WAN 2.2 IMAGE to VIDEO with Caption and Postprocessing

详情
下载文件
关于此版本
模型描述
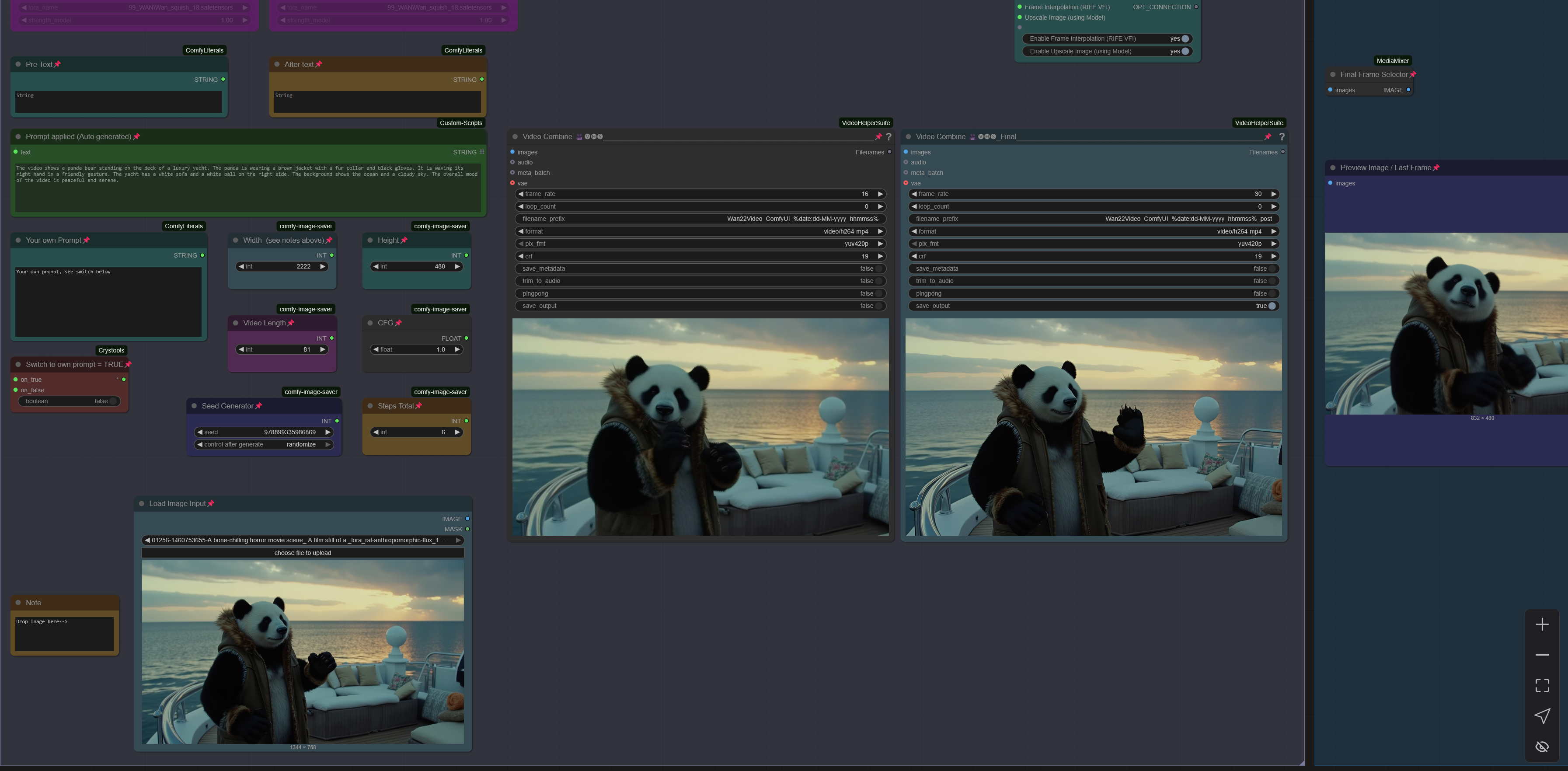
工作流:图像 -> 自动字幕(提示)-> WAN I2V,带超分辨率、帧插值和视频扩展
- 生成分辨率为 480p 或 720p 的视频片段。
提供 Florence 字幕版本和 LTX 提示增强器(LTXPE)版本。LTXPE 对 VRAM 要求更高,如遇问题请参阅此帖子:/model/1823416?dialog=commentThread&commentId=955337
MultiClip LTXPE PLUS:基于以下 MultiClip 工作流的 Wan 2.2. 14B I2V 版本,改进了 LTX 提示增强器(LTXPE)功能(见工作流中的说明)。建议您先尝试下方的 MultiClip 工作流。
该工作流增强了 LTXPE 功能,以更精细地控制提示生成,使用了无审查语言模型,视频生成部分与下方版本相同。更多信息:/model/1823416?modelVersionId=2303138&dialog=commentThread&commentId=972440
MultiClip:Wan 2.2. 14B I2V 版本,支持 LightX2V Wan 2.2. Loras,可创建 4-6 步的片段,并扩展至原长度的 3 倍,参见发布示例(长度约 15-20 秒)。
提供普通版(允许使用自定义提示)和LTXPE 版(自动提示)。普通版适用于特定或 NSFW 片段与 Loras 的组合,而 LTXPE 版只需上传图像、设置宽高并点击运行即可。最终所有片段将合并为一个完整视频。
支持新的 Wan 2.2. LightX2v Loras,适用于低步数
此外,您可注入“旧版”LightX2v Wan 2.1 Lora,有助于避免慢动作片段并引入更动态的运动(可能在新版 LightX Lora(如 ver.1022)中已过时)。
支持按序列使用 Wan 2.2. Loras
包含单片段版本,对应下方 V1.0 工作流,并额外增加了用于“旧版”Wan 2.1. LightX2v Lora 的 Lora 加载器。
由于 Wan 2.2 使用两个模型,工作流较为复杂。仍建议您查看 Wan 2.1 MultiClip 版本,它更轻量且拥有丰富的 Lora 选择。地址:/model/1309065?modelVersionId=1998473
V1.0 WAN 2.2. 14B 图像转视频工作流,支持 LightX2v I2V Wan 2.2 Lora,适用于低步数(4-8 步)
Wan 2.2. 使用两个模型按顺序处理片段:高噪声模型和低噪声模型。
兼容 LightX2v Loras,可实现低步数快速处理片段。
兼容部分“旧版”Wan2.1 Loras 和“新版”Wan 2.2. Loras
请参阅工作流中的说明及下方提示。
模型可在此下载:
模型(需同时下载高噪声与低噪声模型,根据您的 VRAM 选择匹配版本):https://huggingface.co/bullerwins/Wan2.2-I2V-A14B-GGUF/tree/main
Wan 2.2. 的 LightX2v Loras(I2v,高与低):https://huggingface.co/Kijai/WanVideo_comfy/tree/main/LoRAs/Wan22-Lightning/old
