JBOOGX & MACHINE LEARNER ANIMATEDIFF WORKFLOW - Vid2Vid + ControlNet + Latent Upscale + Upscale ControlNet Pass + Multi Image IPAdapter + ReActor Face Swap

详情
下载文件
关于此版本
模型描述
欢迎使用 JBOOGX & 机器学习 ANIMATEDIFF 工作流!
完整 YouTube 工作流教程:
1/8 更新
为低分辨率和放大器添加了 ReActor 人脸替换功能。使用 rgthree 节点包添加了旁路/启用切换开关。
12/7 更新
关于此版本
v2 版本带来了一些便捷性改进和更新。
我已将所有 ControlNets 分别归入独立组,方便您轻松旁路不需要使用的节点。
在 IPAdapter 中,请下载以下文件并放置到您的 comfyui\clip_vision 目录下。此文件用于“LOAD Clip Vision”节点。
https://drive.google.com/file/d/13KXx6u9JpHnWdemhqswRQJhVqThEE-7q/view?usp=sharing
您可以在以下地址找到适用于“LOAD IPAdapter Model”节点的 IPAdapter Plus 1.5 模型:
https://github.com/cubiq/ComfyUI_IPAdapter_plus
如果您不需要放大,请旁路右下角所有放大组。
差不多就是这些了 :)
请在您使用本工作流创作的作品中提及我,我会在社交媒体上分享!
Instagram:@jboogx.creative
免责声明:此工作流不适合初学者。如果您是初学者,请从以下链接的 @Inner_Reflections_Ai 的 vid2vid 工作流开始:
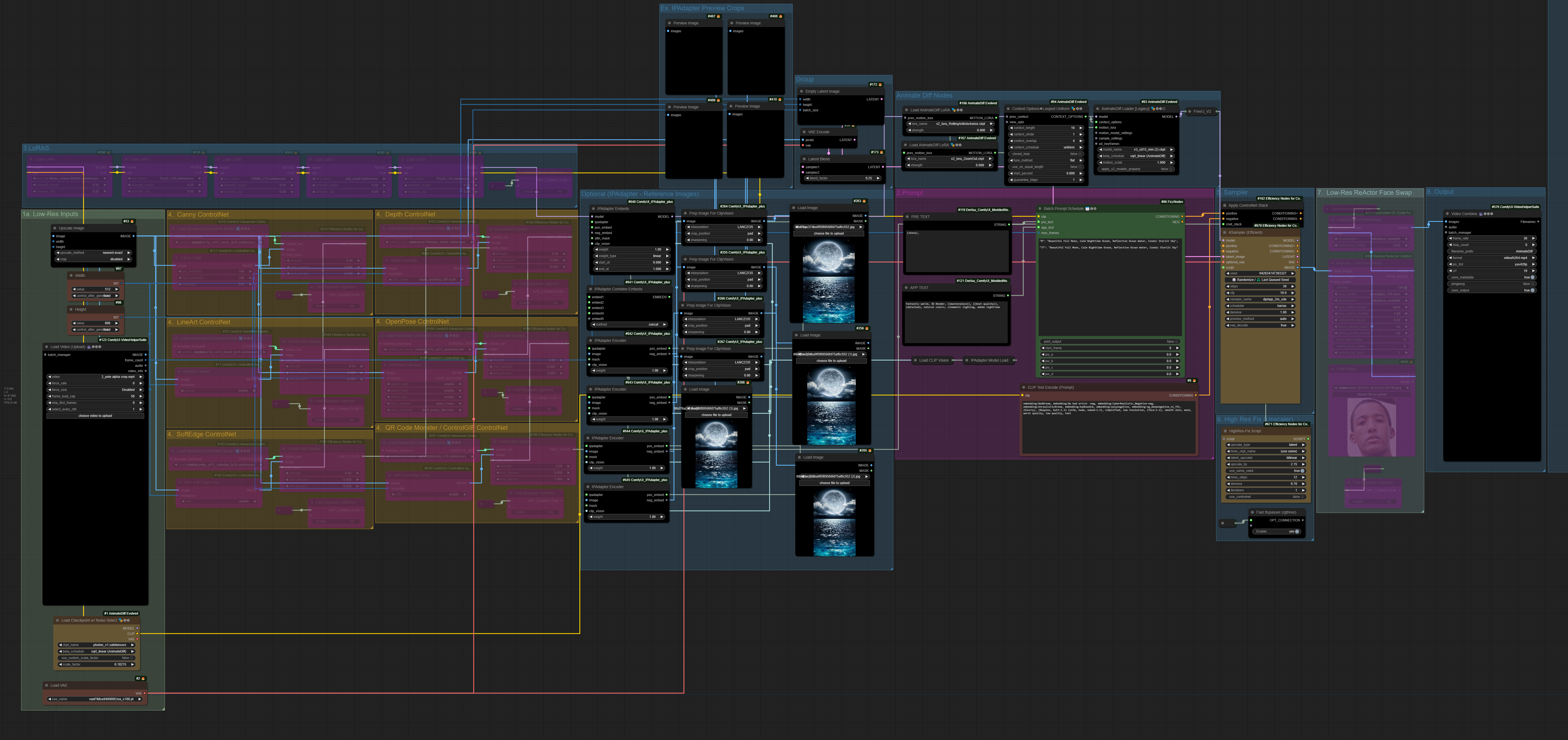
应众多请求,我决定公开分享我在直播中使用的这个工作流。它能够实现以下功能:
Vid2Vid + ControlNets - 不使用时请旁路这些节点,并根据需要添加任何 ControlNet 及预处理器。内置的是我常用的组合。
隐空间放大 - 测试时若不进行放大,请务必旁路所有放大组及隐空间放大视频合并节点。
隐空间放大期间的第二轮 ControlNet 传递 - 最佳实践是使用与第一轮相同的 ControlNets,并保持相同的强度与权重。
多图像 IPAdapter 集成 - 请勿旁路这些节点,否则会导致流程中断。在最下方每个 IPAdapter 图像节点中插入一张图像;若不使用 IPAdapter 作为风格或图像参考,只需将强度和权重调至零即可将其关闭。
二维码幻觉渲染 - 实现此效果,请使用黑白 Alpha 通道作为输入视频,并仅使用“QR Code Monster”作为 ControlNet。
本工作流基于 @Inner_Reflections_AI 在 Civitai 文章中发布的原始 Vid2Vid 工作流构建。以下才华横溢的艺术家(其 Instagram 账号)帮助我完善了本工作流的各个部分,使其达到当前水平:
@lightnlense
@pxl.pshr
@machine.delusions
@automatagraphics
@dotsimulate
没有他们的帮助,我无法获得如此多的视频创作乐趣。我并非技术最精通的人,因此非常欢迎社区成员提供任何建议或优化改进(这正是我决定公开分享它的原因)。
可能需要下载一些节点,所有节点均可通过 Comfy 管理器获取(我认为)。您可以根据当前项目需要,自由旁路任意数量的 LoRAs、ControlNets 和放大器。具备中高级节点使用知识将有助于您在开关节点时排查错误。若您是纯新手,我建议从 @Inner_Reflections_AI 的基础 Vid2Vid 工作流开始,因为这正是我最初理解 ComfyUI 的唯一途径。
压缩包中包含一个工作流 .json 文件和一张 png 文件,您只需将其拖入 ComfyUI 工作区即可加载全部内容。请准备好通过 ComfyUI 管理器下载大量节点。
如有任何问题或困难,我非常乐意在有空时为您提供帮助 🙂
如果您用此工作流创作了精彩作品,欢迎在 Instagram 上标记我,我会分享您的创作!如果您从中获得任何价值,也请关注我,感谢您对我的 Vision Weaver GPT 的支持!如果您使用并喜欢它?请留下好评并点个星标!
@jboogx.creative