Hunyuan Video T2V/V2V Flexible LoRA Workflow






詳細
ファイルをダウンロード
このバージョンについて
モデル説明
[最近の変更点]
v1.1 beta を v1.11 に更新しました。複数のLoRAをより適切にサポートできるように、ノードを新しいものに置き換えました。また、v2vグループ内の一部の幅と高さノードを修正し、解像度の調整を容易にしました。
+(v1.11) 出力ノードとデコードノード間の不正な接続の問題を修正しました。以前のバージョンをダウンロードした方は、再度ダウンロードしてください。
+ 最新版のComfyUIで問題が発生する可能性があります。InstructPixToPixConditioningノードに問題が発生した場合は、ComfyUI Managerで「Switch ComfyUI」を使用してv0.3.13にロールバックし、ComfyUIを再起動してください。
LoRAは状況に応じて動的に適用され、生成の異なる段階に合わせて調整できます。
これは私が実装したワークフローではありませんが、元の作者は、希望する場合はこのワークフローを私のアカウントでCivitaiにアップロードしても問題ないとしています。利便性のため、一部のノードを変更し、ここに共有しています。
Hunyuan Video用のほとんどのLoRAは現実の人間向けに学習されているため、2Dキャラクターに適用するとさまざまな問題が発生します。このワークフローでは、LoRAを異なる段階で適用することで、これらの問題を軽減できます。
私は主にアニメスタイルの動画生成にこのワークフローを使用していますが、リアルな人物の生成にも有効であると信じています。
- グループ名やノートに少し不自然な点がある場合は、私の英語力の問題です。ご理解いただければ幸いです。
ワークフローの2つのバージョンをアップロードしました:
Tea Cache と Wavespeed を含むバージョン
ComfyUIのコアノードのみを使用(環境によって問題が発生する可能性があるため、Tea Cache と Wavespeed を削除)
⚠️ Tea Cache と Wavespeed を含むバージョンは、一部の環境(特にTritonがインストールされていないWindows環境)で問題を引き起こす可能性があります。問題が発生した場合は、コアノードのみのバージョンをご使用ください。
結果を選び取っていませんので、説明はワークフローを修正した後に生成された画像に基づいています。
T2V生成の例:
同じプロンプト、同じシード、すべての設定を固定。
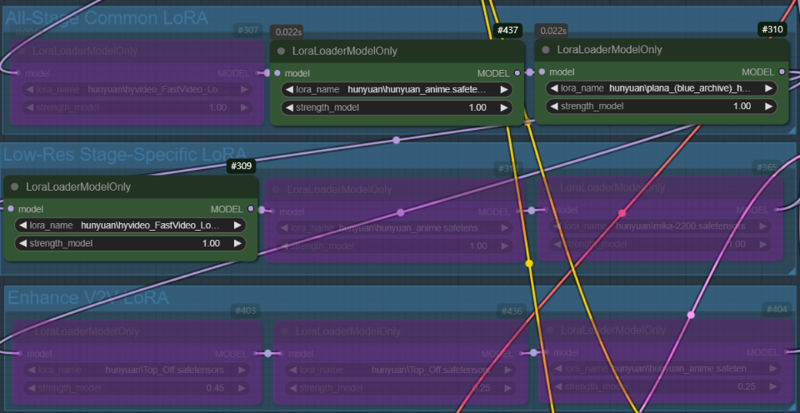
ケース1:キャラクターLoRAをすべてのノードに適用。低解像度段階では、高速LoRAとスタイルLoRAを適用し、Enhance T2V段階ではLoRAを適用しない(この段階では、すべての段階用LoRA(キャラクターLoRA)のみ適用)。
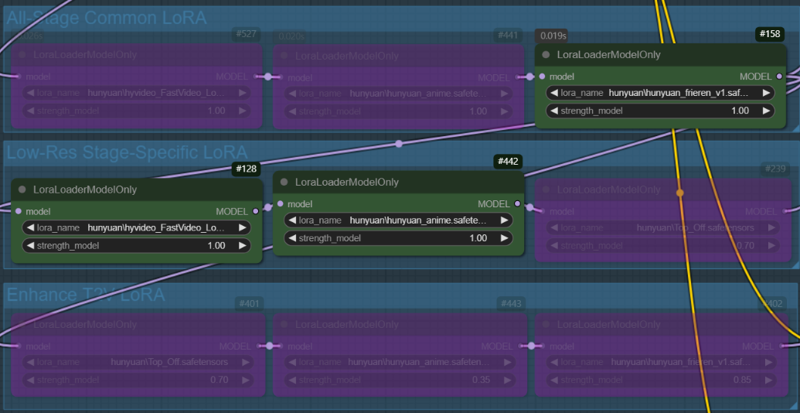

ケース2:ケース1で使用したすべてのLoRAをすべてのノードに適用
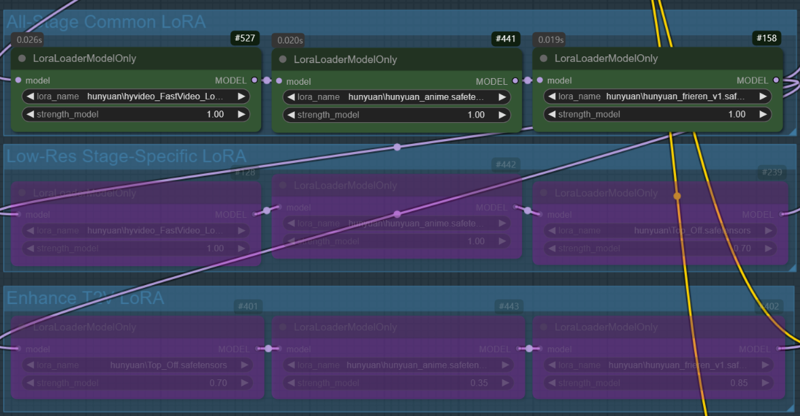

V2V生成の例:
同じプロンプト、同じシード、すべての設定を固定
V2Vの例では、T2V段階で作成された動画を使用します。(ケース1)
ケース1:キャラクターLoRAをすべてのノードに適用。高速LoRAとスタイルLoRAは低解像度段階のみに適用。Enhance V2V段階では、低解像度段階で使用したスタイルLoRAを減衰された重み(1→0.25)で適用。
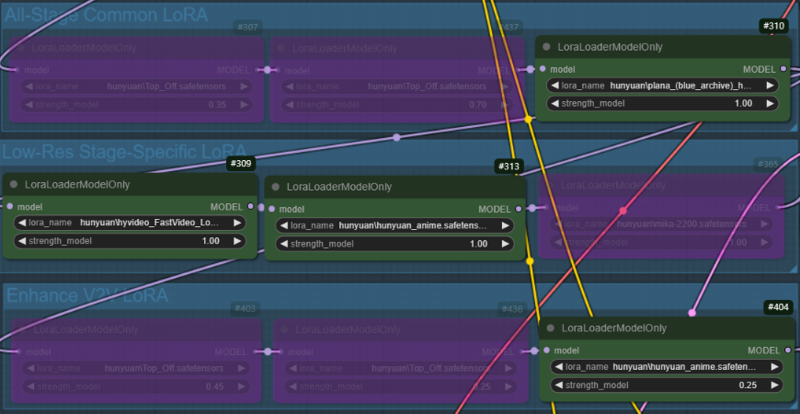

ケース2:ケース1と同じだが、スタイルLoRAの重みを1.0に固定。