Swin2SR Upscaler (x2 and x4)


详情
下载文件
模型描述
这是一系列我训练的Swin2SR超分辨率模型,基于我生成的高分辨率图像,旨在增强皮肤纹理而非将其平滑化,尤其适用于写实风格和数字艺术风格。我已在ComfyUI中测试过这些模型,它们应兼容Auto1111及其他支持Swin2SR的工具。
https://github.com/mv-lab/swin2sr
版本
共有三个模型,均提供 .safetensors 和 .pth 两种格式。
custom x2
- 使用我生成的图像,从零开始训练25,000步,批次大小为16
custom x4
使用我生成的图像,从零开始训练28,000步,批次大小为16
并非由x2模型微调而来
DIV2K + custom x2
基于SwinIR仓库中的DIV2K数据集,从零开始训练10,000步
随后在自己生成的图像上额外训练40,000步
x2模型可应用两次(达到x4倍)而质量损失极小,也可应用三次(达到x8倍)但会出现轻微模糊;x4模型可应用两次(达到x16倍)时模糊会较明显。
质量
与各自GitHub页面发布的BSRGAN、SwinIR和Swin2SR模型相比,这些模型的PSNR表现良好。我测试过的最佳超分模型是基于Lexica图像训练的SwinIR x2模型:https://openmodeldb.info/models/2x-LexicaSwinIR,其得分仍优于我的模型。然而,我的模型在测试图案的角落区域产生的伪影更少。我未来希望进一步改进这些模型,并将尝试使用64的补丁尺寸。
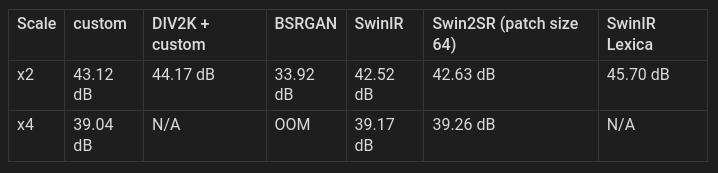
45dB的PSNR大致相当于以90%质量保存JPEG图像:https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio
据我理解,如果你取一张原始图像,保存一份为90%质量的JPEG,再将另一份缩放到50%大小后用custom x2模型放大,两者的质量损失应大致相当。
大多数测试使用256的切块尺寸进行,唯独BSRGAN除外。BSRGAN的测试脚本不支持切块,且在x4测试中因图像过大而内存溢出。Real ESRGAN未提供测试脚本,但我若能找到将一并纳入。
对比
测试图案来自维基媒体:https://commons.wikimedia.org/wiki/File:Philips_PM5544.svg
Custom x2:

DIV2K + Custom x2:

Lexica x2:

训练
所有模型均采用Swin2SR架构,补丁尺寸为48。训练数据集由约520张高分辨率图像组成,均由我使用Flux.1 Dev和ComfyUI中的hires流程生成。低分辨率图像通过双三次插值生成。
custom模型在RunPod集群上训练,配备2块A40 GPU(总计96GB显存),批次大小为16。DIV2K + custom模型在A6000(48GB显存)上训练,批次大小为8。