ŞİH





















詳細
ファイルをダウンロード
このバージョンについて
モデル説明
a.k.a. Türkiyeモデル(SHIH)
説明
最近ダウンロードした中で最も気に入った2つのモデル、Better Days と ΣΙΗ をランダムにマージしました。Noob vpredモデルであり、個人的に両者の最も優れた特徴を維持しており、ΣΙΗの強力なアーティストタグと構図を保持しつつ、Better Daysの一部の照明効果を追加して強化しています。メカマージ手法を用いてun-sepia-fyingでBetter Daysを処理し、その後ΣΙΗの構図、vpred、アーティストブロックをマージし、最終的にNVIDIAのQLIP-L-14-392でCLIPを改造しました。詳細は「マージプロセス」セクションをご覧ください。
使用方法
標準的なNoobAI品質タグが適用されます。詳細はNoobAIのドキュメントを確認してください。また、very aesthetic(正)とdispleasing(否定)タグにも多少の効果があります。LAXHAR Labs推奨のプロンプト順序は次の通りです:アーティストタグ、[あなたのプロンプトここに]、品質タグ
このモデルはV-pred ZSNRモデルであり、Automatic1111-webuiでは動作しません。vpredモデルから画像を生成するには、Automatic1111 WebUIのdevブランチ、ComfyUI または reForge に切り替える必要があります。個人的にはreForgeへの切り替えを推奨します。このモデルにはバンドルされたVAEが含まれています。
例示画像を再現するには、reForge/ComfyUIの拡張機能を調整する必要がある場合があります。PAGとSEGの使い方を詳しく解説した記事へのリンクは、記事作成次第掲載します。現時点では、画像を完璧に再現したい場合は、画像をダウンロードし、reForgeのPNG Infoタブにドラッグして、Hires.fixのOverrideをオフにしてください。なぜか拡張機能が自動でこのチェックボックスをオフにすることがあるため、必要に応じて手動で修正してください。
このバカのようにしないでください。
ライセンス
NoobAIと同様です。
マージプロセス
透明性とマージ知識の普及を目的として、以下の完全な手順を記載します。一部の手順は省略していますが、正しいComfyUIノードをダウンロードすれば実行可能です。ほとんどの処理はsd-mechaで行われており、Pythonを理解している場合、Comfy-Mecha拡張機能を用いてComfyUIノードに適用することも可能です。
0. betterDaysIllustriousXL_V01ItercompPerp.mecha
1. betterDaysIllustriousXL_V01Cyber4fixPerp.mecha
2. betterDaysIllustriousXL_V01CyberillustfixPerp.mecha
3. merge "weighted sum" &0 &1 alpha=0.5
4. merge "weighted sum" &0 &2 alpha=0.5
5. merge "weighted sum" &3 &4 alpha=0.5
生成されたファイルを betterDaysIllustriousXL_V01ItercompCyberfixPerpWeightedSum05Squared と名前を変更してください。必要に応じて、ステップ3を betterDaysIllustriousXL_V01ItercompPerpCyber4fixPerpWeightedSum05、ステップ4を betterDaysIllustriousXL_V01ItercompPerpCyberillustfixPerpWeightedSum05 と名前をつけても構いません。あるいは、私が徹底的に保存しているすべてのチェックポイントから、こちら/こちらから直接ダウンロードすることも可能です。
