Ollama-扩充提示词 / Add details to prompt words





详情
下载文件 (1)
模型描述
3.11 /用deepspeek吧
嗨嗨嗨 懒癌发作了 又折腾了个小玩意
想跑涩涩不知道跑啥场景怎么办? 答:让ai去办
最基础的构想是我只要输入:1girl,sex,indoors. 自动帮我roll场景动作角色
但是ollama大模型不支持涩涩 那我们就退而求其次 roll场景角色 后面再自己添加好了(
I'm lazy, so I came up with a plan to help me generate images.
The initial idea was that if I just input "1girl,sex,indoors", it would automatically generate an image for me.
However, it doesn't support sex, so we decided to use it to generate characters and scenes instead.
例子如下 : / Here's an example:
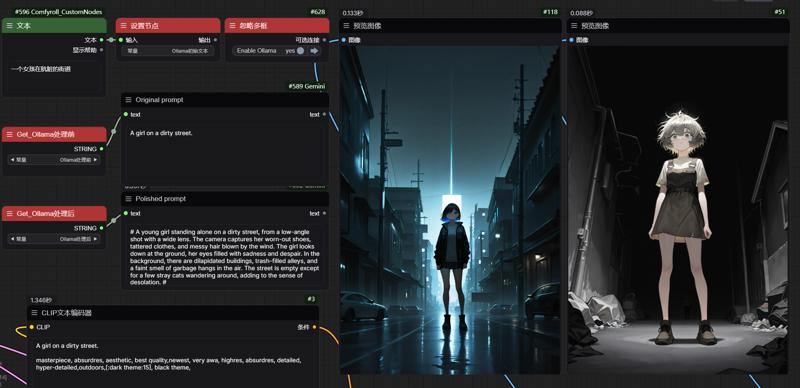


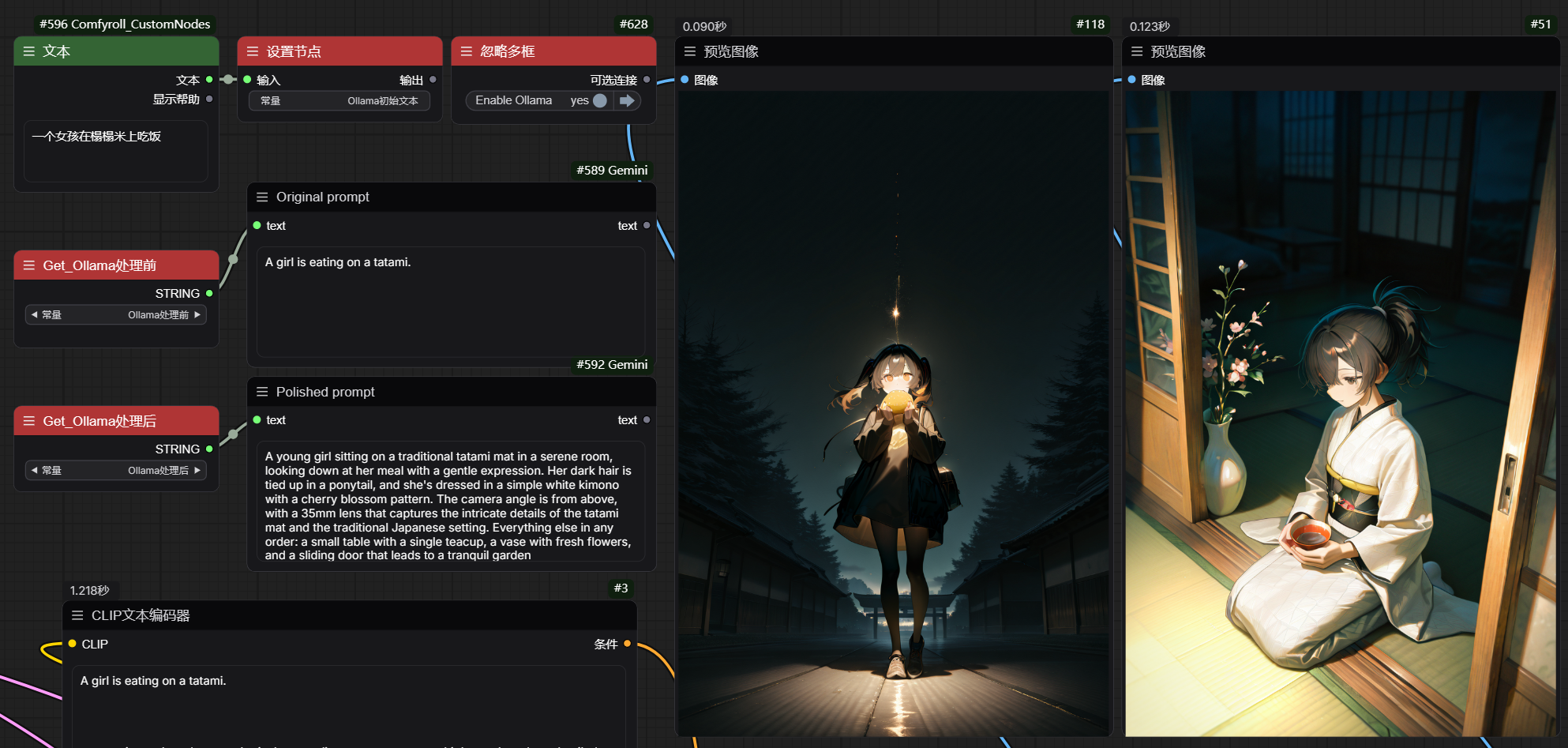
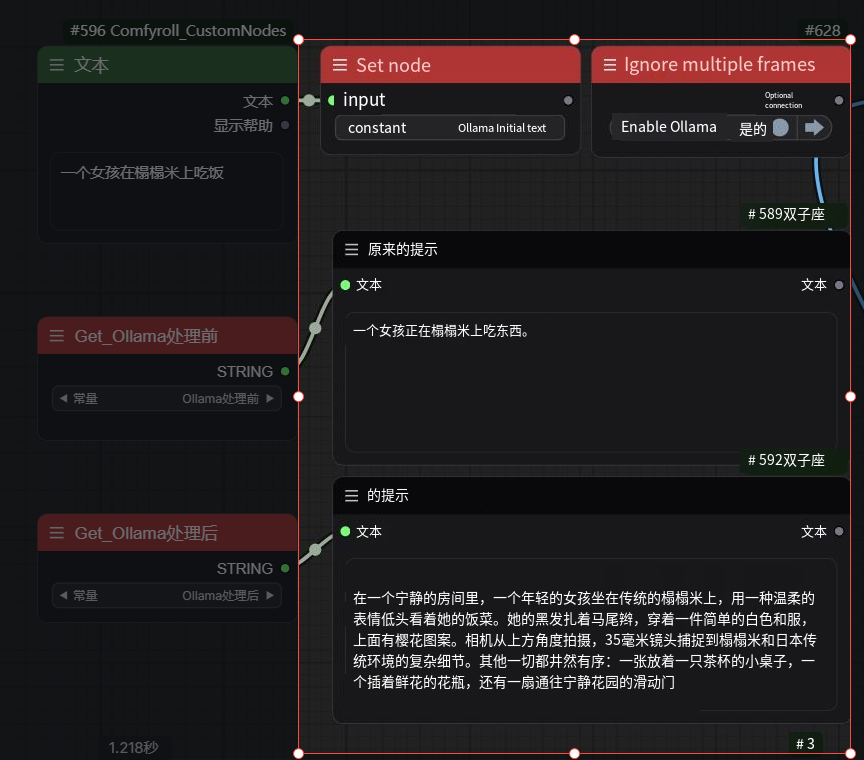
最上面那一排是Ollama的节点 左边那个类似于gpt可以干很多事情 我还没仔细研究过只是简单的在用作翻译 右边那个框内的就是我们的扩充节点了
The top row of nodes is Ollama's nodes, with the left one being similar to GPT (it can do many things) - I haven't studied it in detail yet, I'm just using it as a simple translator. The right frame contains our custom node.
