SanaeXL anime V1.0





















詳細
ファイルをダウンロード
モデル説明
SanaeXL アニメ V1.0
「苗来認める!苗来許す!苗来、SDXL全体を背負う!!!」
"SDXLを再び偉大に!!!"

モデル紹介 / Model Introduction
これはKXL eps rev3を基に改良された画像生成モデルで、1枚のNVIDIA 4090 GPUを使用して約780万枚の画像でトレーニングされました。人物の肢体表現が大幅に改善され、より正確な人体構造(特に指、足、趾)の生成が容易になり、複数人物の画像生成も安定しています。二人が抱き合うような動作もより自然に再現できます。また、芸術スタイルも多様化し、Novel AI V3のようにアーティストタグを使って好みのスタイルを生成可能で、より多くのアニメキャラクターを生成できます。
これはKXL eps rev3を基に改良された画像生成モデルで、1枚のNVIDIA 4090 GPUを使用して約780万枚の画像でトレーニングされました。人物の肢体表現が大幅に改善され、より正確な人体構造(特に指、足、趾)の生成が容易になり、複数人物の画像生成も安定しています。二人が抱き合うような動作もより自然に再現できます。また、芸術スタイルも多様化し、Novel AI V3のようにアーティストタグを使って好みのスタイルを生成可能で、より多くのアニメキャラクターを生成できます。
バージョン说明 \ Version Notes:
V1.3: V1.3はV1.2に加えて240万枚の画像を追加トレーニングしました。今回の更新では、starry128.txtに記載された芸術スタイルに焦点を当てています。starry128.txtは厳選されたアーティストリスト(詳細は下記参照)です。トレーニングにより、starry128に含まれる芸術スタイルが大幅に改善・最適化されました。ユーザーには、starry128.txtドキュメント(ダウンロードリンクを提供)をダウンロードし、ワイルドカードとして使用することを強く推奨します。これにより、今回の更新による芸術スタイルの改善を最大限に活用できます。画像のアノテーションにはflo2とWD(自然言語+タグ)を使用しているため、プロンプトは自然言語とタグを混合して使用可能です。
V1.3: Version 1.3 builds upon v1.2 with an additional 2.4 million images used for training. This update focuses on enhancing the artistic styles listed in starry128.txt, a carefully curated list of artists (see details below). Through targeted training, the artistic styles in starry128 have been significantly improved and refined. We strongly recommend users download the starry128.txt document (download link provided) and use it as a wildcard to fully leverage the artistic style improvements brought by this update. Image annotations use flo2 and WD (natural language + tags), so prompts support a combination of natural language and tags.
v1.2: v1.2はv1.1に加えて220万枚の画像を追加トレーニングしたバージョンで、原神や絶区零など、より多くのキャラクターを追加しました。
v1.2: 1.2 is an enhanced iteration built upon v1.1, incorporating an additional 2.2 million images for training. This update introduces a wider range of characters, including those from popular franchises such as Genshin Impact and Zenless Zone Zero.
v1.1:v1.1はv1.0に加えて140万枚の画像を追加トレーニングしたバージョンで、さらに多くのアーティストを追加しました。また、足の生成、特に足裏の表現を特別に最適化しました。複数人物の生成がうまくいかない原因はcomicスタイルの影響であることが判明しました。ネガティブプロンプトにcomicとmultiple viewsのタグを高重みで追加することで(例:(comic:1.8),(multiple views:1.4))、複数人物の構図エラーを効果的に改善できます。
v1.1:1.1 is an improved version built upon v1.0, with an additional 1.4 million images used for training and an expanded range of artists. Furthermore, v1.1 specifically optimizes foot generation, especially the appearance of soles. We also discovered that the poor performance in multi-person scenes was due to comic-style influences. Adding high-weight tags for 'comic' and 'multiple views' in the negative prompt, such as (comic:1.8),(multiple views:1.4), can effectively improve composition errors when generating multi-person scenes.
v1.0:v1.0は初期リリースバージョンで、約780万枚の画像でトレーニングされました。
v1.0:1.0 is our initial release, trained on approximately 7.8 million images.


推奨設定 / Recommended settings(please use DTG!!!)
プロンプト:
<1girl/1boy/1other/...>,
<キャラクター>, <シリーズ>, <アーティスト>,
<一般タグ>,
masterpiece,best quality,absurdres,highres,sensitive,newest,
ネガティブプロンプト(短):
lowres,low quality, worst quality, normal quality, text, signature, jpeg artifacts, bad anatomy, old, early, multiple views, copyright name, watermark, artist name, signature
ネガティブプロンプト(長):
lowres,bad anatomy,blurry,(worst quality:1.8),low quality,hands bad,(normal quality:1.3),bad hands,mutated hands and fingers,extra legs,extra arms,duplicate,cropped,jpeg,artifacts,blurry,multiple view,reference sheet,long body,multiple breasts,mutated,bad anatomy,disfigured,bad proportions,bad feet,ugly,text font ui,missing limb,monochrome,bad anatomy,blurry,(worst quality:1.8),low quality,hands bad,face bad,(normal quality:1.3),bad hands,mutated hands and fingers,extra legs,extra arms,duplicate,cropped,jpeg,artifacts,blurry,multiple view,long body,multiple breasts,mutated,disfigured,bad proportions,duplicate,bad feet,ugly,missing limb,
サムプラ:Euler A
ステップ:30
CFG:5~9
アップスケーラー:Latent
Hiresステップ:25
デノイジング強度:0.6
ネガティブプロンプトには必ずlowresを含めてください(大量の低解像度画像でトレーニングしたため)。worst qualityとlow qualityは必要に応じて追加可能です。また、例画像に示されている長いネガティブプロンプトを使用することもできます。これは内部メンバーがテスト時に使用したものです。非常に「ごちゃごちゃ」していますが、効果は明確ではありません。「ただ動く」からです。
Negative prompts must include: lowres (due to the use of a large number of low-resolution images for training). "worst quality" and "low quality" can be added based on personal preference. You can also use the negative prompts (long) shown in the example images. This string of prompts was used by internal members during testing. It is quite "shitty", and we cannot confirm its effectiveness, but "it just works."
例えば、東風谷早苗の画像を生成するには、以下のプロンプトを使用できます(改行は必須ではありません):
For example, to generate an image of Sanae Kochiya, you can use the following prompt (line breaks are optional):
1girl,
kochiya sanae, touhou
ask \(askzy\),
solo,green hair, green eyes,
masterpiece,best quality, absurdres,newest,safe,highres
DTG(Danbooru Tag Generator)
Stable Diffusionモデルでキャラクター画像を生成する際、トレーニングデータと方法の特性により、キャラクター名とその特徴タグ(tag)を同時に提供するのが最適です。キャラクター名だけを指定すると、髪の色や目の色などの細部が不正確になる可能性があり、特にキャラクターの特徴が複雑な場合に顕著です。しかし、一般ユーザーがすべての必要な特徴タグを手動で補完するのは容易ではありません。
When using Stable Diffusion models to generate character images, due to the characteristics of the training data and methods, it is best to provide the character's name along with their feature tags. If only the character's name is provided without feature tags, details such as hair color and eye color generated by the model may be inaccurate, especially when the character's features are more complex. However, for ordinary users, it is not easy to supplement and complete all the necessary feature tags.
この問題を解決するため、AUTOMATIC1111のWebUIで使用可能なプラグイン「DTG(Danbooru Tag Generator)」の利用を強く推奨します。DTGは本質的に言語モデル(LLM)であり、入力されたキャラクター名に基づいてプロンプトを自動拡張し、キャラクターの特徴タグや詳細な記述を補完します。DTGを使用することで、SanaeXLのような高品質モデルの性能を最大限に引き出すことができます。
DTGリンク:https://github.com/KohakuBlueleaf/z-a1111-sd-webui-dtg
To solve this problem, we strongly recommend using DTG (Danbooru Tag Generator), which is a plugin that can be used on AUTOMATIC1111's WebUI. DTG is essentially a language model (LLM) that can automatically expand prompts based on the input character name, supplementing the character's feature tags and more detailed descriptions. Using DTG can better leverage the performance of high-quality models like SanaeXL.
DTG link: https://github.com/KohakuBlueleaf/z-a1111-sd-webui-dtg
プロンプトの構築には、以下の形式を推奨します:
We recommend using the following format to construct prompts:
"1girl/1boy + キャラクター名 + シリーズ名 + アクション/シーンの視点 + 品質ワード"
この形式で基本的なプロンプト情報を提供した後、残りの作業はDTGに自動で任せることができます。DTGは入力されたプロンプトに基づいて関連タグを追加生成し、AIモデルがより正確で具体的な画像を生成するのを支援します。
"1girl/1boy + character name + series name + action/scene perspective + quality words"After providing basic prompt information in this format, you can leave the rest of the work to DTG to complete automatically. DTG can generate additional relevant tags based on the given prompts, helping AI models generate more accurate and specific images.
NovelAI3内部でも同様のメカニズムが採用されている可能性があります。ユーザーが初期プロンプトを入力した後、NovelAI3はタグ生成器(tag generator)を接続してプロンプト情報を自動補完・拡張し、より効果的なガイドを実現していると考えられます。
We have reason to speculate that NovelAI3 internally may also use a similar mechanism. After the user provides the initial prompt, NovelAI3 may connect to a tag generator to automatically supplement and expand the prompt information, achieving better guidance effects.
この「プロンプト+DTG」の組み合わせにより、ユーザーは大量の複雑なタグを手動で追加する必要なく、より簡潔で効率的にAIが生成する画像の内容とスタイルを制御できるようになり、Stable Diffusionモデルによるキャラクター画像生成の利便性と正確性が大幅に向上します。
This "prompt + DTG" combination approach allows users to control the content and style of AI-generated images in a more concise and efficient manner, without the need to manually add a large number of complex tags, greatly improving the convenience and accuracy of using Stable Diffusion models for character image generation.
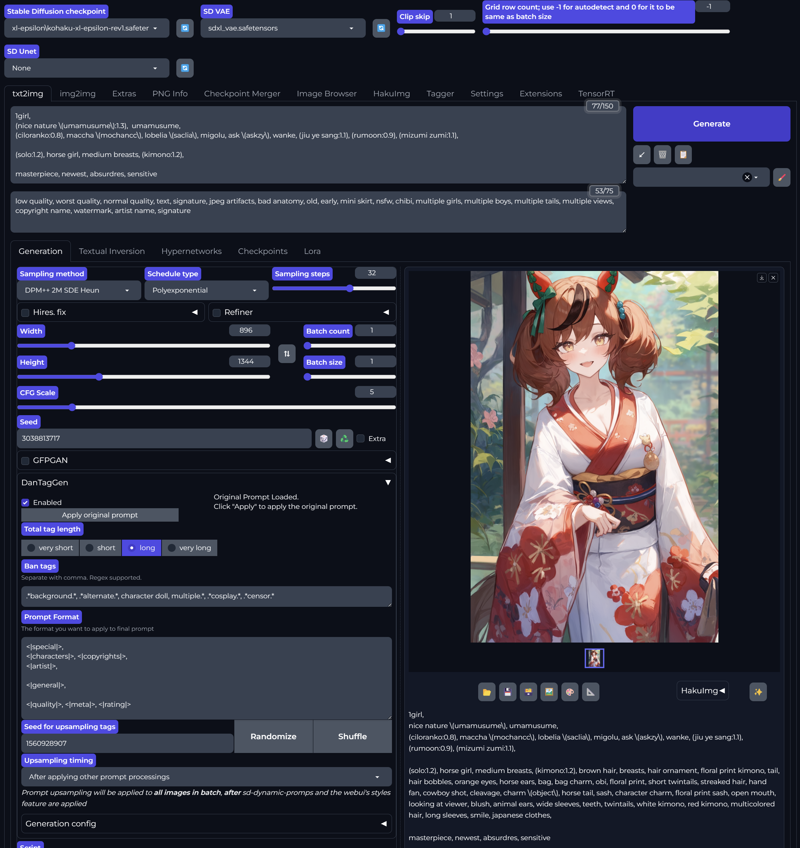
アーティストとキャラクターについて:
トレーニング画像の数が非常に多いため、両方のタグの効果も豊富で、特にDanbooru上で1000枚以上の画像を持つアーティストやキャラクターは、優れた結果を得られます。ただし、トレーニングデータは2024年2月までであるため、最近のキャラクターのサポートはやや弱いです。以下にアーティストとキャラクターの推奨ワイルドカードリンクを示します:
Because the number of training images is very large, both models have a large number of effective tags, especially artists and characters with over 1,000 images on Danbooru, which can achieve good results. It should be noted that the training set is up to February 2024, so the model's support for recent characters is not ideal. Below are links to recommended wildcards for artists and characters:
モデルのCCIP評価に基づき、優れたパフォーマンスを示すキャラクターの一覧を提供します。
このリストは、私たちの評価対象(3,711キャラクター)の中で顕著な成果を出した一部のキャラクターのみを含んでおり、すべてのキャラクターを網羅していません。
一部のマイナーなキャラクターについては、ご自身で効果をテストいただく必要があります。
私たちは厳格な評価基準を堅持しており、トレーニングデータに某キャラクターのデータを追加しただけで「モデルが対応する」と断定することはありません。
このような緩い基準を採用すれば、理論上このモデルはすべてのキャラクター(>12,000)に対応可能と主張できますが、それは明らかに無意味です。
Based on our CCIP evaluation of the model, we have provided a list of excellently performing roles for you to choose from.