2025 年 10 月 14 日:发布两个新的 LightX 高噪声 Lora(MoE 和 1030),建议使用强度 > 1.5、7 步、SD3 shift = 5.0,替换高噪声 Lora:
https://huggingface.co/Kijai/WanVideo_comfy/tree/main/LoRAs/Wan22_Lightx2v
2025 年 10 月 22 日:发布另一款 LightX Lora(命名为 1022),推荐使用:
https://huggingface.co/lightx2v/Wan2.2-Distill-Loras/tree/main
LightX2v Lora(旧版 Wan 2.1):https://huggingface.co/lightx2v/Wan2.1-I2V-14B-480P-StepDistill-CfgDistill-Lightx2v/tree/main/loras
VAE(与 Wan 2.1 相同):https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/vae
Textencoder(与 Wan 2.1 相同):https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/text_encoders
WAN 2.2. I2V 5B 模型(GGUF)工作流,支持 Florence 或 LTXPE 自动字幕
质量低于 14B 模型
720p @ 24 帧
使用 FastWan Lora 时,设置 CFG 为 1,步数为 4-5,将 LoraLoader 节点置于 Unet Loader 之后以注入 Lora
FastWan Lora:https://huggingface.co/Kijai/WanVideo_comfy/tree/main/FastWan
模型(GGUF,根据您的 VRAM 选择匹配版本):https://huggingface.co/QuantStack/Wan2.2-TI2V-5B-GGUF/tree/main
VAE:https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/vae
Textencoder(与 Wan 2.1 相同):https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/text_encoders
在您的 ComfyUI 文件夹中保存这些文件的位置:
Wan GGUF 模型 -> models/unet
Textencoder -> models/clip
VAE -> models/vae
提示(适用于 14B 模型):
对 Wan 2.2 和 Loras 感到困惑?请查看此帖子:/model/1823416?modelVersionId=2063446&dialog=commentThread&commentId=890870
Wan 2.2. I2V 提示技巧:/model/1823416?modelVersionId=2063446&dialog=commentThread&commentId=890880
应下载哪个 GGUF 模型?我通常在 16GB VRAM / 64GB RAM 的配置下选择约 10GB 大小的模型(例如:“...Q4_K_M.gguf”模型)
LTXPE 使用的无审查模型:“chuanli11/Llama-3.2-3B-Instruct-uncensored”。请在 LTXPE Loader 节点中替换 LLM_name
调整 LightX Lora 强度(约 1.5)以增强运动效果、减少慢动作