SDXL config ComfyUI Fast generation 4GB vRAM (refiner)

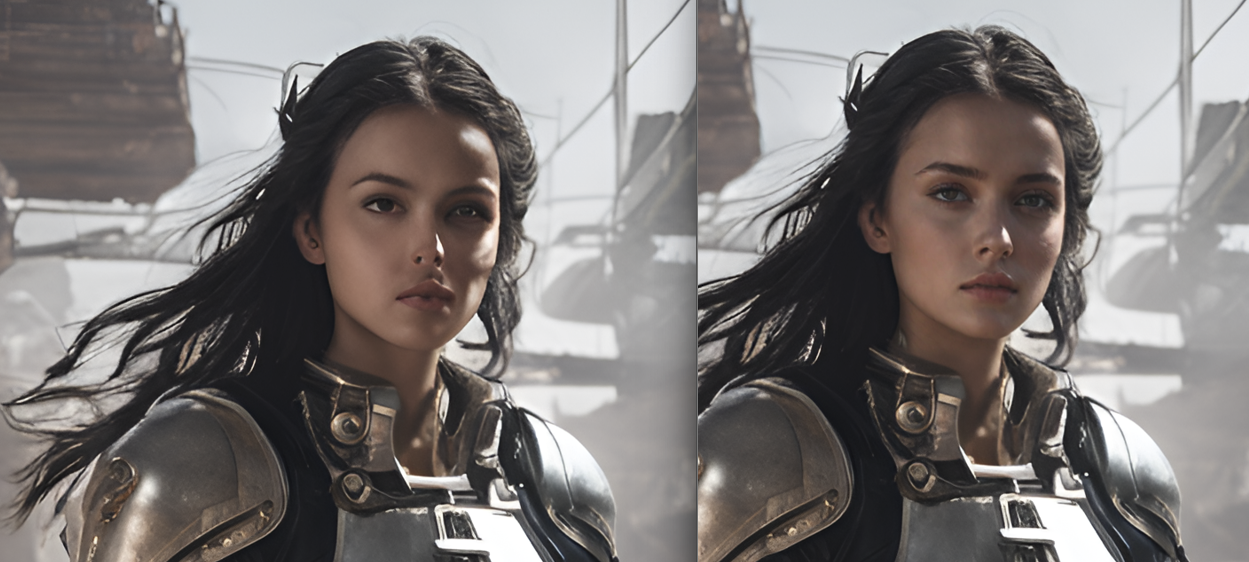

詳細
ファイルをダウンロード
このバージョンについて
モデル説明
みなさん、
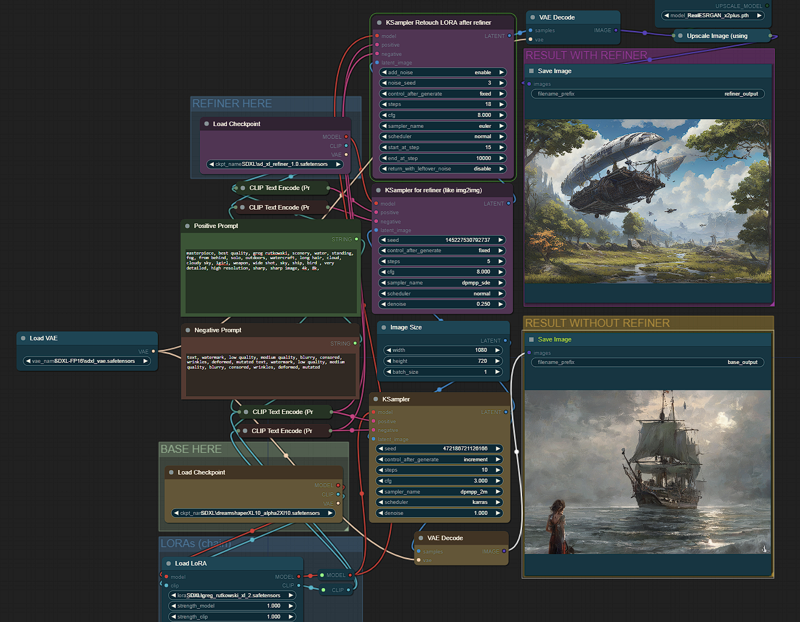
SDXL 1.0を試していたのですが、RTX 3050 Laptop(4GB VRAM)搭載のノートPCでは3分以内に生成できず、ComfyUIで最適な設定を模索しました。その結果、バッチ生成では55秒、新しいプロンプトを検出すると70秒で生成できるようになりました。リファイナーが動作すると、非常に美しい画像が得られます。
この設定は、画像サイズ(1024x720)、モデル、ステップ数(10+5 リファイナー)、サンプラー/スケジューラーのバランスを最適化したもので、高価で大型なデスクトップGPUなしでも、ノートPCでSDXLを利用できるようにしました。
多くの人が普段ノートPCを使っているので、私のComfyUI設定を共有したいと思います。これが私が見つけた最適なバランスだと考えています。
「run_nvidia_gpu.bat」にパラメータを追加:--normalvram --fp16-vae
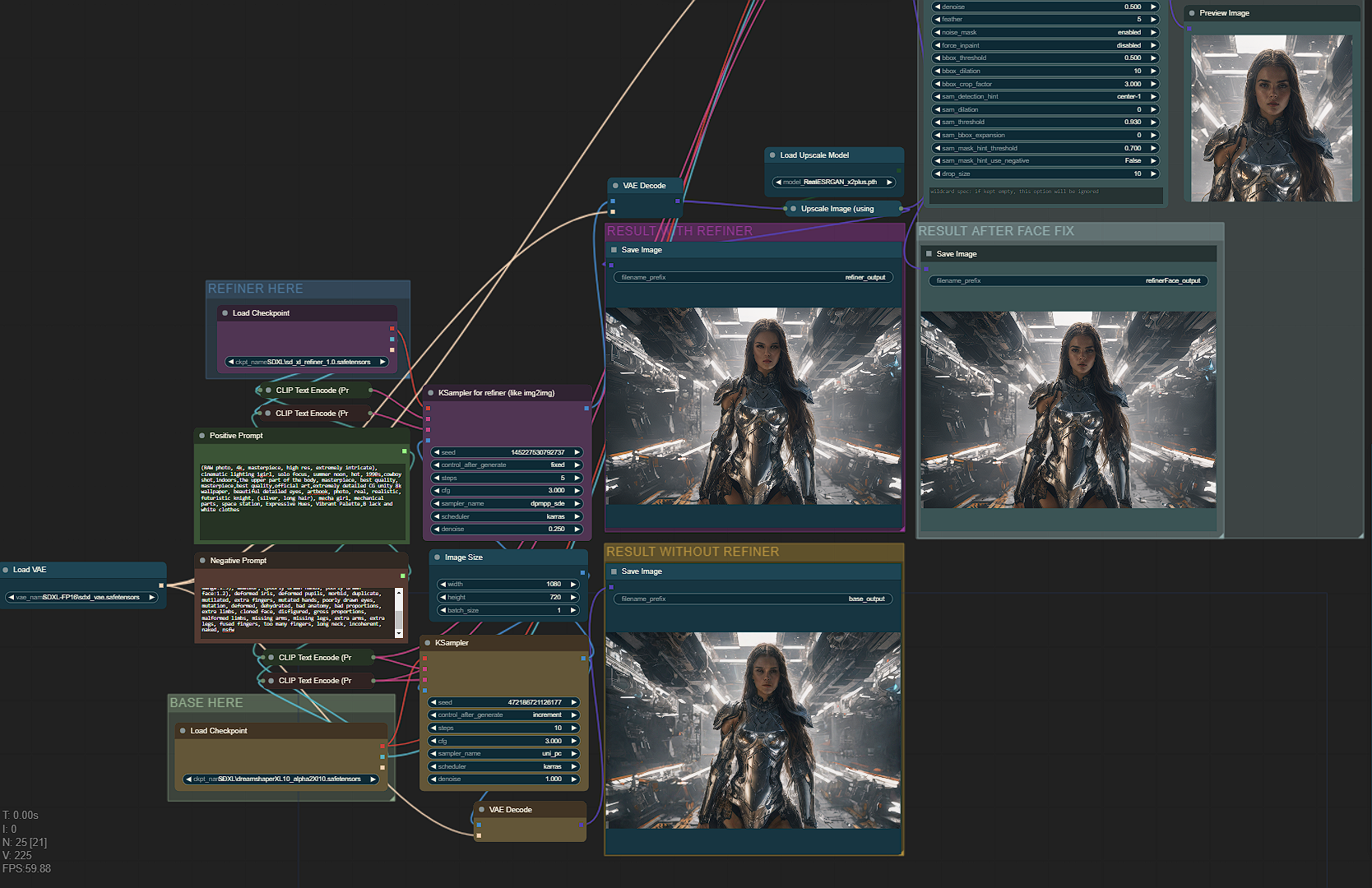
フェイスフィックス高速版?
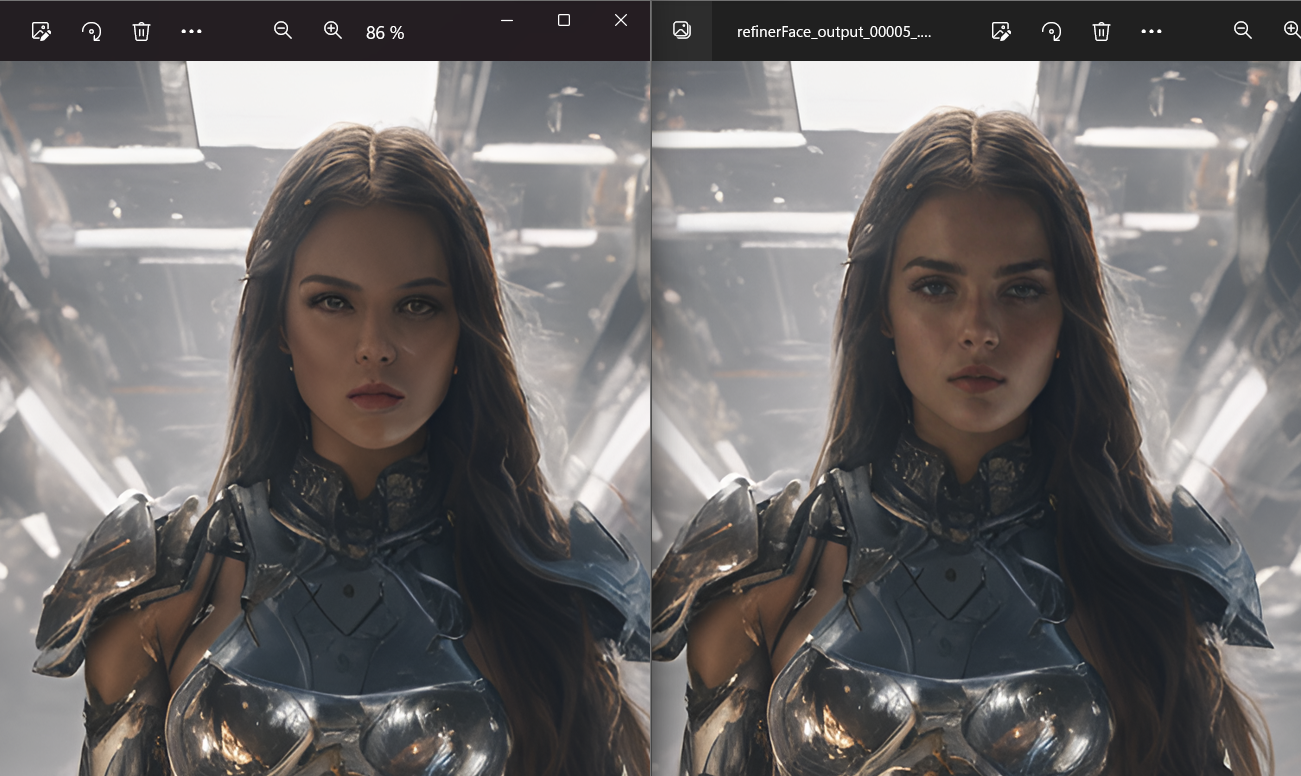
SDXLでは、顔が「カメラ」から遠い(小さな顔)場合に顔が崩れやすい問題があります。このバージョンでは、検出された顔に対してのみ5ステップ追加して修正します。
フェイスフィックス非高速版?
非高速版では、アップスケーラー後に顔を修正します。非常に小さな顔でもより良い結果が得られますが、高速版より20秒ほど時間がかかります。
フェイスフィックスの出力が別の画像を生成しない場合(おそらく4倍アップスケーラーを使用している可能性があります)、コンソールに「segment skip [determined upscale factor=0.9875809267424535]」と表示されたら、モジュール「FaceDetailer」の「guide_size」を1280から1408以上に増やして、FaceDetailerが有効化されるまで調整してください。
LORAとLORA高速版の違いは?
LORA高速版を選択すると、20~30秒の時間短縮が可能です。
LORA高速版では、リファイナー後にLORA効果を微調整するための3ステップが含まれていません。リファイナーはLORAの効果を薄めてしまう場合があり、カスタムスタイルのLORAでは、最後の3ステップが必要になることがあります。ただし、ほとんどのケースでは不要です。スタイルが画像に大きく影響するカスタムLORAにのみ、非高速版を推奨します。
(初回画像後)生成時間:
LORAなし: 55~60秒
LORAあり: 85~115秒
LORA高速版: 75~80秒
フェイスフィックスあり: 80秒(高速版) - 110秒(非高速版)
ダウンロードファイル:
Refiner SDXL 1.0:https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0
Model Dreamshaper SDXL 1.0(またはその他):/model/112902/dreamshaper-xl10
Fixed SDXL VAE 16FP:https://huggingface.co/madebyollin/sdxl-vae-fp16-fix(同一フォルダ内に
config.json、diffusion_pytorch_model.safetensors、sdxl_vae.safetensorsをVAE/<NEW_FOLDER>配下に配置)アップスケールモデル(RealESRGANまたはSwin2SR):
https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.1/RealESRGAN_x2plus.pth
https://github.com/mv-lab/swin2sr/releases/download/v0.0.1/Swin2SR_Lightweight_X2_64.pthフェイスフィックス版用(FaceDetailer):
ComfyUI/models/sams:https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth