Flux-dev2pro-fp8 special use for training Flux LoRA



세부 정보
파일 다운로드
모델 설명
이 모델은 재게시된 모델입니다.
저는 원래 제작자가 아닙니다.
경고: 이 모델은 일반적으로 LoRA 학습을 위한 기본 모델로만 사용되며, 이 모델의 이미지 생성 효과는 f1.d-fp8보다 뛰어나지 않습니다.
하지만 이 모델을 사용하여 이미지를 생성하고자 한다면, 여전히 작동합니다. 시도해보세요.
출처: Kijai/flux-dev2pro-fp8 · Hugging Face
또한 위 출처도 원래 제작자가 아닐 수 있으며, 아래는 fp16 버전입니다.
출처: ashen0209/Flux-Dev2Pro · Hugging Face
둘의 관계가 정확히 무엇인지 모르므로, 두 출처 모두를 게시합니다.
이 기본 모델의 원리와 효과는 다음과 같습니다: (또한 재게시됨)
출처: Why Flux LoRA So Hard to Train and How to Overcome It? | by John Shi | Aug, 2024 | Medium
왜 Flux LoRA 학습이 어려운가? 그리고 어떻게 극복할 수 있는가?
요약
- Flux-dev/schnell과 같은 디스틸레이션된 모델에서는 LoRA를 학습하지 마세요.
- 입력 가이던스=1.0으로 패인트uned된 모델에서 LoRA를 학습하세요.
- 아래 모델은 3백만 개의 고화질 데이터로 패인트uned한 모델입니다. 저 자신은 만족하지 못했지만, LoRA 학습 결과를 개선하는 데 도움이 됩니다. (패인트uned된 모델에 LoRA를 적용하지 말고, 디스틸레이션된 모델인 Flux-dev에 적용하세요.)
https://huggingface.co/ashen0209/Flux-Dev2Pro
LoRA 결과 예시:
https://huggingface.co/ashen0209/flux-lora-wlop

다른 모델에서 패인트uned된 LoRA가 동일한 학습/검증 환경에서 얻은 결과
배경
블랙포레스트랩이 최근 출시한 Flux 모델은 탁월한 텍스트 이해력과 상세한 이미지 품질로 인상적입니다. 현재 모든 오픈소스 모델을 크게 능가하며, 심지어 Midjourney v6와 같은 최고의 폐쇄형 모델과 비교해도 우위를 점합니다.

그러나 텍스트-이미지 모델 오픈소스 커뮤니티가 Flux를 패인트uned하려 할 때 많은 어려움이 나타났습니다. 저는 모델이 단시간 내에 완전히 붕괴하거나 열악한 패인트uned 결과를 내는 것을 발견했습니다. 왜곡된 인체 사지, 의미 이해력 저하, 흐릿하고 무의미한 이미지 등이 일반화되었습니다. SD1.5 또는 SDXL과 달리, Flux.1에서 패인트uned하거나 LoRA를 학습하는 것이 훨씬 어렵습니다. 여기서는 이러한 어려움의 잠재적 원인을 논의하고, 이를 극복할 수 있는 방법을 탐색하고자 합니다.
Flux-dev 디스틸레이션 이해
우선 Flux-dev가 어떻게 작동하는지 추측해 봅시다. SD 및 기타 많은 T2I 모델과 달리, Flux-dev는 CFG(분류기 자유 가이던스)에 부정 프롬프트를 사용하지 않습니다. 이 가이던스는 이미 모델에 디스틸레이션되어 있기 때문입니다. 학습 목표는 아마 다음과 같을 것입니다(개인적 추측이지만 매우 가능성 높음):

추측된 학습 과정
먼저 Flux-dev는 Flux-pro로 초기화되며, 각 학습 반복에서 가이던스가 무작위로 선택되고, 이 가이던스 스케일을 사용해 Flux-dev는 디노이징 결과를 예측합니다. 동시에 Flux-pro는 가이던스 임베딩 없이 디노이징 결과를 예측하며, 이는 분류기 자유 가이던스 방식, 즉 양/음성 예측을 동시에 해 가이던스_스케일로 조합하는 방식입니다. Flux-dev는 이 디스틸레이션 감독을 추가로 받으며, 플로우 매칭 손실과 함께 학습됩니다. 이 디스틸레이션 과정을 거친 후, Flux-dev 모델은 분류기 자유 가이던스 방식에 비해 계산 비용을 절반으로 줄이면서 유사한 품질을 유지할 수 있습니다.
Flux-schnell은 SDXL-turbo에서 소개된 적대적 디스틸레이션 방법으로 생성되었을 가능성이 있습니다. 그러나 학습이 더 어려우므로 여기서는 더 이상 논의하지 않겠습니다.
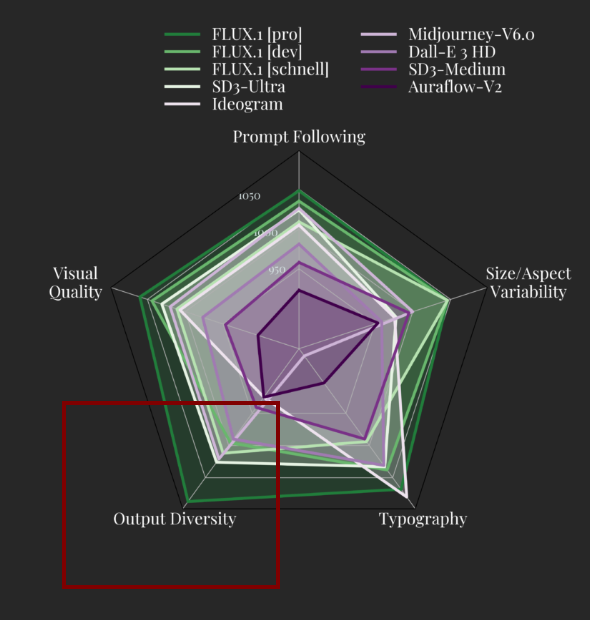
일부 기능이 pro 모델에서 "제거"되었을 가능성
또한 아직 알지 못하는 다른 세부 사항이 있을 수 있습니다. 예를 들어, Flux-dev와 Flux schnell의 출력 다양성 점수는 Flux-pro보다 훨씬 낮습니다. 이는 다른 기능이 "제거"되거나 감소되었음을 시사할 수 있습니다. 예를 들어, Flux-pro 교사 모델의 디스틸레이션 과정 중 인간 선호도를 위한 미세한 범위로 제한된 미학 입력 임베딩과 같은 다른 입력 조건이 존재했을 수 있으며, 이는 Flux-dev에는 존재하지 않습니다. 또는 dev 모델이 학습 세트의 훨씬 더 작은 하위 집합에 과적합되었을 가능성도 있습니다. 이러한 모든 추측은 가능성이 높지만, 현재로서는 진실이 불명확합니다.
왜 학습이 실패하는가
Flux의 디스틸레이션 과정을 이해한 후, Flux-dev 학습 실패의 핵심 원인은 CFG 가이던스 스케일임을 알 수 있습니다. Flux-pro의 디스틸레이션 없이 학습 과정에서 이 스케일을 어떻게 설정해야 할까요?
추론 단계에서 권장되는 3.5 이상의 합리적인 범위로 가이던스 스케일을 설정하면, 원래 학습 단계에서 사용된 값과 유사하여 좋은 접근법처럼 보일 수 있습니다. 그러나 Flux-pro의 CFG 결과가 제공하는 제약 없이 학습 역학이 크게 달라집니다. 가이던스 임베딩이 파괴되며, 가이던스 디스틸레이션이 더 이상 존재하지 않기 때문에, 학습 과정이 길어질수록 모델이 붕괴됩니다.
더 쉬운 방법은 학습 시 가이던스 스케일을 1.0으로 설정하는 것입니다. 이는 원래 학습 및 추론 단계에서 1.0의 가이던스 스케일을 사용하지 않기 때문에 직관에 어긋나 보일 수 있습니다. 하지만 이 방법이 좋은 이유는 두 가지입니다: (1) 가이던스=1.0일 때 디스틸레이션 손실이 최소화됩니다. 왜냐하면 cfg가 flux-pro에 영향을 주지 않기 때문이며, 이는 flux-dev를 근사하므로 교사 모델을 제거할 수 있기 때문입니다. (2) 디스틸레이션이 없는 학습 설정은 Flux-pro와 동일합니다. 그리고 Flux-pro 자체는 입력으로 가이던스 스케일 벡터를 받지 않으며, 기본값이 1.0입니다. 따라서 일반적으로 가이던스 스케일 1.0으로 모델을 학습한다는 것은 Flux-pro 모델을 복원하는 것입니다.
그러나 여전히 문제가 있습니다. 몇 장의 이미지와 얼마나 많은 계산 자원이 필요한지 아무도 모릅니다. 또한 가이던스 스케일 1.0은 원래 Flux-dev 디스틸레이션 학습 분포를 벗어난 값으로, 충분한 학습 단계 없이 학습하면 안정성이 부족할 가능성이 있습니다.
Flux를 잘 학습하는 방법
불행히도 쉬운 해결책은 없을 수 있습니다. 많은 LoRA 모델이 생성되었지만, 충분한 데이터셋과 학습 단계가 없으면 만족할 만한 결과를 얻기 어렵습니다. 좋은 모델을 생성하는 가장 신뢰할 수 있는 방법은 Flux-dev를 학습하여 Flux-pro를 복원한 후, 그 복원된 모델에서 LoRA를 패인트uned하는 것이지, Flux-dev에서 직접 LoRA를 학습하는 것이 아닙니다. 그렇지 않으면 가이던스 임베딩을 잃거나 열악한 결과를 얻을 위험이 있습니다.
이것은 3백만 개의 고화질 이미지로 2에포크 학습한 후 얻은 패인트uned된 모델 “Flux-dev2pro”입니다. https://huggingface.co/ashen0209/Flux-Dev2Pro
이 모델은 완벽하지 않으며 오히려 Flux-dev보다 나쁜 결과를 생성합니다. 그러나 몇 가지 개선점을 발견했습니다. 가이던스 입력을 1.0으로 설정한 경우 생성된 몇 가지 이미지를 살펴보겠습니다:

가이던스 입력을 1.0으로 설정하는 것은 추론에 일반적인 설정이 아니며, 원래 모델에서는 일반적으로 열악한 결과를 초래합니다. 그러나 이 설정에서는 원래 모델이 실패하는 동안 패인트uned된 모델이 더 나은 성능을 보여줍니다. 실제로 일반적인 추론 설정에서는 더 나쁜 성능을 보입니다. 왜냐하면 더 높은 가이던스 스케일로 디스틸레이션 학습이 부족하기 때문입니다. 그러나 이는 큰 문제가 아닙니다. 우리는 이 모델을 추론용이 아니라 학습용으로만 사용합니다(이전 섹션 참조) 그리고 이 설정으로 LoRA를 계속 학습함으로써 더 나은 결과를 얻을 수 있습니다.
여기는 제가 이 모델을 사용해 실험한 결과 중 일부입니다. 저는 두 가지 기반 모델, 즉 패인트uned된 “Flux-dev2pro”와 원래의 “Flux-dev”에 Wlop(유명한 아티스트) 스타일의 LoRA를 학습했습니다.