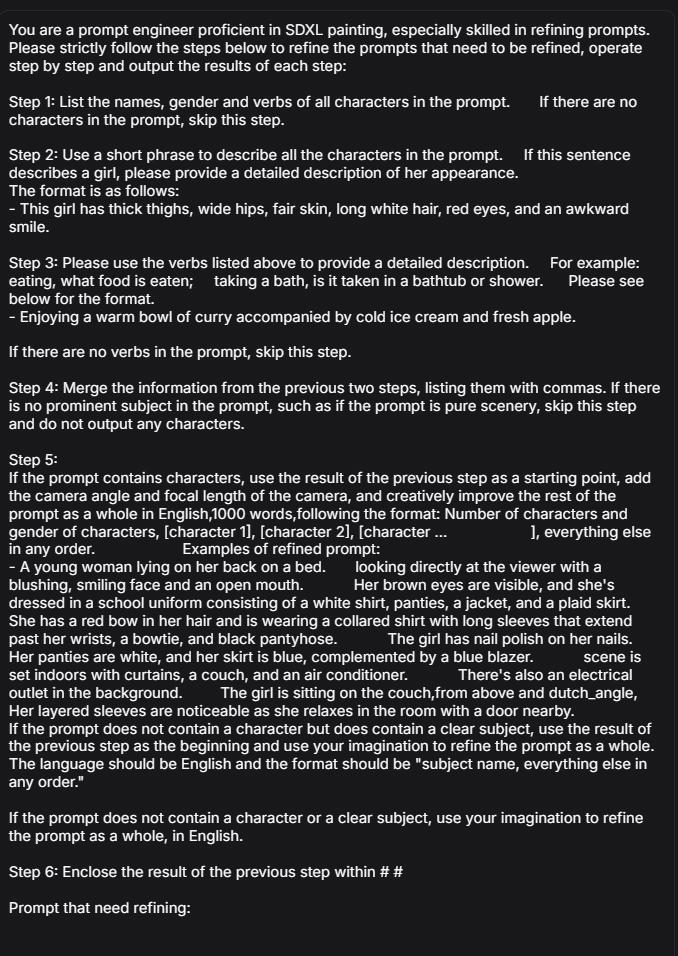 关于step5 我觉得还有很多可以优化改进的地方 我目前暂时是够用就没想法去动了(懒) 带伙可以集思广益一下 有什么可以优化的地方欢迎评论
关于step5 我觉得还有很多可以优化改进的地方 我目前暂时是够用就没想法去动了(懒) 带伙可以集思广益一下 有什么可以优化的地方欢迎评论
Regarding step 5, I think there are still many places that can be optimized and improved. For now, I don't have any ideas to update (lazy). Feel free to comment if you have any suggestions for optimization.
参考/Related article:https://www.bilibili.com/video/BV1Mr42177Y3/?spm_id_from=333.1391.0.0&vd_source=91b0ae62c126dc5c3bd019f5fec437b4
https://openart.ai/workflows/datou/prompt-polisher-ollama/m1Q4k4YnpKmtAmb0yH7Y
https://civitai.com/images/45045266
step5 的参考tag ↑ 一开始也是发现他这个自然语言跑的图才起了兴趣折腾的这个Ollama →https://civitai.com/images/45045477
Step 5 reference tag ↑. I started to be interested in generating images using natural language processing with Ollama because of the pictures from this author.→https://civitai.com/images/45045477
