LUT Diffusion

















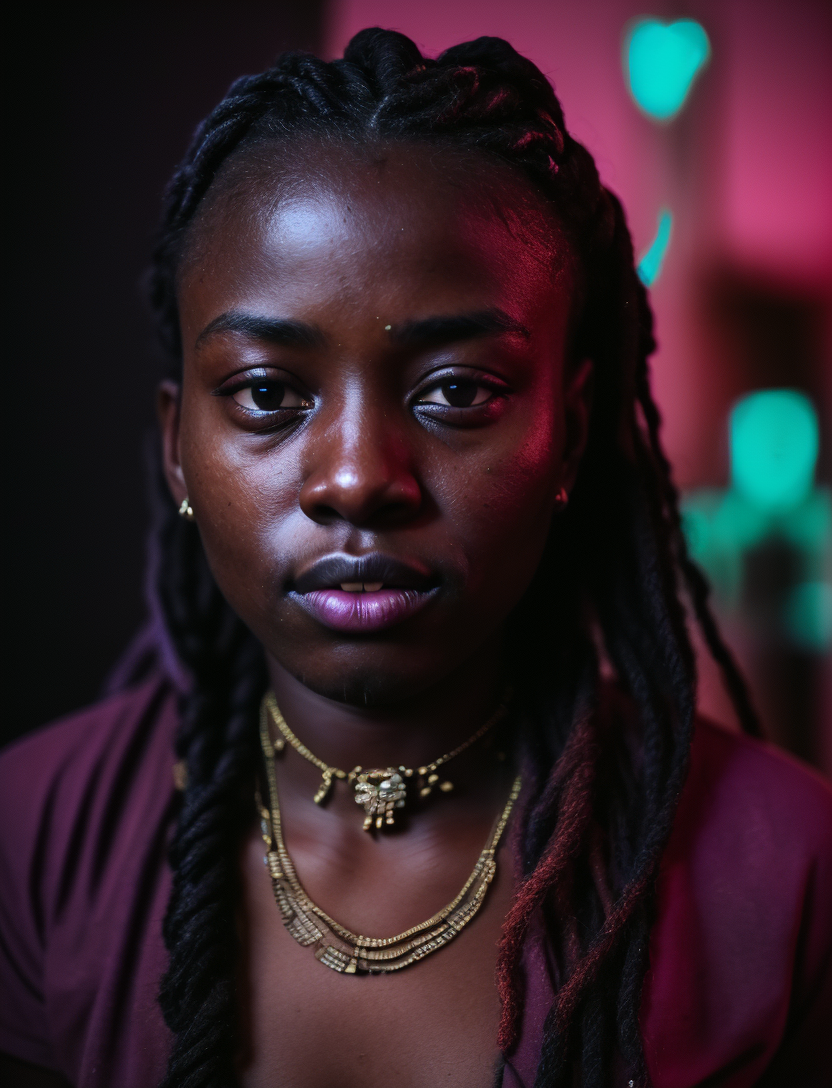


详情
下载文件 (1)
关于此版本
模型描述
Trained with around 150 LUTs on a small dataset, will try to expand it for the next iteration.
Kind of captured its meaning, makes photos look like you applied a filter to them and can pick up on adjectives as well.
Base model used for training: ChimeraMix V5 - so should be versatile, leaning towards realism, high native res. support (~960x960)