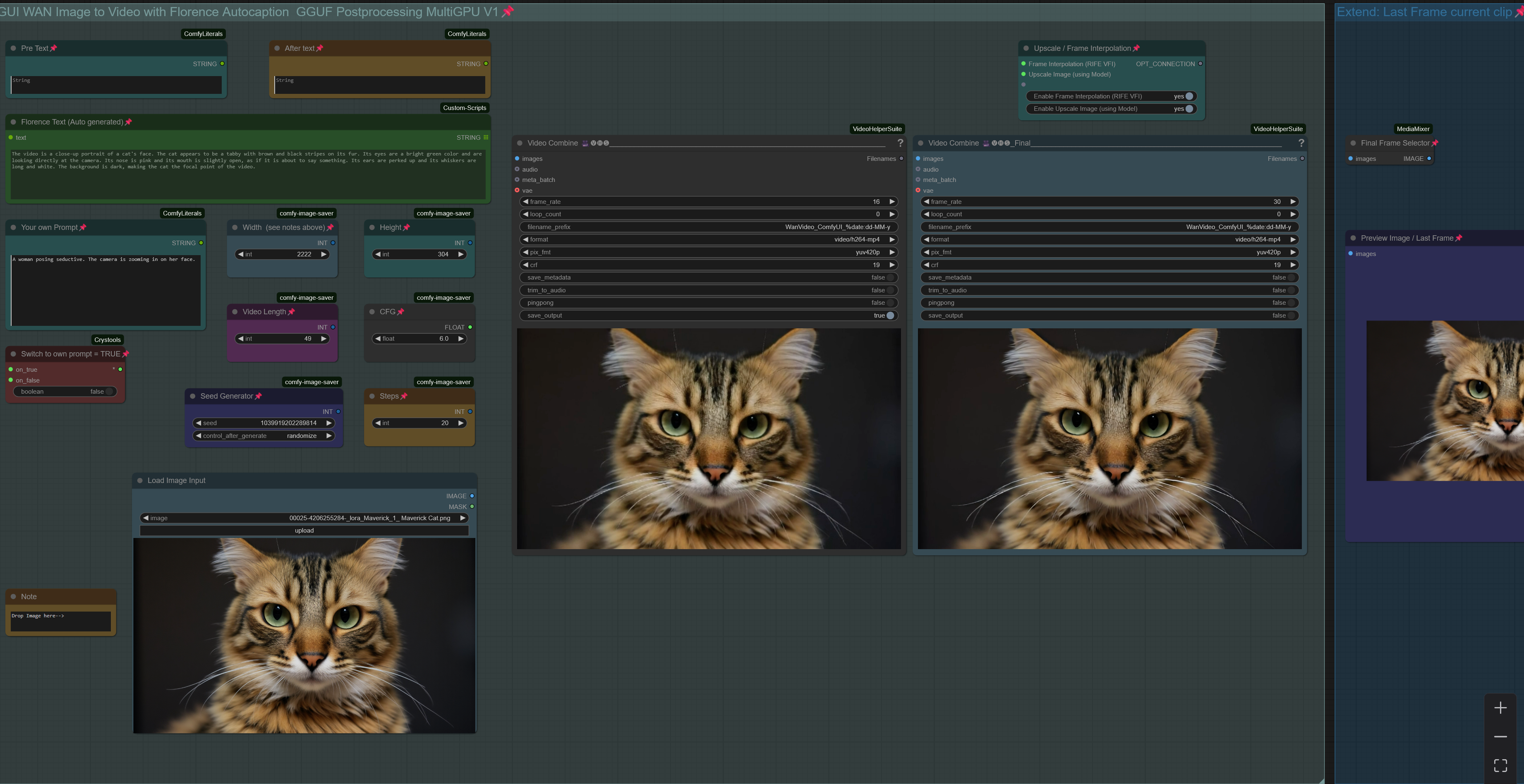
워크플로우: 이미지 -> 자동 캡션(프롬프트) -> WAN I2V (업스케일 및 프레임 보간 및 비디오 확장)
- 최대 480p 해상도의 비디오 클립 생성 (해당 모델 사용 시 720p)
Florence 캡션 버전과 LTX 프롬프트 향상기(LTXPE) 버전이 있습니다. LTXPE는 VRAM 사용량이 더 높으므로, 문제 발생 시 다음 스레드를 참고하세요: /model/1823416?dialog=commentThread&commentId=955337
MultiClip: Wan 2.1. I2V 버전 — Fusion X Lora를 지원하여 8단계로 클립 생성 및 최대 3배 확장 가능. 예시는 15~20초 길이의 클립으로 제공됨.
워크플로우는 입력 이미지에 클립을 생성하고 최대 3개의 클립/시퀀스로 확장합니다. 대부분의 경우 색상과 조명의 일관성을 유지하기 위해 컬러 매치 기능을 사용합니다. 전체 세부 정보는 워크플로우 내 설명을 참조하세요.
일반 버전은 사용자 지정 프롬프트를 사용할 수 있으며, LTXPE를 사용한 자동 프롬프트 버전도 제공됩니다. 일반 버전은 특정 또는 NSFW 클립과 Lora와 함께 잘 작동하며, LTXPE는 이미지를 드롭하고 너비/높이를 설정한 후 실행 버튼만 누르면 됩니다. 최종적으로 모든 클립이 하나의 완성된 비디오로 결합됩니다.
2025년 7월 16일 업데이트: 새로운 Lora "LightX2v"가 Fusion X Lora의 대안으로 출시되었습니다. 사용 방법은 블랙 "Lora Loader" 노드에서 Lora를 교체하세요. 이 Lora는 단지 4~6단계만으로 훌륭한 움직임을 생성할 수 있습니다.: https://huggingface.co/lightx2v/Wan2.1-I2V-14B-480P-StepDistill-CfgDistill-Lightx2v/tree/main/loras
더 많은 정보/팁 및 도움: /model/1309065/wan-21-image-to-video-with-caption-and-postprocessing?dialog=commentThread&commentId=869306
V3.1: Wan 2.1. I2V 버전 — Fusion X Lora를 지원하여 빠른 처리 가능
Fusion X Lora: 8단계(또는 그 이하, 워크플로우 설명 참조)만으로 비디오 처리. V3.0의 CausVid Lora와 같은 문제는 없으며, 색상 매치 보정이 필요하지 않습니다.
Fusion X Lora 다운로드: /model/1678575?modelVersionId=1900322 (i2V)
최고 품질을 원한다면 아래 V3.0 버전의 OSS를 확인하세요.
V3.0: Wan 2.1. I2V 버전 — 최적 단계 스케줄러(OSS) 및 CausVid Lora 지원
OSS는 품질을 높이면서 단계 수를 줄이는 새로운 comfy 코어 노드입니다. 50단계 이상을 사용하지 않고도 약 24단계로 동일한 결과를 얻을 수 있습니다. https://github.com/bebebe666/OptimalSteps
CausVid는 Lora를 사용해 8-10단계만으로 비디오를 처리하며, 속도는 빠르지만 품질은 낮습니다. Lora가 도입하는 과도한 채도를 보정하기 위해 후처리에 컬러 매치 옵션이 포함되어 있습니다. Lora 다운로드: https://huggingface.co/Kijai/WanVideo_comfy/tree/main
(Wan21_CausVid_14B_T2V_lora_rank32.safetensors)
두 버전 모두 Florence 또는 LTX 프롬프트 향상기(LTXPE)를 사용한 캡션 버전이 있으며, Lora를 사용할 수 있고 Teacache가 포함되어 있습니다.
V2.5: Wan 2.1. Lora 지원 및 스킵 레이어 가이던스(움직임 향상)를 가진 이미지에서 비디오로 변환
두 버전이 있습니다: 표준 버전(Teacache, Florence 캡션, 업스케일, 프레임 보간 등 포함)과 추가 캡션 도구로 LTX 프롬프트 향상기를 사용하는 버전(자세한 내용은 노트 참고, 맞춤 노드 필요: https://github.com/Lightricks/ComfyUI-LTXVideo).
Lora 사용 시, Lora 트리거 문구와 함께 사용자 지정 프롬프트로 전환하는 것이 좋습니다. 복잡한 프롬프트는 일부 Lora를 혼란스럽게 만들 수 있습니다.
V2.0: Wan 2.1. GGUF 모델을 위한 Teacache 지원 이미지에서 비디오로 변환 — 생성 속도를 30-40% 향상
첫 번째 단계는 일반 속도로 렌더링하고, 나머지 단계는 더 빠른 속도로 렌더링합니다. 복잡한 움직임의 경우 품질에 약간의 영향이 있습니다. Strg-B를 사용하여 Teacache 노드를 우회할 수 있습니다.
워크플로우가 포함된 예시 클립: https://civitai.com/posts/13777557
Teacache 관련 정보 및 도움: /model/1309065/wan-21-image-to-video-with-caption-and-postprocessing?dialog=commentThread&commentId=724665
V1.0: WAN 2.1. 이미지에서 비디오로 변환 — Florence 캡션 또는 사용자 지정 프롬프트, plus 업스케일, 프레임 보간, 클립 확장 기능 지원
워크플로우는 GGUF 모델을 사용하도록 설정되었습니다.
클립을 생성할 때 업스케일 및/또는 프레임 보간을 적용할 수 있습니다. 업스케일 배수는 사용한 업스케일 모델에 따라 달라집니다(2x 또는 4x, "load upscale model" 노드 참조). 프레임 보간은 모델 기본 프레임 속도인 16fps에서 32fps로 증가하도록 설정됩니다. 결과는 오른쪽의 "Video Combine Final" 노드에 표시되며, 왼쪽 노드에는 처리되지 않은 클립이 표시됩니다.
케이블을 숨기려면 "Toggle Link visibility"를 추천합니다.
모델 다운로드 위치:
Wan 2.1. I2V (480p): https://huggingface.co/city96/Wan2.1-I2V-14B-480P-gguf/tree/main
Clip (fp8): https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/text_encoders
Clip Vision: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/clip_vision
VAE: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/vae
Wan 2.1. I2V (720p): https://huggingface.co/city96/Wan2.1-I2V-14B-720P-gguf/tree/main
Wan2.1. 텍스트에서 비디오로 변환(작동함): https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
이 파일들을 ComfyUI 폴더 내에 저장할 위치:
Wan GGUF 모델 -> models/unet
Textencoder -> models/clip
Clipvision -> models/clip_vision
Vae -> models/vae
팁:
"Video combine Final" 노드의 프레임 속도를 30에서 24로 낮추면 슬로우 모션 효과를 얻을 수 있습니다.
텍스트에서 비디오로 변환하는 GGUF 모델도 사용할 수 있습니다.
프레임 오른쪽 끝에 이상한 아티팩트가 나타나면, "Define Width and Height" 노드의 "divisible_by" 매개변수를 8에서 16로 변경해 보세요. 이는 표준 Wan 해상도와 더 잘 맞춰 아티팩트를 방지할 수 있습니다.
오디오가 포함된 전체 비디오 예시: