HyVid - High Quality & Fast Speed Generation for 24GB Cards - Hunyuan Video Workflow


詳細
ファイルをダウンロード (1)
このバージョンについて
モデル説明
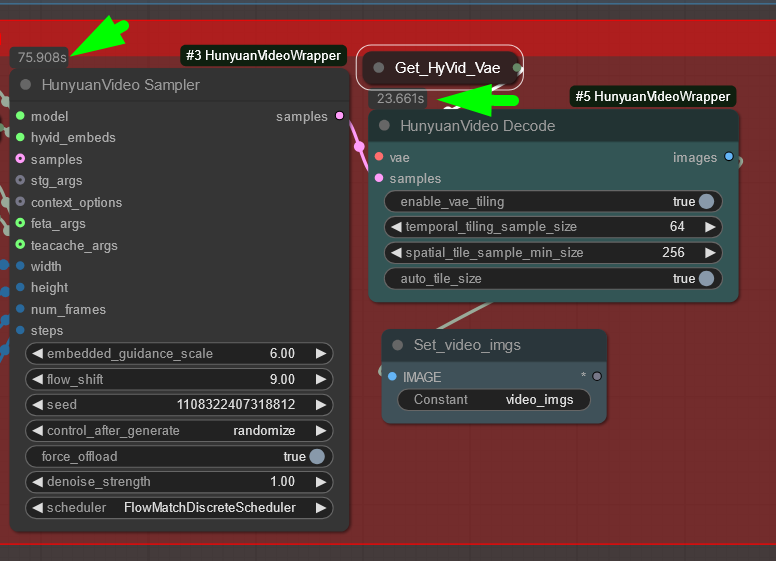
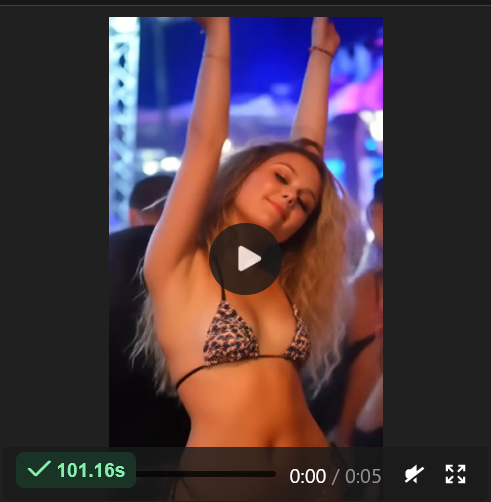
This workflow is giving me 416x736 resolution, 24FPS, 5 Second clips in 90-120 seconds (~75 seconds on gen, ~25 seconds on Decode, using the BF16 Model with multiple Loras. (Upscaling will add time) [If you can't use the Compiling or TeaCache you will get longer gen times.] It uses around 18GB of VRAM when generating.
I designed this specifically around a RTX 4090 - 24GB VRAM, 64GB RAM, running on Windows 10. I will not be able to provide recommendations for other hardware or operating systems.
I much prefer the outputs of the BF16 model of Hunyuan video, with the Triton Torch Compiling and TeaCache I get generations in 90-120 seconds (once the cache is warmed up) (Depending on your torch version you may have to make an edit to a PyTorch file, there is a guide in the notes in the workflow). While the model is loading it might lag the hell out of your PC but just be patient.
So far I found the best speeds and outputs at 416x736 resolution (or flipped), 121 frames (which at 24fps gives you 5 second clips) and steps between 20-30 (depending on your Loras)
Most Lora's I've tested work well between .5 and 1. You may need to lower the strength on one or more of the Loras when mixing them. If you get blurry/grainy videos try lowering.
Most of these discoveries have been trial and error, especially around the Triton Torch Compiling and TeaCache so I likely can't give much guidance outside of whats currently in the settings. Installing Triton on Windows was a nightmare - I used this guide: https://old.reddit.com/r/StableDiffusion/comments/1h7hunp/how_to_run_hunyuanvideo_on_a_single_24gb_vram_card/
None of this would be possible without kijai and the team behind the ComfyUI-HunyuanVideoWrapper so big props to them
Requires the following Custom Node Packages
Impact Pack - (For Wildcard Prompts) - https://github.com/ltdrdata/ComfyUI-Impact-Pack
KJNodes - (For Get/Set Nodes) - https://github.com/kijai/ComfyUI-KJNodes
HunyuanVideo Wrapper - (For Loading Hunyuan Models) - https://github.com/kijai/ComfyUI-HunyuanVideoWrapper (MAKE SURE YOU HAVE UPDATED SINCE 2025-01-18)
VideoHelperSuite (For creating video output) - https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite
ComfyUI Frame Interpolation (For Frame Interpolation) - https://github.com/Fannovel16/ComfyUI-Frame-Interpolation
Requires the following Models
Hunyuan Video Safe Tensors - I like the BF16 best - https://civitai.com/models/1018217?modelVersionId=1141746
Hunyuan Video VAE - https://civitai.com/models/1018217?modelVersionId=1141674
Hunyuan Text Encoders - https://github.com/Tencent/HunyuanVideo/blob/main/ckpts/README.md#download-text-encoder
Upscale and Frame Interpolation Models
4x_foolhardy_Remacri - https://huggingface.co/FacehugmanIII/4x_foolhardy_Remacri
Film Net FP32 - https://civitai.com/models/1167575?modelVersionId=1314385
If you find this Workflow help please consider donating buzz so I can further my Lora Trainings and Workflow development.
If you discover any improvements or issues please leave a comment on the post.