HunyuanVideo - Workflow

Details
Download Files (1)
About this version
Model description
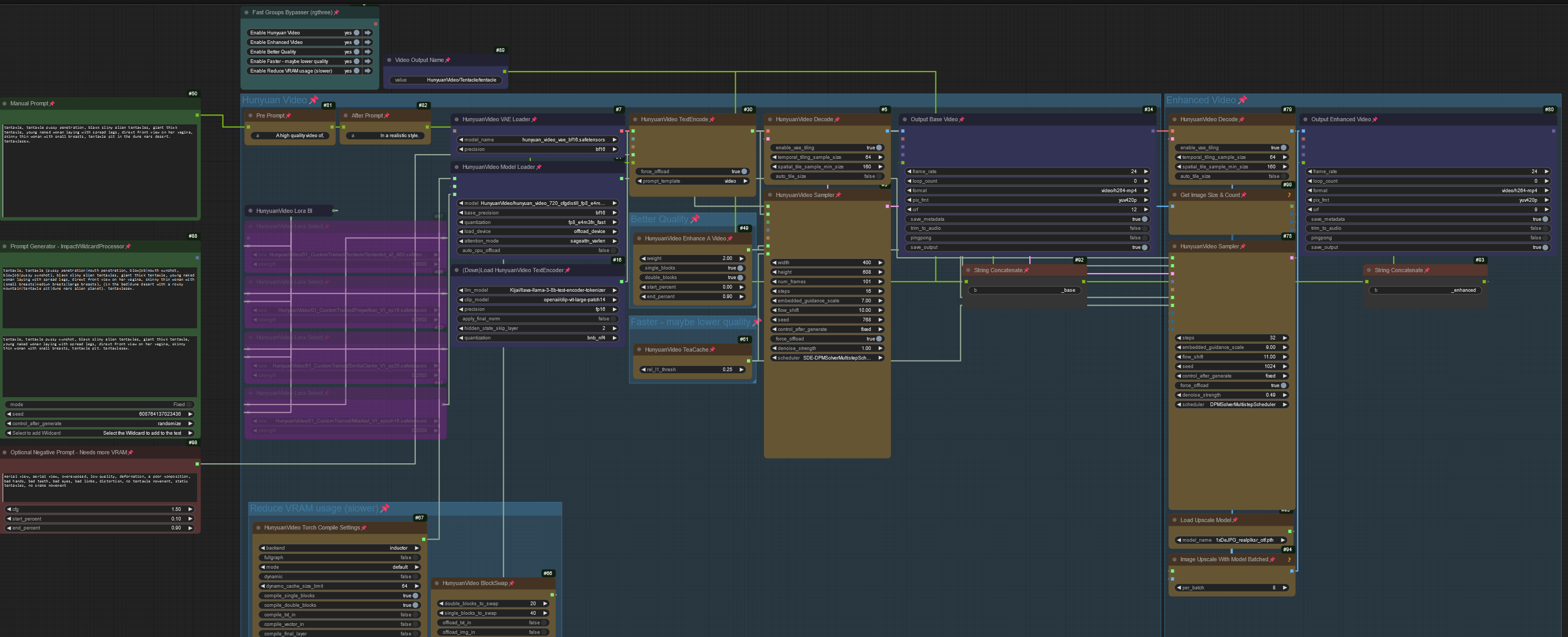
Here is my workflow for HunyuanVideo - using the hunyuanvideo-wrapper.
The example prompt in the workflow is nsfw.
Upscaler model download:
https://github.com/Phhofm/models/releases/download/1xDeJPG_realplksr_otf/1xDeJPG_realplksr_otf.safetensors
ComfyUI_windows_portable\ComfyUI\models\upscale_models
HunyuanVideoWrapper download links:
Transformer and VAE (single files, no autodownload):
https://huggingface.co/Kijai/HunyuanVideo_comfy/tree/main
Go to the usual ComfyUI folders (diffusion_models and vae)
LLM text encoder (has autodownload):
https://huggingface.co/Kijai/llava-llama-3-8b-text-encoder-tokenizer
Files go to ComfyUI/models/LLM/llava-llama-3-8b-text-encoder-tokenizer
Clip text encoder (has autodownload)
Either use any Clip_L model supported by ComfyUI by disabling the clip_model in the text encoder loader and plugging in ClipLoader to the text encoder node, or allow the autodownloader to fetch the original clip model from:
https://huggingface.co/openai/clip-vit-large-patch14, (only need the .safetensor from the weights, and all the config files) to:
ComfyUI/models/clip/clip-vit-large-patch14