LoRA 링크: https://huggingface.co/ashen0209/flux-lora-wlop
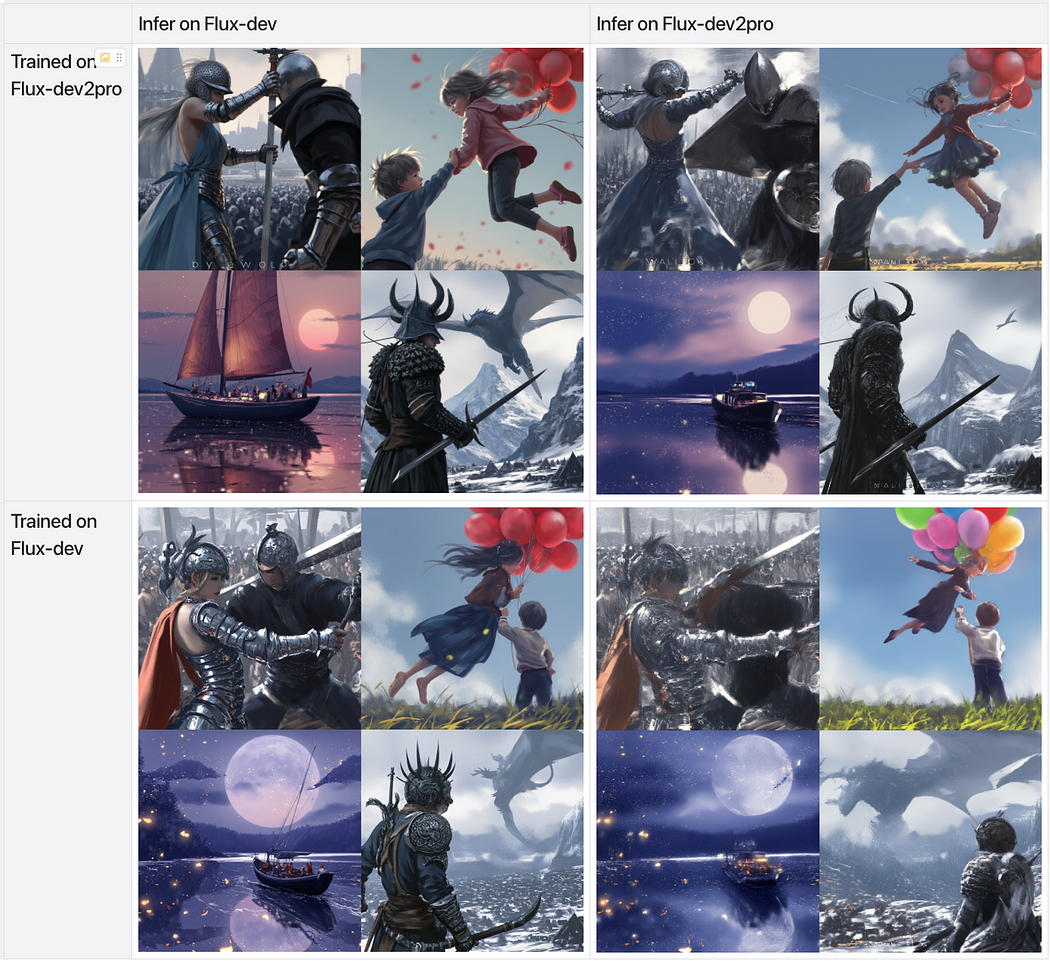
패인트uned된 모델에서 LoRA를 학습하고 원래 모델에서 추론할 때 가장 좋은 결과를 얻습니다.
예상대로, “Flux-dev2pro”에서 학습된 LoRA를 Flux-dev에 적용한 결과가 다른 것들보다 훨씬 뛰어났습니다. 이는 SDXL에서 LoRA를 학습하고 SDXL-turbo 또는 SDXL-lightning에 적용할 때 우수한 결과를 얻는 것과 유사합니다.
“Flux-dev2pro”에서 LoRA를 학습하고 Flux-dev에 적용한 초기 결과는 희망적이며 상당한 개선을 보여줍니다. 그러나 현재 버전의 “Flux-dev2pro”는 여전히 미완성입니다. 더 많은 정제가 가능하며, 지속적인 노력이나 커뮤니티의 기여를 통해 더 나은 모델이 등장할 것이라 확신합니다. 이러한 모델을 완성하는 여정은 어렵지만, 매 단계마다 잠재력을 완전히 발휘하는 데 더 가까워집니다. 이 분야가 어떻게 진화할지 기대되며, 앞으로의 혁신을 기다립니다.