bigASP 🐍





















Details
Download Files
About this version
Model description
bigASP 🐍 v2.0
A photorealistic SDXL finetuned from base SDXL on over 6 MILLION high quality photos for 40 million training samples. Every photo was captioned using JoyCaption and tagged using JoyTag. This imbues bigASP 🐍 with the ability to understand a wide range of prompts and concepts, from short and simple to long and detailed, while generating high quality photographic results.
This is now the second version of bigASP 🐍. I'm excited to see how the community uses this model and to learn its strengths and weaknesses. Please share your gens and feedback!
Features
Both Natural Language and Tag based prompting: Version 2 now understands not only booru-style tags, but also natural language prompts, or any combination of the two!
SFW and NSFW: This version of bigASP 🐍 includes 2M SFW images and 4M NSFW images. Dress to impress? Or undress to impress? You decide.
Diversity: bigASP 🐍 is trained on an intentionally diverse dataset, so that it can handle generating all the colors of our beautiful species, in all shapes and sizes. Goodbye same-face!
Aspect ratio bucketing: Widescreen, square, portrait, bigASP 🐍 is ready to take it all.
High quality training data: Most of the training data consists of high quality, professional grade photos with resolutions well beyond SDXL's native resolution, all downloaded in their original quality with no additional compression. bigASP 🐍 won't miss a single pixel.
Large prompt support: Trained with support for up to 225 tokens in the prompt. It is BIG asp, after all.
(Optional) Aesthetic/quality score: Like version 1, this model understands quality scores to help improve generations, e.g. add
score_7_up, to the start of your prompt to guide the quality of generations. More details below.
What's New (Version 2)
Added natural language prompting, greatly expanding the ability to control the model, resolve a lot of complaints about v1, and lots, lots more concepts can now be understood by the model.
Over 3X more images. 6.7M images in version 2 versus 1.5M in version 1.
SFW support. I added 2M SFW images to the dataset, both so bigASP can be more useful as well as expanding its range of understanding. In my testing so far, bigASP is excellent at nature photography.
Longer training. Version 1 felt a bit undertrained. Version 2 was trained for 40M samples versus 30M in version 1. This seems to have tighten up the model quite a bit.
Score tags are now optional! They were randomly dropped during training, so the model will work just fine even when they aren't specified.
Updated quality model. I updated the model used to score the images, both to improve it slightly and to handle the new range of data. In my experience the range of "good" images is now much broader, starting from score_5. So you can be much more relaxed in what scores you prompt for and hopefully get even more variety in outputs than before.
More male focused data. It may come as a surprise to many, but nearly 50% of the world population is male! Kinda weird to have them so underrepresented in our models! Version 2 has added a good chunk more images focused on the male form. There's more work to be done here, but it's better than v1.
Recommended Settings
Sampler: DPM++ 2M SDE or DPM++ 3M SDE
Schedule: Kerras or Exponential. ⚠️ WARNING ⚠️ Normal schedule will cause garbage outputs.
Steps: 40
CFG: 2.0 or 3.0
Perturbed Attention Guidance (available in at least ComfyUI), can help sometimes so I recommend giving it a try. It is especially helpful for faces and more complex scenes. However it can easily overcook an image, so turn down CFG when using PAG.
⚠️ WARNING ⚠️ If you're coming from Version 1, this version has much lower recommended CFG settings.
Supported resolutions (with image count for reference):
832x1216: 2229287
1216x832: 2179902
832x1152: 762149
1152x896: 430643
896x1152: 198820
1344x768: 185089
768x1344: 145989
1024x1024: 102374
1152x832: 70110
1280x768: 58728
768x1280: 42345
896x1088: 40613
1344x704: 31708
704x1344: 31163
704x1472: 27365
960x1088: 26303
1088x896: 24592
1472x704: 17991
960x1024: 17886
1088x960: 17229
1536x640: 16485
1024x960: 15745
704x1408: 14188
1408x704: 12204
1600x640: 4835
1728x576: 4718
1664x576: 2999
640x1536: 1827
640x1600: 635
576x1664: 456
576x1728: 335
Prompting
bigASP 🐍, as of version 2, was trained to support both detailed natural language prompts and booru-tag prompting. That means all of these kinds of prompting styles work:
A photograph of a cute puppy running through a field of flowers with the sun shining brightly in the background. Captured with depth of field to enhance the focus on the subject.
