Flux.1 dev Inpaint Enhanced Workflow

詳細
ファイルをダウンロード
モデル説明
これはシームレスで高精度なインペイントワークフローであり、Flux.1 dev Inpainting Enhanced Workflowです。
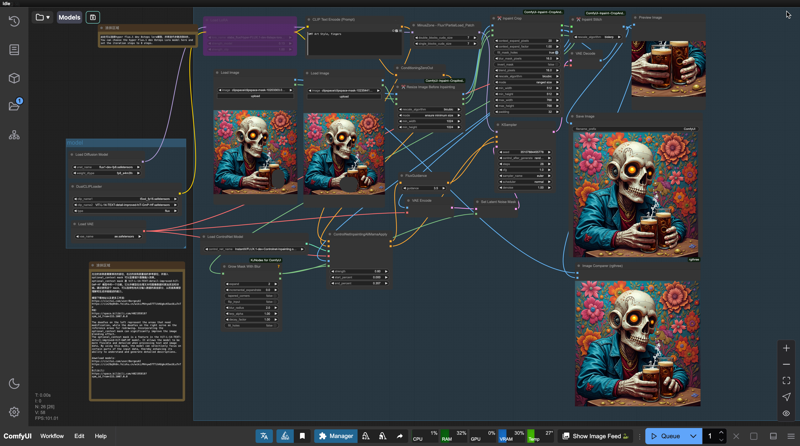
Alimamaスタジオのデフォルトワークフローと比較して、以下の3つの主要な改善点があります:
1. テキストエンコーダの変更:
clip-LテキストエンコーダをViT-L-14-TEXT-detail-improved-hiT-GmP-HFテキストエンコーダに置き換えました。
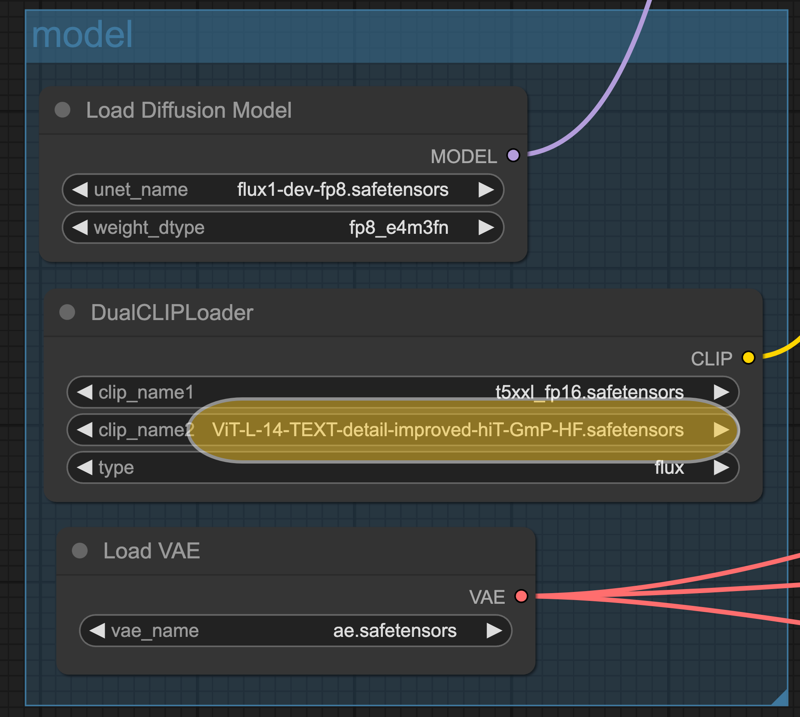
ViT-L-14-TEXT-detail-improved-hiT-GmP-HFは、CLIPモデルの改良版で、以下の特徴を備えています:
• 高精度:このモデルはImageNet/ObjectNetで約0.90の精度を達成し、元のOpenAI CLIPモデル(約0.85)よりも大幅に向上しています。
• 幾何学的パラメータ化(GmP):この技術により、画像とテキストの詳細な処理が向上します。
• テキスト詳細処理の改善:このモデルはテキストの詳細な処理に特化して最適化されており、テキストと画像のマッチングタスクでの性能が向上します。
これらの改善により、ViT-L-14-TEXT-detail-improved-hiT-GmP-HFモデルは、画像分類やテキストマッチングタスクにおいてより正確で高性能になります。
ViT-L-14-TEXT-detail-improved-hiT-GmP-HF.safetensorsをダウンロードし、models/clipフォルダーに配置してください。
2. ドゥードル参照領域とoptional_contextマスク: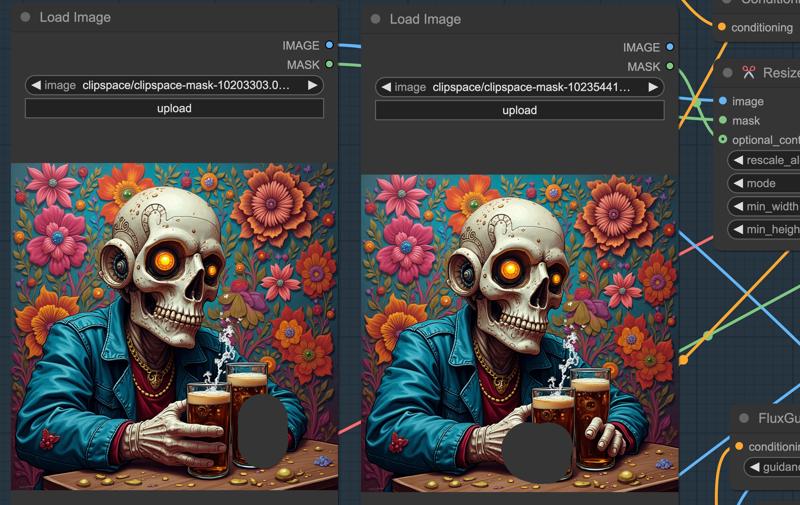
ドゥードル参照領域を追加し、optional_contextマスクを統合することで、画像のブレンド効果が大幅に向上します。
optional_contextマスクはViT-L-14-TEXT-detail-improved-hiT-GmP-HFモデル内に搭載された機能で、テキストと画像データのより柔軟で詳細な処理を可能にします。このマスクを使用することで、モデルは入力データの特定部分に選択的に注目し、詳細な説明の理解と生成能力を向上させることができます。
• 左側のドゥードルは修正が必要な領域を表します。
• 右側のドゥードルは再描画の参照領域として機能します。
3. Hyper Flux.1 dev 8steps LoRAモデル:
Hyper Flux.1 dev 8steps LoRAモデルを使用し、反復ステップを8に設定できます。デフォルトでは無効化されており、28ステップで動作します。
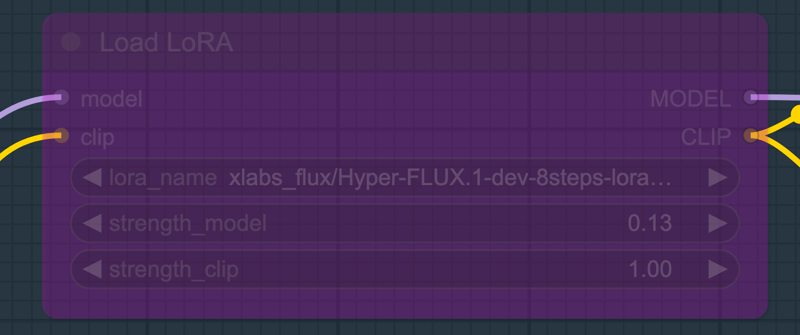
Hyper-FLUX.1-dev-8steps-lora.safetensorsをダウンロードし、models/lorasフォルダーに配置してください。