Please note that this list only includes outstanding performers from within our evaluation scope (3711 roles) and does not cover all roles.
For some less common roles, you may need to test their effectiveness yourself.
We adhere to strict evaluation standards and will not claim that the model supports a role simply because related data for that role was added to the training dataset without proper evaluation.
If we were to adopt such a loose standard, our model could theoretically claim to support all roles (>12000), but this would obviously be meaningless.
character/sanaeXL_v1_character_ccip0.8.xlsx · SanaeLab/SanaeXL-anime-v1.0 at main (huggingface.co)
アーティストリストについては、現在の状況では大規模な評価は不可能です。
ただし、直接使用する場合、以下の2つのリストの使用を推奨します。これらはWebUIのワイルドカード機能で直接呼び出せます。
For the artist list, it is currently not possible to conduct large-scale evaluations.
However, for direct use, it is recommended to use these two lists, which can be directly utilized through the wildcard in the webui.
wildcards/starry_artists_v52_full.txt · SanaeLab/SanaeXL-anime-v1.0 at main (huggingface.co)
wildcards/starry_artists_v52_curated_128.txt · SanaeLab/SanaeXL-anime-v1.0 at main (huggingface.co)
注意:sanaeXLがサポートするタグは、上記リンクに記載されているものに限りません。
Note: The tags supported by sanaeXL are not limited to those mentioned in the links above.
タグについて / about tag
このモデルの使用法はKXL epsと同様で、プロンプト形式は以下の通りです:
The usage of this model is the same as KXL eps. The prompt format is as follows:
<1girl/1boy/1other/...>,
<キャラクター>, <シリーズ>, <アーティスト>,
<一般タグ>,
<品質タグ>, <年号タグ>, <メタタグ>, <レーティングタグ>
レーティングタグ
General: safe
Sensitive: sensitive
Questionable: nsfw
Explicit: nsfw, explicit
2005~2010: old
2011~2014: early
2015~2017: mid
2018~2020: recent
2021~2024: newest
解像度とサンプリング / Resolution and Sampling
1024×1024解像度で、WebUIの内蔵高解像度修復(Highres.fix)機能を使用すると、sanaeXLの性能をよりよく引き出せます。推奨される修復倍率は1.2倍~1.5倍です。
Using the built-in high-resolution fix (Highres.fix) feature of webui at 1024×1024 resolution can better leverage the performance of sanaeXL. The recommended fix ratio is between 1.2 and 1.5 times.
サンプリングに特別な要件はありません。出力結果が不満足な場合は、サンプリングステップ数とCFG値を適宜増加してください。
Euler Aを例に挙げると、サンプリングステップは20~30の範囲で問題ありません。ステップ数を増やすほど効果が向上します。CFGは7~12の範囲が推奨です。
There are no special requirements for samplers. If the output effect is not satisfactory, you can appropriately increase the number of sampling steps and the value of CFG.
Taking Euler A as an example, the number of sampling steps can be between 20-30. A higher number of steps will yield better results. The recommended CFG is between 7-12.
CCIPデータ
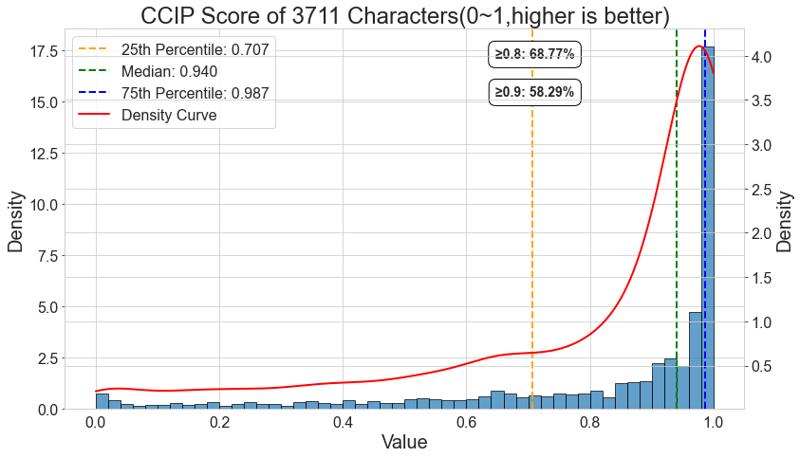
CCIPはキャラクターの適合度を効果的に評価するためのモデルです。個別にキャラクターをトレーニングしていないにもかかわらず、効果的なトレーニングにより、starryXLのような大規模な忘却は発生していません。実際、執筆時点ではCCIP評価で最優秀のモデルとなっています。3,711人のキャラクターで構成される評価セットのうち、68.77%のキャラクターが0.8を超えるCCIPスコアを獲得し、中央値は0.94です。この評価セットのほとんどすべてのキャラクターは、プロンプトの組み合わせだけで直接生成可能です。
CCIP is a model that can effectively evaluate character fitting. Although characters were not trained separately, thanks to effective training, the model did not suffer from catastrophic forgetting like starryXL. In fact, it has become the best-performing model in CCIP evaluation at the time of writing. 68.77% of characters obtained a CCIP score above 0.8, with a median of 0.94. In this evaluation set composed of 3,711 characters, the vast majority of characters can be directly generated through prompt combinations.
(この部分の詳細は、今後のトレーニングノートで詳しく記載します)
(Specific details about this part will be elaborated in future training notes.)
ノートリンク / note link:近日公開予定
sanaeXLについて
SanaeLab:https://huggingface.co/SanaeLab

本モデルは継続的に更新され、更新サイクルは概ね1週間から2週間です。
This model will be continuously updated, with an update cycle of approximately one week to half a month.
今後の更新計画の例:
● 2024年2月以降に登場したキャラクターを追加
● より多くのアーティストのスタイルを追加
● 手足の描写を改善
Future update plans include:
● Adding characters released after February 2024
● More artist styles
● Improved rendering of hands and feet

謝辞 / Acknowledgments:
KohakuBlueleaf氏がトレーニングしたベースモデルと、deepGHSのオープンソースデータセットに特別に感謝します。
Special thanks to the base model trained by KohakuBlueleaf and the open-source dataset from deepGHS.
Kohaku XL eps rev3 : https://huggingface.co/KBlueLeaf/Kohaku-XL-Epsilon-rev3
Kohaku XL delta : https://huggingface.co/KBlueLeaf/Kohaku-XL-Delta
deepGHS : https://huggingface.co/deepghs
モデル公開声明 | Model Release Statement
本モデルは以下のサイトでのみ正式に公開されています:
Hugging Face: [https://huggingface.co/SanaeLab/SanaeXL-anime-v1.0]
Civitai: [/model/647664/sanaexl-anime-v10]
重要なお知らせ:
上記プラットフォーム以外で公開された関連コンテンツは信頼できません。
無断での公開はSanaeLabとは一切関係ありません。
当方はこれらの無断公開について一切の責任を負わず、その内容の信頼性や安全性を保証できません。
This model is officially released only on the following websites:
Hugging Face: [https://huggingface.co/SanaeLab/SanaeXL-anime-v1.0]
Civitai: [/model/647664/sanaexl-anime-v10]
Important Notice:
Any related content published on platforms other than those mentioned above is not trustworthy.
Unauthorized publications are not associated with SanaeLab.
We are not responsible for these unauthorized publications and cannot guarantee their authenticity or safety.
ライセンス
このモデルは Fair-AI-Public-License-1.0-SD のもとで公開されています
詳細は以下のウェブサイトをご覧ください:
Freedom of Development (freedevproject.org)