Photo of a cute puppy, running through a field of flowers, bright sun in background, depth of field
photo (medium), cute puppy, running, field of flowers, bright sun, sun in background, depth_of_field
If you've used bigASP v1 in the past, all of those tags should still work! But now you can add natural language to help describe what you want in more words than just tags.
If you need some ideas for how to write prompts that bigASP understands well, try running some of your favorite images through JoyCaption: https://huggingface.co/spaces/fancyfeast/joy-caption-alpha-two bigASP v2 was trained using JoyCaption (Alpha Two) to generate short, medium, long, etc descriptive captions, so any of those JoyCaption settings will work well to help you out.
I also recommend checking out the metadata for any of the images in the gallery to get some ideas. I always upload my images with the ComfyUI workflow when possible.
Finally, scoring. bigASP 🐍 v2, like v1 and inspired by the incredible work of PonyDiffusion, was trained with "score tags". This means it understands things like score_8_up, which specify the quality of the image you want generated. All images in bigASP's dataset were scored from 0 to 9, with 0 completely excluded from training, and 9 being the best of the best. So when you write something like score_7_up at the beginning of your prompt, you're telling bigASP "I want an image that's at least a quality of 7."
Unlike v1, this version of bigASP does not require specifying a score tag in your prompt. If you don't, bigASP is free to generate across its wide range of qualities, so expect both good and bad! But I highly recommend putting a score tag of some kind at the beginning of your prompt, to help guide the model. I usually just use score_7_up, which guides towards generally good quality, while still giving bigASP some freedom. If you want only the best, score_9. If you want more variety, score_5_up. Hopefully that makes sense! You can specify multiple score tags if you want, but one is usually enough. And you can put lower scores in the negative to see if that helps. Something like score_1, score_2, score_3.
NOTE: If you use a score tag, it must be at the beginning of the prompt.
NOTE: If you want booru style tags in your prompt, don't forget that some tags use parenthesis, for example photo (medium). And many UI's use parenthesis for prompt weighting! So don't forget to escape the parenthesis if you're using something like ComfyUI or Auto1111, i.e. photo \(medium\).
Example prompts
SFW, chill sunset over a calm lake with a distant mountain range, soft clouds, and a lone sailboat.
score_7_up, Photo of a woman with blonde hair, red lipstick, and a black necklace, sitting on a bed, masturbating, watermark
score_8, A vibrant photo of a tropical beach scene, taken on a bright sunny day. The foreground features a wooden railing and lush green grass, with a large, twisted palm tree in the center-right. The background showcases a sandy beach with turquoise waters and a clear blue sky. The palm tree has long, spiky leaves that contrast with the smooth, curved trunk. The overall scene is peaceful and inviting, with a sense of warmth and relaxation.
score_8_up, A captivating and surreal photograph of a cafe with neon lights shining down on a handsome man standing behind the counter. The man is wearing an apron and smiling warmly at the camera. The lighting is warm and glowing, with soft shadows adding depth and detail to the man. Highly detailed skin textures, muscular, cup of coffee, medium wide shot, taken with a Canon EOS.
score_7_up, photo \(medium\), 1girl, spread legs, small breasts, puffy nipples, cumshot, shocked
score_7_up, photo (medium), long hair, standing, thighhighs, reddit, 1girl, r/asstastic, kitchen, dark skin
score_8_up, photo \(medium\), black shirt, pussy, long hair, spread legs, thighhighs, miniskirt, outside
Photo of a blue 1960s Mercedes-Benz car, close-up, headlight, chrome accents, Arabic text on license plate, low quality
Prompting (Advanced)
Like version 1, this version of bigASP understands all of the tags that JoyTag uses. Some might find it useful to reference this list of tags seen during v2's training, including the number of times that tag occurs: https://gist.github.com/fpgaminer/0243de0d232a90dcae5e2f47d844f9bb
Of course, version 2 now understands more natural prompting, thanks to JoyCaption. That means there's a gold mine of new concepts that this version of bigASP 🐍 understands. Many people found the tag list from v1 to be helpful in exploring the model's capabilities. For natural language, a similar approach is to do "n-gram" analysis on the corpus of captions the model saw during training. Basically, this finds common combinations of "words". Here's that list, including the number of times each fragment of text occurs: https://gist.github.com/fpgaminer/26f4da885cc61bede13b3779b81ba300
The first column of the n-gram list is the number of "words" considered, from 1 up to 7. The second column is the text. The third column is the number of times that particular combination of words was seen (which might be higher than the number of images, since they can occur multiple times in a single caption). Note that "noun chunks" are counted as a single word in this analysis. Examples: "her right side", "his body", "water droplets". All of those are considered a single "word", since they represent a consolidated concept. So don't be surprised if the list above has "tattoo on her right side" listed as being 3 words. Also note that some punctuation might be missing from the extracted text fragments, due to the way the text was processed for this analysis.
Various sources can be mentioned, such as reddit, flickr, unsplash, instagram, etc. As well as specific subreddits (similar to v1).
Tags such as NSFW, SFW, and Suggestive, can help guide the content of the generations.
For the most part, bigASP 🐍 will not generate watermarks unless one is specifically mentioned. The trigger word is, coincidentally, watermark. Adding watermark to negatives might help avoid them even more, though in my testing they're quite rare for most prompts.
bigASP 🐍 can generate text that you specify using language like The person is holding a sign with the text "Happy Halloween" on it. You can prompt for text in various ways, but definitely put the text you want to appear on the image in quotes. That said, this is SDXL, so except to have to hammer a lot of gens to get good text. And the more complex the image, the less well SDXL will do with text. But it's a neat parlor trick for this old girl!
Some camera makes and models, as well as focal length, aperture, etc are understood by the model. Their effects are unknown. You can use a tag like DSLR to more generally guide the model towards "professional" photos, but beware that it will also tend to put a camera in the photo...
As mentioned in the list of features, bigASP 🐍 was trained with long prompt support. It was trained using the technique that NovelAI invented and documented graciously, and is the same technique that most generation UIs use when your prompt exceeds CLIP's maximum of 75 tokens. There's a good mix of caption lengths in the dataset, so any length from a few tokens up to 225 tokens should work well. With the usual caveats of this technique.
Limitations
No offset noise: Sorry, maybe next version.
No anime: This is a photo model through and through. Perhaps in a future version anime will be included to expand the model's concepts.
Faces/hands/feet: You know the deal.
VAE issues: SDXL's VAE sucks. We all know it. But nowhere is it more apparent than in photos. And because bigASP generates such high levels of detail, it really exposes the weaknesses of the VAE. Not much I can do about that.
No miracles: This is SDXL, so expect the usual. 1:24 ratio of good to meh gens, a good amount of body horror, etc. Some prompts will work well for no reason. Some will produce nightmares no matter how you tweak the prompt. Multiple characters is better in this version of bigASP compared to v1, but is still rough. Such is the way of these older architectures. I think bigASP is more or less at the limit of what can be done here now.
Training Details (Version 2)
All the nitty gritty of getting version 2 trained are documented here: https://civitai.com/articles/8423
Training Details (Version 1)
Details on how the big SDXL finetunes were trained is scarce to say the least. So, I'm sharing all my details here to help the community.
bigASP was trained on about 1,440,000 photos, all with resolutions larger than their respective aspect ratio bucket. Each image is about 1MB on disk, making the database about 1TB per million images.
Every image goes through: the quality model to rate it from 0 to 9; JoyTag to tag it; OWLv2 with the prompt "a watermark" to detect watermarks in the images. I found OWLv2 to perform better than even a finetuned vision model, and it has the added benefit of providing bounding boxes for the watermarks. Accuracy is about 92%. While it wasn't done for this version, it's possible in the future that the bounding boxes could be used to do "loss masking" during training, which basically hides the watermarks from SD. For now, if a watermark is detect, a "watermark" tag is included in the training prompt.
Images with a score of 0 are dropped entirely. I did a lot of work specifically training the scoring model to put certain images down in this score bracket. You'd be surprised at how much junk comes through in datasets, and even a hint of them and really throw off training. Thumbnails, video preview images, ads, etc.
bigASP uses the same aspect ratios buckets that SDXL's paper defines. All images are bucketed into the bucket they best fit in while not being smaller than any dimension of that bucket when scaled down. So after scaling, images get randomly cropped. The original resolution and crop data is recorded alongside the VAE encoded image on disk for conditioning SDXL, and finally the latent is gzipped. I found gzip to provide a nice 30% space savings. This reduces the training dataset down to about 100GB per million images.
Training was done using a custom training script based off the diffusers library. I used a custom training script so that I could fully understand all the inner mechanics and implement any tweaks I wanted. Plus I had my training scripts from SD1.5 training, so it wasn't a huge leap. The downside is that a lot of time had to be spent debugging subtle issues that cropped up after several bugged runs. Those are all expensive mistakes. But, for me, mistakes are the cost of learning.
I think the training prompts are really important to the performance of the final model in actual usage. The custom Dataset class is responsible for doing a lot of heavy lifting when it comes to generating the training prompts. People prompt with everything from short prompts to long prompts, to prompts with all kinds of commas, underscores, typos, etc.
I pulled a large sample of AI images that included prompts to analyze the statistics of typical user prompts. The distribution of prompts followed a mostly normal distribution, with a mean of 32 tags and a std of 19.8. So my Dataset class reflects this. For every training sample, it picks a random integer in this distribution to determine how many tags it should use for this training sample. It shuffles the tags on the image and then truncates them to that number.
This means that during training the model sees everything from just "1girl" to a huge 224 token prompt! And thus, hopefully, learns to fill in the details for the user.
Certain tags, like watermark, are given priority and always included if present, so the model learns those tags strongly.
The tag alias list from danbooru is used to randomly mutate tags to synonyms so that bigASP understands all the different ways people might refer to a concept. Hopefully.
And, of course, the score tags. Just like Pony XL, bigASP encodes the score of a training sample as a range of tags of the form "score_X" and "score_X_up". However, to avoid the issues Pony XL ran into, only a random number of score tags are included in the training prompt. That way the model doesn't require "score_8, score_7, score_6," etc in the prompt to work correctly. It's already used to just a single, or a couple score tags being present.
10% of the time the prompt is dropped completely, being set to an empty string. UCG, you know the deal. N.B.!!! I noticed in Stability's training scripts, and even HuggingFace's scripts, that instead of setting the prompt to an empty string, they set it to "zero" in the embedded space. This is different from how SD1.5 was trained. And it's different from how most of the SD front-ends do inference on SD. My theory is that it can actually be a big problem if SDXL is trained with "zero" dropping instead of empty prompt dropping. That means that during inference, if you use an empty prompt, you're telling the model to move away not from the "average image", but away from only images that happened to have no caption during training. That doesn't sound right. So for bigASP I opt to train with empty prompt dropping.
Additionally, Stability's training scripts include dropping of SDXL's other conditionings: original_size, crop, and target_size. I didn't see this behavior present in kohyaa's scripts, so I didn't use it. I'm not entirely sure what benefit it would provide.
I made sure that during training, the model gets a variety of batched prompt lengths. What I mean is, the prompts themselves for each training sample are certainly different lengths, but they all have to be padded to the longest example in a batch. So it's important to ensure that the model still sees a variety of lengths even after batching, otherwise it might overfit and only work on a specific range of prompt lengths. A quick Python Notebook to scan the training batches helped to verify a good distribution: 25% of batches were 225 tokens, 66% were 150, and 9% were 75 tokens. Though in future runs I might try to balance this more.
The rest of the training process is fairly standard. I found min-snr loss to work best in my experiments. Pure fp16 training did not work for me, so I had to resort to mixed precision with the model in fp32. Since the latents are already encoded, the VAE doesn't need to be loaded, saving precious memory. For generating sample images during training, I use a separate machine which grabs the saved checkpoints and generates the sample images. Again, that saves memory and compute on the training machine.
The final run uses an effective batch size of 2048, no EMA, no offset noise, PyTorch's AMP with just float16 (not bfloat16), 1e-4 learning rate, AdamW, min-snr loss, 0.1 weight decay, cosine annealing with linear warmup for 100,000 training samples, 10% UCG rate, text encoder 1 training is enabled, text encoded 2 is kept frozen, min_snr_gamma=5, PyTorch GradScaler with an initial scaling of 65k, 0.9 beta1, 0.999 beta2, 1e-8 eps. Everything is initialized from SDXL 1.0.
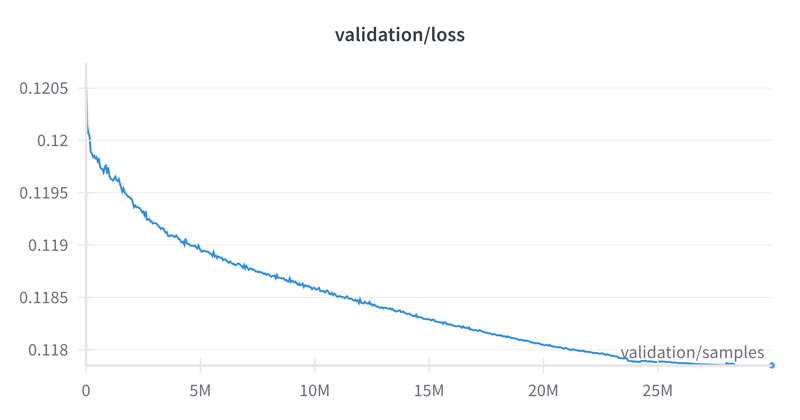
A validation dataset of 2048 images is used. Validation is performed every 50,000 samples to ensure that the model is not overfitting and to help guide hyperparameter selection. To help compare runs with different loss functions, validation is always performed with the basic loss function, even if training is using e.g. min-snr. And a checkpoint is saved every 500,000 samples. I find that it's really only helpful to look at sample images every million steps, so that process is run on every other checkpoint.
A stable training loss is also logged (I use Wandb to monitor my runs). Stable training loss is calculated at the same time as validation loss (one after the other). It's basically like a validation pass, except instead of using the validation dataset, it uses the first 2048 images from the training dataset, and uses a fixed seed. This provides a, well, stable training loss. SD's training loss is incredibly noisy, so this metric provides a much better gauge of how training loss is progressing.
The batch size I use is quite large compared to the few values I've seen online for finetuning runs. But it's informed by my experience with training other models. Large batch size wins in the long run, but is worse in the short run, so its efficacy can be challenging to measure on small scale benchmarks. Hopefully it was a win here. Full runs on SDXL are far too expensive for much experimentation here. But one immediate benefit of a large batch size is that iteration speed is faster, since optimization and gradient sync happens less frequently.
Training was done on an 8xH100 sxm5 machine rented in the cloud. On this machine, iteration speed is about 70 images/s. That means the whole run took about 5 solid days of computing. A staggering number for a hobbyist like me. Please send hugs. I hurt.
Training being done in the cloud was a big motivator for the use of precomputed latents. Takes me about an hour to get the data over to the machine to begin training. Theoretically the code could be set up to start training immediately, as the training data is streamed in for the first pass. It takes even the 8xH100 four hours to work through a million images, so data can be streamed faster than it's training. That way the machine isn't sitting idle burning money.
One disadvantage of precomputed latents is, of course, the lack of regularization from varying the latents between epochs. The model still sees a very large variety of prompts between epochs, but it won't see different crops of images or variations in VAE sampling. In future runs what I might do is have my local GPUs re-encoding the latents constantly and streaming those updated latents to the cloud machine. That way the latents change every few epochs. I didn't detect any overfitting on this run, so it might not be a big deal either way.
Finally, the loss curve. I noticed a rather large variance in the validation loss between different datasets, so it'll be hard for others to compare, but for what it's worth: