Flux.1 dev Inpaint Enhanced Workflow

詳細
ファイルをダウンロード (1)
モデル説明
This is a seamless and precise enhanced inpainting workflow, the Flux.1 dev Inpainting Enhanced Workflow.
Compared to the default workflow from the Alimama studio, there are three main improvements:
1. Text Encoder Change:
I replaced the clip-L text encoder with the ViT-L-14-TEXT-detail-improved-hiT-GmP-HF text encoder.
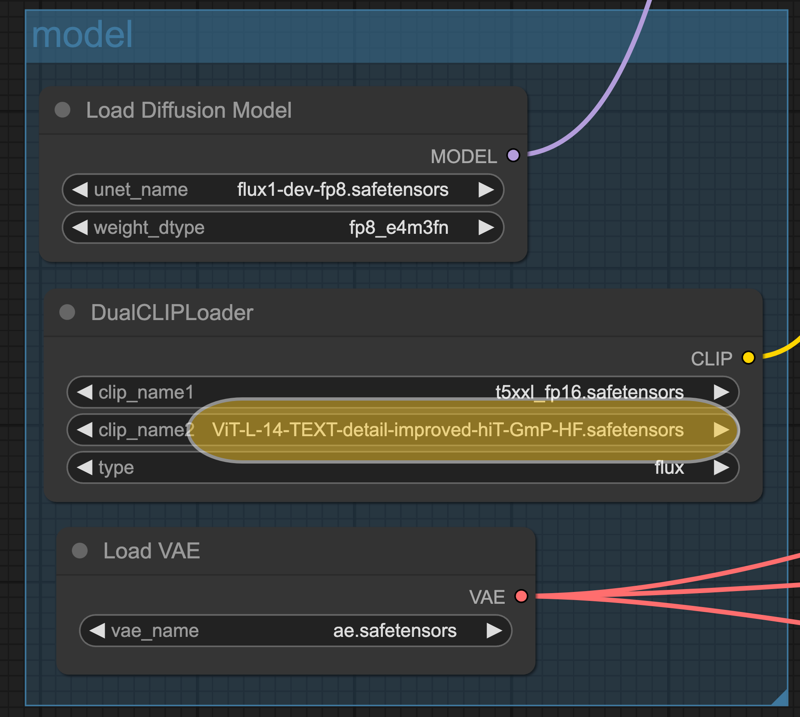
ViT-L-14-TEXT-detail-improved-hiT-GmP-HF is an improved version of the CLIP model with the following features:
• High accuracy: The model achieves around 0.90 accuracy on ImageNet/ObjectNet, a significant improvement over the original OpenAI CLIP model (~0.85).
• Geometric Parameterization (GmP): With this technique, the model performs better in handling image and text details.
• Improved text detail handling: The model has been specially optimized to handle text details, leading to better performance in text and image matching tasks.
These improvements make the ViT-L-14-TEXT-detail-improved-hiT-GmP-HF model more accurate and performant in tasks like image classification and text matching.
Download ViT-L-14-TEXT-detail-improved-hiT-GmP-HF.safetensors,and place it in the models/clip folder.
2. Doodle Reference Area and optional_context Mask: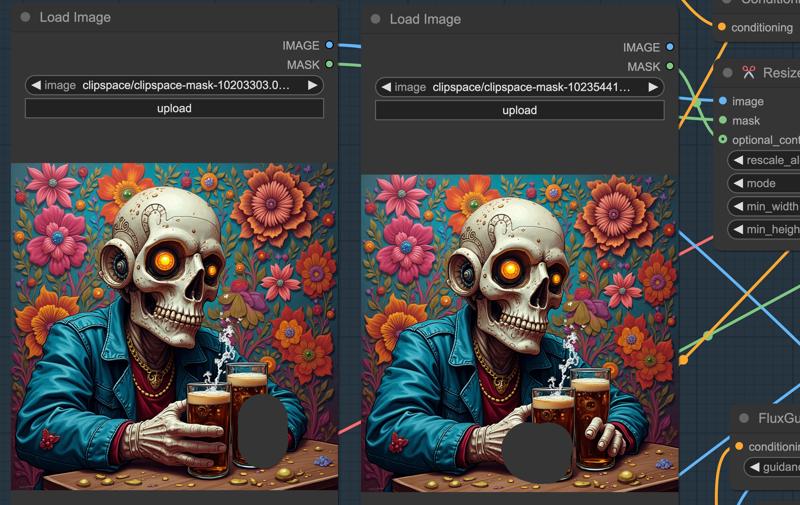
Adding a doodle reference area and integrating the optional_context mask can significantly enhance the image blending effect.
The optional_context mask is a feature within the ViT-L-14-TEXT-detail-improved-hiT-GmP-HF model. It allows for more flexible and detailed processing of text and image data. By using this mask, the model can selectively focus on specific parts of the input data, thereby improving its understanding and generation of detailed descriptions.
• The left doodles represent the areas that need modification.
• The right doodles serve as the reference areas for redrawing.
3. Hyper Flux.1 dev 8steps Lora Model:
You can choose to use the hyper flux.1 dev 8steps Lora model and set the iteration steps to 8. By default, this is disabled with 28 steps.
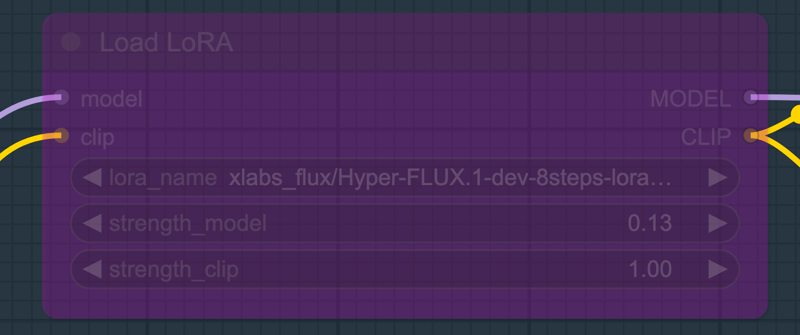
Download Hyper-FLUX.1-dev-8steps-lora.safetensors and place it in the models/loras folder.