Realistic 3D Style v1 [NOOB vPred V0.65S / ePred v1.1]







詳細
ファイルをダウンロード
モデル説明
アップデート1:GMT -7 2024年12月5日 13:51
タグ付けにエラーがあることに気づいた;ヒューマンエラー検出。画像の上部に3Dおよび3Dアートワークタグを自動で付与していたが、本来は画像の末尾に付与すべきだった。このミスにより、期待された結果よりもはるかに弱い出力となってしまった。
新しい推奨ポジティブプロンプトは以下の通り:
3d, 3d \(artwork\), realistic, artist1, artist2, artist3, ... artist99, noob tags here, very aesthetic, aesthetic, masterpiece, highres, absurdres, newest, 3d, 3d \(artwork\), realistic,このプロンプトは、他の代替案よりも多くの解像度で優れた結果を生み出し、アートスタイルがより鮮明に浮かび上がる。
明らかに私のプロセスには改善の余地があるが、それでも構わない。宇宙が与えてくれるものを受け入れよう。
なんでこんなに真面目なの、バットマン?
このスタイルは、特別な描写タグを一切使用しない状態でも非常に成功している。
推奨設定:
強度:
0.8 ePred
0.92 vPred
ステップ数:50
Euler - SGM Uniform
CFG:5-6.5
解像度:1024x1024、1216x1216、1216x832、832x1216、832x832、768x768、512x768、768x512、512x512
ポジティブプロンプト:
3d, 3d \(artwork\), realistic,
normal tags here,
masterpiece, highres, absurdres, newest, 3d, 3d \(artwork\), realistic,
ネガティブプロンプト:
nsfw, worst quality, old, early, low quality, lowres, signature, username, logo, bad hands, mutated hands, mammal, anthro, furry, ambiguous form, feral, semi-anthro, bad anatomy, extra digits
ネガティブまたはポジティブ要素は、お好みで自由に削除してください。
バーンダウン後、多くの高品質な3D画像が「disgusting(不快)」「displeasing(不満)」「very displeasing(非常に不満)」とタグ付けされていることに気づいた。そのため、1024x1024未満の低解像度画像を使用する際は、これらの3つのタグを使っても良い結果が得られる可能性があることを覚えておいてください。
このスタイルのLoRAは、多数のアーティストスタイルやシリーズスタイルを生成します。多くのキャラクターを強化し、一部のベースコスチュームを補正する副次的効果もあります。新しいキャラクターも一部導入されていますが、その影響は弱いため、期待しすぎないでください。
これは特に「ノッジLoRA」としてトレーニングされています。モデルを変形させるのではなく、微調整して改善することを目的としています。新たな主要な情報は導入せず、既存の構造を強化するだけです。
つまり、さまざまなスタイルやアーティストの画像を取り込み、「3d」「3d (artwork)」「realistic」の基本タグを強化しつつ、それらを完全に破壊しないようにしているのです。
いくつかの深度エラーが存在するのは明らかです。複雑さのレベルが高くなると、重なりや問題がアーティファクトとして現れます。これは、画像ソースの際に意図的な補間を用いてアップスケールとシャープネス処理を行ったことによるものと考えられます。
次バージョンは、少なくとも20エポックで10万画像規模のバージョンになるでしょう。今後数週間以内に公開される予定です。
今後数日間、AIリファインメント、画像補間、モーションAI技術の研究に取り組むとともに、「RE-LORA」と呼ぶ移行段階LoRAの設計を行います。これは、バーンインリファインメントLoRAのコンセプトであり、完全に条件付けと画像リファインメント情報を、より高い学習率と少ないステップ数で、固定モデルを特定の位置で繰り返し適用して、モデルのコアを破壊または変更することなく、または全エポックを待たずに実現します。
これはLoRAにも、text_encoderにも似ていますが、どちらでもありません。目的は、圧縮された高次元のストレージテンソルを用いて、モデル自身のデータがどこにあるかという「傷」を刻み込むことです。これはimg2imgやスケッチ、あるいは既存モデルにマスクインペインティングを導入するようなもので、大規模なトレーニングサイクルや多数の画像・マスクデータは必要ありません。
ソートされていない感想:
ePred V1.1でも動作しているようだ。ただ、スケールの測定方法が異なる。
ePred v1.1で驚くほど良好に動作するが、ベースモデルはvPred v0.65Sでトレーニングしている。
2m SDE Heunを使用すると、1300x1300の解像度をサポートし、さらにアップスケール可能。非常に優れた結果が出る。
試してみてください。
クォーターフレームは小さすぎず、予想以上に効果的だった。
もう一度識別を実行し、今回、画像の1/9に相当する「small-frame」のようなさらに小さなタグを導入する必要がある。
エポック30では、現実性と3D表現の制御がさらに向上し、エポック20よりもはるかに優れているが、まだ不完全。
エポック37では、フル画像ディスプレイローラーとさまざまなタグの使用例を多数作成する予定。
動画から切り出した約4000枚の画像、および最新のr34xxxおよびr34us投稿から取得した6000枚の画像を使用。
大まかに1万枚の画像を、2枚のA100でバッチサイズ64、20エポックでトレーニング。
エポック37のトレーニング完了予定は約7時間。今後、さらにいくつかのアップロードが予想される。
アニメーションGIFや動画から取得した画像と、高解像度の非AI生成画像を組み合わせた実験。
それなりに知名度の低い3Dアーティストの作品や、非常に人気のある3Dアーティストの作品が多数含まれている。
すべての画像には、少なくとも1人の人物が含まれている。
現在、アーティストの完全なリストを構築中。ほとんど手動で選択していない。ほぼ自動化されています。詳細は最近の記事をご覧ください。
私はこのLoRAを10万画像版に完全にトレーニングすることにインスパイアされた。
各動画の全フレームをキャプチャし、フレーム間の補間正規化差異をシャープネス、保存性、用途のために記録する。また、フレームごとのタグカウンターも導入する。
これにより、はるかに安定した完全補間動画生成が可能になる。
今のところ、これはいくつかの描写オフセットタグを伴う、スタイリッシュな玩具です。お楽しみください!
描写タグ:
depicted-upper-left
depicted-upper-center
depicted-upper-right
depicted-middle-left
depicted-middle-center
depicted-middle-right
depicted-lower-left
depicted-lower-center
depicted-lower-right
スケールタグ:
full-frame
half-frame
quarter-frame
審美的タグ:
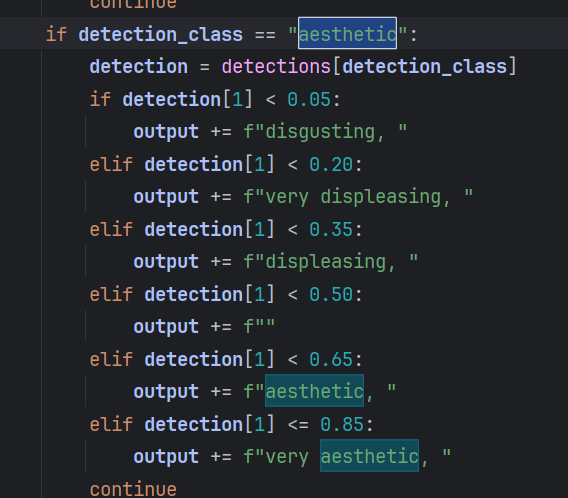
以下のように使用:
depicted-upper-left half-frame face
depicted-lower-center full-frame legs
モデル自体が、ソース画像の焦点に基づいてオフセットや描写を認識するため、私がトレーニングしなかったタグでも、様々な興味深い結果を得られます。