(本当に興味があるなら、こちらでそれらの見た目を確認できます。)
6. recipe_deserialize_mda_queue.py
7. vpredtimeout2emb.py
8. recipe_deserialize.py
最後のステップはQLIP置換ですが、sd-mechaではなくComfyUIで行いました。なぜなら、ComfyUIがデフォルトでほとんどのノードを内蔵しており、より簡単だからです。
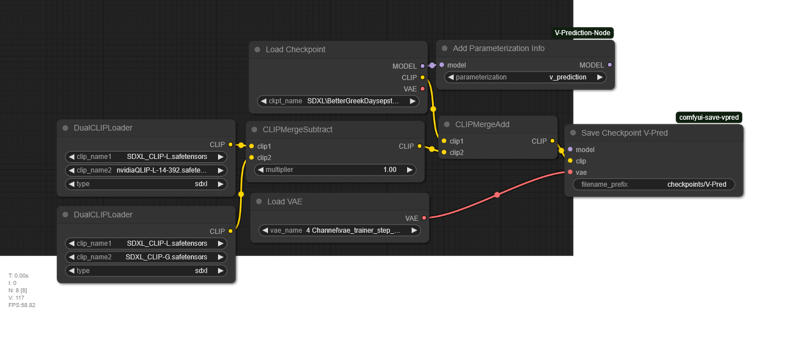 可能な改善点: ステップ3-5は単純な加重平均ではなく、より洗練されたマージ手法(例:SLERP)を使用することで改善できる可能性があります。現在最も効果的であるのは比較的フィッシャー法ですが、その実装方法はわかりません。また、別のモデルからテキストエンコーダの重みを取得することもできます。LobotomizedはCLIPがほぼ類似しているため、簡単な選択肢ですが、品質キーワードのためUNetセグメントが若干調整されています。ステップ0-5をスキップしてSHADOWMAXXのみにすることも可能ですが、それが良いか悪いかはテストしないとわかりません。QLIP置換は疑問が残ります。スキップするか、DAREマージを使用するのも一案です。残念ながらCLIPのマージ技術は未発達であり、CLIP内で重みの明確なブロックが識別できないことが原因です。
可能な改善点: ステップ3-5は単純な加重平均ではなく、より洗練されたマージ手法(例:SLERP)を使用することで改善できる可能性があります。現在最も効果的であるのは比較的フィッシャー法ですが、その実装方法はわかりません。また、別のモデルからテキストエンコーダの重みを取得することもできます。LobotomizedはCLIPがほぼ類似しているため、簡単な選択肢ですが、品質キーワードのためUNetセグメントが若干調整されています。ステップ0-5をスキップしてSHADOWMAXXのみにすることも可能ですが、それが良いか悪いかはテストしないとわかりません。QLIP置換は疑問が残ります。スキップするか、DAREマージを使用するのも一案です。残念ながらCLIPのマージ技術は未発達であり、CLIP内で重みの明確なブロックが識別できないことが原因です。
この技術を盗んで、改善して構いません。実際、改善できるならぜひ行ってください。LobotomizedMixと同様に、コードはこちらにあります。
Q & A
Q: 馬鹿げた名前だね。
A: ありがとう。Q: カバー画像のフォントがなんでこんな馬鹿げてるの?
A: 私のせいじゃないよ。トルコ語をサポートするフォントは全部で8種類しかないんだよ?ちょっとは許してよね。使える選択肢が非常に限られていたんだ。Q: このモデルには内蔵のアーティストタグは含まれているの?
A: はい、とても強力です。好みのアーティストの組み合わせを実験してみてください。Q: ソースモデルと比べてどうなの?
A: あくまで主観的意見ですが、ΣΙΗの品質を向上させ、Better Daysの汎用性とパワーを強化していると思います。Better Daysの主な問題は、照明スタイルが非常に固定されていることです。質感や滑らかさは変えられますが、照明はほとんど変更が不可能で、具体的には「動機づけられていない照明」を得ることが不可能です。そのため、Better Daysはアーティストキーワードには反応します(こちら参照)が、結局すべての画像が非常に似たようなものになってしまうのは、光と影の方向が常に同じだからです。Q: 「動機づけられていない照明」とは?
A: 照明は画像だけでなく映像撮影においても方向性を持ちます。多くの場合、主な照明源は画像内に実際に存在する「実用的照明」です。たとえば、こちらの月が実用的照明です。さらに、理論的に存在しうる照明源を想定すると、それを「動機づけられた照明」と呼びます。この画像では照明源は見えませんが、一方向から来ているため、現実的にあり得ます。そうした2つに対して、「動機づけられていない照明」とは、説明がなく単にシーンを照らすために存在する照明です。なぜBetter Daysではシルエットが目立つのか? Better Daysは動機づけられていない照明を嫌い、現実的(=動機づけられた)照明を好むからです。観察者はスポットライトを携帯していないので、こんな風になります: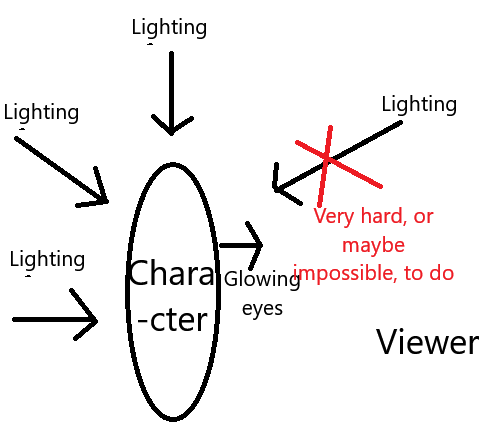 これがBetter Daysでシルエットが目立つ主な理由であり、光る目が素敵に見えるのは、実用的/動機づけられた照明を基本として、ほとんど動機づけられていない照明を用いないからです。これは強みでもあり、弱点でもあります。非常にドラマチックな雰囲気を生むことができますが、その生成スタイルに固定されてしまいます。Better Daysだけを使っていると気づかないでしょうが、x/y比較テストを始めるとなおさらその傾向が顕著になります。
これがBetter Daysでシルエットが目立つ主な理由であり、光る目が素敵に見えるのは、実用的/動機づけられた照明を基本として、ほとんど動機づけられていない照明を用いないからです。これは強みでもあり、弱点でもあります。非常にドラマチックな雰囲気を生むことができますが、その生成スタイルに固定されてしまいます。Better Daysだけを使っていると気づかないでしょうが、x/y比較テストを始めるとなおさらその傾向が顕著になります。Q: でも
betterDaysIllustriousXL_V01ItercompCyberfixPerpWeightedSum05Squaredの照明はBetter Daysより悪くない?
A: その通りです。なぜならbetterDaysIllustriousXL_V01ItercompCyberfixPerpWeightedSum05Squaredは「過剰露出」しているからです。CyberrealisticやCyberillustriousは、現代のデジタルカメラで撮影された写真から学習した、現実的なモデルです。これらのモデルは自動補正機能を備えており、動機づけられていない照明の不足をカラーグレーディングで補正します。その逆が、現代の映画撮影が暗く見える理由です。明るく照明されたセットで撮影しつつ、暗さと影を演出するために「ブラックを潰す」からです。そうすると『ゲームオブスローンズ』S8E03のような映像になります。Q: なぜΣΙΗとマージしたの?
A: ΣΙΗには優れた内蔵アーティストタグがありますが、betterDaysIllustriousXL_V01ItercompCyberfixPerpWeightedSum05Squaredで過剰露出を引き起こしているブロックを置き換える必要がありました。両者をマージすることで、ΣΙΗの優れたアーティストタグと構図、および一部の照明向上を獲得しつつ、動機づけられていない照明も可能にしました。モデルマージとは、両モデルの長所と短所を平均化する作業であり、このケースでは主観的に、最終的なモデルは2つのモデルが失ったものを上回る成果を得たと考えます。Q: QLIPとは?
A: QLIP はNVIDIAが開発したトークナイザー/オートエンコーダで、画像の理解(タグや自然言語等の視覚認識)と再構成の両方に優れています。CLIPを使用する一部のモデルに差し替えて使用できますが、Noob-AIのCLIPは高度に微調整されているため、ここで使用するには、CLIP-GとQLIPの差分をNoobAIの微調整済みCLIPに適用する必要があります。Q: QLIPの効果は?
A: 私の観察では、QLIPはプロンプトの忠実度を大幅に向上させ、CLIP-G全体的に優れています。しかし、これは微調整済みCLIPに「マージ」されたものであり、内在的に訓練されたCLIPではないため、潜在空間の関連性が若干損なわれます。多くの画像では気づかないでしょうが、3人以上のキャラクターをプロンプトで指定し始めると、QLIPモデルはネイティブCLIPモデルに比べてより顕著に苦戦します。そのため、私はQLIPなしのプロトタイプ版もアップロードしました。ほとんどのプロンプトでは劣ると考えますが、一部のユーザーにとってはワークフローに適している可能性があります。Q: パニー?
A: いいえ。Q: Türkçesi?
A: (トルコ語でメッセージを送らないでください。私はトルコ語を理解できません。Google翻訳で作ったような破綻したピジン語で返信するしかないんです。)
(トルコ語でメッセージを送らないでください。私はトルコ語を理解できません。Google翻訳で作ったような破綻したピジン語で返信するしかないんです。)