V4 DeJanked Image 2 Video Hunyuan Magic with Flux and Refiner Speed Hack




詳細
ファイルをダウンロード (1)
このバージョンについて
モデル説明
DONT USE THIS
It was a fun run. I2V proper is released, download that. I'll leave this up only for a weird old initial way of janking a i2v process before it was released
Final version! (probably)
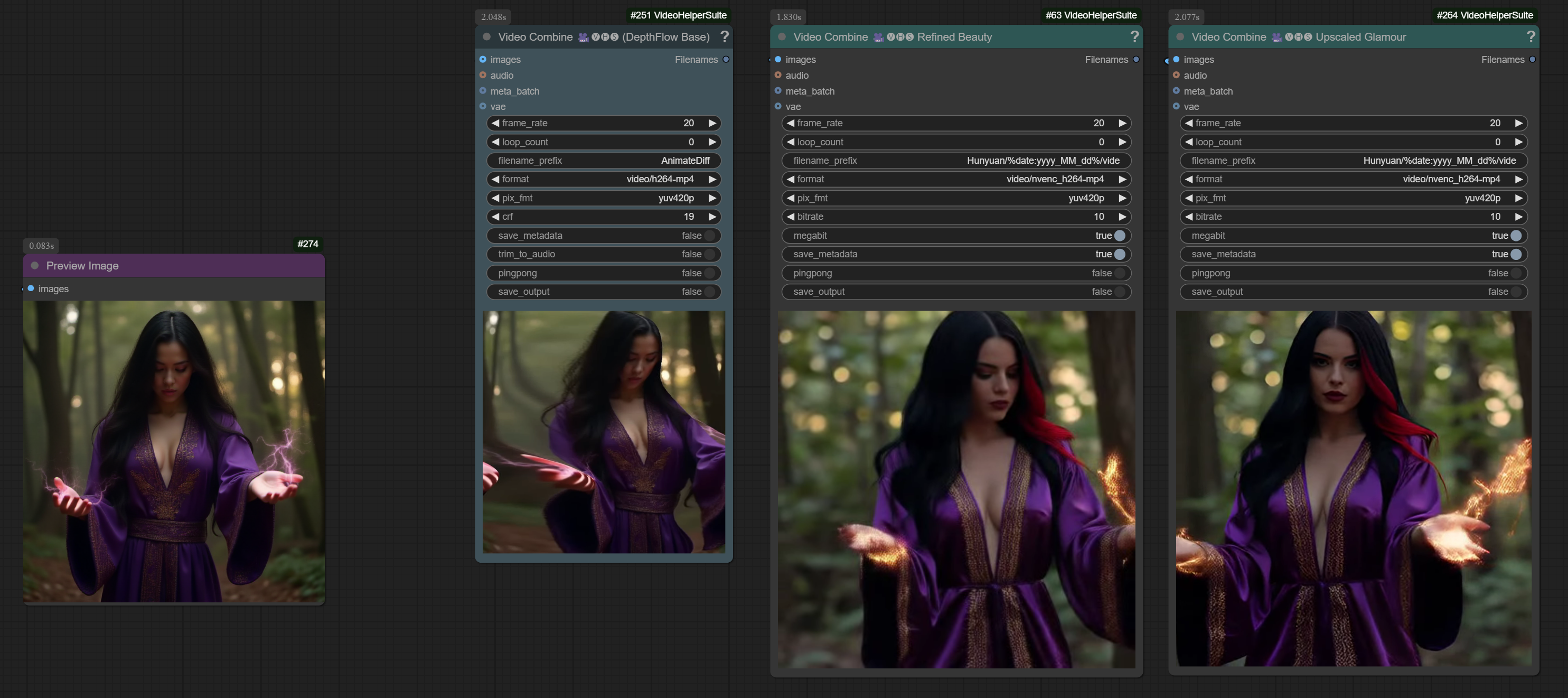
V4 introduces the Refinement speed hack (works great with a guiding video which depthflow uses)
Flux re-enabled
More electrolytes!
This I think is where I will stop. I have had a lot of frustrating fun playing with this and my other backend workflow for the speed hack, but I think this is finally at a place I am fairly okay with. I hope you enjoy it and post your results down below. If there are problems (always problems), post in the comments also. I or others will try to help out.
Alright Hunyuan. balls in your court. how about the official release to make this irrelevant. We're all doing this janky workarounds, so just pop it out already. btw, if you use this for your official workflow, cut me a check, I like eating.
btw, check out the other workflow on here, the leapfusion thing It actually works pretty well. less control over what you're going for, but closer to the original picture. both are cool to have.
Final update: (HA!)
Added Hunyuan Refiner step for awesomeness
Streamlined
Minor update:
V3.1 is more about refining.
Removed Reactor (pulled from Github
Removed Flux (broken)
Removed Florence (huge memory issue)
Denoodled
Added a few new options to depthflow.
V3: ITS THE FINAL COUNTDOWN!
Alright, this is probably enough. someone else get creative and go from here, but I think I am done messing around with this overall and am happy with it...(until I am not. Come on Hunyuan...release the actual image 2 video)
Anyhow, tweaks and thangs:Added in Florence for recommendation prompt (not attached, just giving you suggestions if you have it on for the hunyuan bit)
Added switches for turning things on and off
More logical flow (slight overhead save)
Shrink image after Depthflow for better preservation of picture elements
Made more stroking colors (Follow the black) and organization for important settings areas
Various tweaks and nudges that I didn't note.
V2:
More optimized, a few more settings added, some pointless nodes removed, and overall a better workflow. Also added in optional Flux group if you want to use that instead of XL
Added in also some help with Teacache (play around with that for speed, but don't go crazy with the thresh..small increments upwards)
Anyhow, give this a shot, its actually pretty impressive. I am not expecting much difference between this vs whenever they come out with I2V natively...(hopefully theirs will be faster though, the depthflow step is a hangup)
Thanks to the person who tipped me 1k buzz btw. I am not 100% sure what to do with it, but that was cool!
Anyhow
(NOTE: I genuinely don't know what I am doing regarding the HunyuanFast vs Regular and Lora. I wrote don't use it, and that remains true if you leave it on the fast model..but use it if using the full model. Ask for others, don't take my word as gospel. consider me GPT2.0 making stuff up. all I know is that this process works great for a hacky image2video knockoff)
XL HunYuan Janky I2V DepthFlow: A Slightly Polished Janky Workflow
This is real Image-to-Video. It’s also a bit of sorcery. It’s DepthFlow warlock rituals combined with HunYuan magic to create something that looks like real motion (well, it is real motion..sort of). Whether it’s practical or just wildly entertaining, you decide.
Key Notes Before You Start
Denoising freedom. Crank that denoising up if you want sweeping motion and dynamic changes. It won’t slow things down, but it will alter the original image significantly at higher settings (0.80+). Keep that in mind. Even with 80+, it'll still be similar to the pic though.
Resolution matters. Keep the resolution (post XL generation) to 512 or lower in the descale step before it shoots over to DepthFlow for faster processing. Bigger resolutions = slower speeds = why did you do this to yourself?
Melty faces aren’t the problem. Higher denoising changes the face and other details. If you want to keep the exact face, turn on Reactor for face-swapping. Otherwise, turn it off, save some time, and embrace the chaos.
DepthFlow is the magic wand. The more steps you give DepthFlow, the longer the video becomes. Play with it—this is the key to unlocking wild, expressive movements.
Lora setup tips.
Don’t use the FastLoRA—it wont work using the fast Hunyuan model which is on by default. Use it if you change the model though
Load any other LoRA, even if you’re not directly calling it. The models use the LoRA’s smoothness for better results.
For HunYuan, I recommend Edge_Of_Reality LoRA or similar for realism.
XL LoRAs behave normally. If you’re working in the XL phase, treat it like any other workflow. Once it moves into HunYuan, it uses the LoRA as a secondary helper. Experiment here—use realism or stylistic LoRAs depending on your vision.
WARNING: REACTOR IS TURNED OFF IN WORKFLOW!
(turn on to lose sanity or leave off and save tons of time if you're not partial to the starting face)
How It Works
Generate your starting image.
Be detailed with your prompt in the XL phase, or use an image2image process to refine an existing image.
Want Flux enhancements? Go for it, but it’s optional. The denoising from the Hunyuan bit will probably alter most of the Flux magic anyhow, so I went with XL speed over Flux's clarity, but sure, give it a shot. enable the group, alter things, and its ready to go. really just a flip of a switch.
DepthFlow creates movement.
Add exaggerated zooms, pans, and tilts in DepthFlow. This movement makes HunYuan interpret dynamic gestures, walking, and other actions.
Don’t make it too spazzy unless chaos is your goal.
HunYuan processes it.
This is where the magic happens. Noise, denoising, and movement interpretation turn DepthFlow output into a smooth, moving video.
Subtle denoising (0.50 or lower) keeps things close to the original image. Higher denoising (0.80+) creates pronounced motion but deviates more from the original.
Reactor (optional).If you care about keeping the exact original face, Reactor will swap it back in, frame by frame.If you’re okay with slight face variations, turn Reactor off and save some time.
Upscale the final result.
The final step upscales your video to 1024x1024 (or double your original resolution).
Why This Exists
Because waiting for HunYuan’s true image-to-video feature was taking too long, and I needed something to tinker with. This (less) janky process works, and it’s a blast to experiment with.
Second warning:
You're probably gonna be asked to download a bunch of nodes you don't have installed yet (DepthFlow, Reactor, and possibly some others). Just a heads up.
Final Thoughts
This workflow is far from perfect, but it gets the job done. If you have improvements, go wild—credit is appreciated but not required. I just want to inspire people to experiment with LoRAs and workflows.
And remember, this isn’t Hollywood-grade video generation. It’s creative sorcery for those of us stuck in the "almost but not quite" phase of technology. Have fun!