Realistic 3D Style v1 [NOOB vPred V0.65S / ePred v1.1]




















详情
下载文件 (1)
关于此版本
模型描述
Update 1: GMT -7 1:51 pm 12/5/2024
I discovered a tagging fault; HUMAN ERROR DETECTED. I had auto-tagged the majority of the 3d and 3d artwork tags at the top of the image rather than the end of the image, which caused the outcome to be considerably weaker than anticipated.
The new suggested positive prompt is this
3d, 3d \(artwork\), realistic, artist1, artist2, artist3, ... artist99,noob tags here,
very aesthetic, aesthetic, masterpiece, highres, absurdres, newest, 3d, 3d (artwork), realistic,produces better results than the alternative in many resolutions, and the art styles pop more.
Clearly my process needs work, but that’s fine. We take what the universe gives.
Whyyyy so serious Batman?
This is highly successful as a style, even with none of the special depiction tags.
Suggested Configuration:
Strength:
0.8 ePred
0.92 vPred
Steps 50
Euler - SGM Uniform
CFG 5-6.5
1024x1024, 1216x1216, 1216x832, 832x1216
832x832, 768x768, 512x768, 768x512, 512x512
Positive Prompt:
3d, 3d (artwork), realistic,normal tags here,
masterpiece, highres, absurdres, newest, 3d, 3d (artwork), realistic,
Negative Prompt:
nsfw, worst quality, old, early, low quality, lowres, signature, username, logo, bad hands, mutated hands, mammal, anthro, furry, ambiguous form, feral, semi-anthro, bad anatomy, extra digitsRemove negatives or positive pieces to your hearts content.
Post burndown I noticed many high quality 3d images were tagged “disgusting” “displeasing” and “very displeasing”, so keep in mind you might get good results using those three, especially when using lower resolution images than 1024x1024.
This style lora will produce many artist styles and series styles. It enhances many characters and fixes the base costumes of some as a byproduct. It introduces some new characters but not with enough strength to matter, so don’t expect much from that.
This is particularly trained as a NUDGE lora. It’s meant to shift the model, but not destroy it. To condition and improve it without introducing any major new information.
This means including images from many styles and many artists; strengthening the core “3d”, “3d (artwork)”, and “realistic” tags; without entirely destroying them.
There are definitely some depth faults, where when you hit a complexity level high enough the overlapping and problems start to artifact, and this is likely due to the upscale and sharpen methodology I used when sourcing images with intentional interpolation.
The next will likely be a 100k image version ran at least 20 epochs, so be on the lookout in the coming weeks.
In the coming days I’ll be researching AI Refinement, image interpolation and motion AI technologies, as well designing a transitional-phase LORA that I call RE-LORA, which would be a burn-in refinement LORA concept; based entirely on imprinting conditioning and image refinement information at a much higher learn rate and less steps specifically targeting positions using a frozen model iterated at those positions, rather than destroying or altering core models, or waiting for entire full-end epochs.
It’s akin to a lora and akin to a text_encoder but it is neither of them. The goal here is to burn kind of, scars on the model to tell it where it’s own data is, using a compacted high dimensional storage tensor. It’s more akin to forcing img2img into it, sketch, or even enabling masked inpainting in already existing models without large training cycles and very minimal required image and mask data.
Unsorted Musings:
Looks like it works on ePred V1.1 as well, just a different measure of scale.
It works SURPRISINGLY good with ePred v1.1, but was trained using vPred v0.65S as the base model.
Seems to support 1300x1300 with additional upscaling if you use 2m SDE Heun. Comes out really really good.
Give it a try.
quarter-frame is not small enough, and it was far more effective than I thought it would be.
I’ll need to run identification again and this time make sure there’s an even smaller tag, something like small-frame for 1/9th of the image.
Epoch 30 has even better depiction control, with a higher fidelity in realism and 3d. Far superior to the epoch 20 and yet still incomplete.
For epoch 37 I’ll create a full image display roller and a bunch of use cases for the various taggings.
About 4000 images sliced from videos and 6000 images taken from the most recent r34xxx and r34us uploads.
Give or take 10k images, trained to 20 epochs at a batch size of 64 on 2 A100s.
The estimated training completion for epoch 37 is about 7 hours, so expect couple more uploads.
An experiment based on images sourced from animated gifs and videos in combination with sourced high resolution non ai generated images.
It has many 3d artists that are likely lesser represented, and many 3d artists that I’m sure are very popular.
Every image was identified to have at least one person.
I’m currently compounding a full list of artists. I honestly didn’t hand pick much, it’s pretty automated. Check the recent article for more details.
I’m inspired to train a full 100k image version of this.
I’ll capture each frame of each video, document interpolation normalization differences from frame to frame for sharpening, posterity, and utility; as well as a frame by frame tagging counter.
This will enable full interpolative video generation in a MUCH MUCH more stable manner.
For now, it’s just a stylized tinker toy with some depiction offset tags. Enjoy!
Depiction Tags:
depicted-upper-left
depicted-upper-center
depicted-upper-right
depicted-middle-left
depicted-middle-center
depicted-middle-right
depicted-lower-left
depicted-lower-center
depicted-lower-right
Scale Tags:
full-frame
half-frame
quarter-frame
Aesthetic Tags:
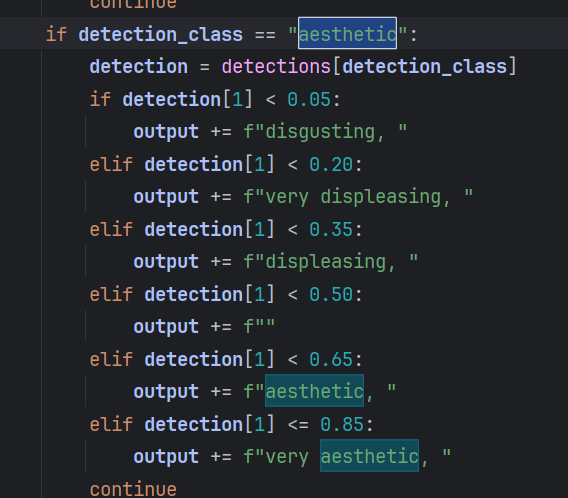
Use like this:
depicted-upper-left half-frame face
depicted-lower-center full-frame legs
You’ll be able to get many interesting outcomes with tags I did not train, due to the model itself recognizing the offset and depictions based on focal points in the sourced images.