[PVC Style Model]Movable figure model





















詳細
ファイルをダウンロード
このバージョンについて
モデル説明
AI生成PVC手办に関するリスク警告
尊敬するユーザー様:
AI生成PVC手办モデルへのご関心をいただき、誠にありがとうございます。不正な人物が本モデルのAI技術を悪用し、偽装宣伝や欺瞞的手法でユーザーの予約金を騙し取る事態を防ぐため、以下のように厳重に声明いたします:
本モデルはAI生成技術の学術的交流目的のみで使用されます
本手办モデルのAI技術は、PVC手办のデザイン原稿の生成にのみ利用され、实物の生産や販売には一切関与しておりません。無許可の販売を信じないでください:
本モデルのAI技術を使用して作成されたPVC手办を販売するいかなる行為も、公式に許可されていません。ユーザーの皆様は、詐欺に巻き込まれないよう十分に注意してください。リスク警告:
PVC手办の製作には、3Dモデリング、素材選定、型枠製作、射出成形、塗装など複数の工程が含まれ、各工程で品質問題が発生する可能性があります。PVC手办を購入する際は、必ず正規の販売チャネルを利用し、製品情報の確認を徹底し、関連証拠を保管してください。権利救済の提案:
本モデルのAI技術を悪用した詐欺行為を発見した場合は、直ちに関係当局に通報し、証拠を保存して法的責任を追及してください。画像がAI生成されたものかどうかは、以下のウェブサイトで判定可能です:
AI-Generated Content Detection | Hive (https://hivemoderation.com/ai-generated-content-detection)
温馨提示
あなたの権利を守るために、PVC手办を購入する際は以下の点にご注意ください:
- 正規のチャネルを選んでください:有名なメーカーまたは評判の良い販売店での購入を推奨します。
- 製品情報を確認してください:素材、寸法、製造工程などの情報を仔细に確認し、高解像度画像を参照してください。
- 領収書を請求してください:後日の権利救済のために、正式な領収書を発行してもらうようにしてください。
- チャット履歴を保存してください:販売者とのやりとりは、必要に応じてチャット記録を保存してください。
- AI技術による判断を使用してください:見たことがない疑わしい手办に遭遇した場合は、以下のウェブサイトに画像をアップロードして判定してください:
AI-Generated Content Detection | Hive (https://hivemoderation.com/ai-generated-content-detection)
免責事項
本モデルが無許可の第三者によってAI技術が商業的に悪用された場合、当方には一切の責任を負いません。ユーザーの皆様は、ご自身で判断し、慎重にご購入ください。
4.0バージョンは中距離~近距離のシーンで質感効果が最適です。中距離~近距離ではフェイシャル修復プラグインをオンにする必要はありません。4.0バージョンは手や指の部分に若干の最適化が加えられています。
- The 4.0 version has the best texture effect for medium and close range scenes, and there is no need to open the facial repair plugin. The 4.0 version slightly optimizes the hand and fingers
注意‼️必ず私が推奨するパラメータを使用してください
take care ‼️ Be sure to use my recommended parameters
新バージョン推奨パラメータ(The new version of the recommended use parameters)
推奨パラメータ(Recommended parameter):
サンプリング方法(Sampler):
Euler :20~30ステップ
Euler a:20~30ステップ
プロンプト誘導係数(CFG Scale):3~7
人物画像解像度(Character resolution):512x768、768x768、512x1024
高解像度修復(Hires.fix):
拡大アルゴリズム(Amplification algorithm):Latent、4x-UltraSharp
否定的プロンプト推奨(Negative):(low quality,simple background,worst quality:1.4),(bad anatomy),(inaccurate limb:1.2),head out of frame,bad composition,inaccurate eyes,extra digit,fewer digits,(extra arms,grey background:1.2),(watermark,text,logo,username,multiple moles,mole on body:1.2),
Latent設定を使用する場合(Using Latent Settings)

4x-UltraSharp設定を使用する場合(Use the 4x-UltraSharp setting)
高解像度イテレーションステップ(High number of iteration steps):10~15
推奨パラメータ設定(Recommended parameter setting)
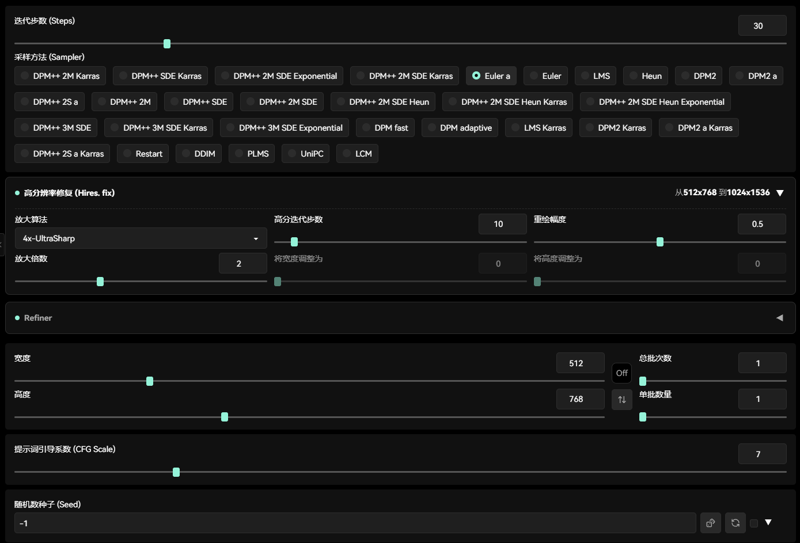
リドロー幅(Redraw amplitude):0.3~0.5
Clip Skip:2
上記以外のパラメータは前バージョンを引き継いでください(The above mentioned parameters are used in a previous version)
-----------------------------------------------------------------------------------------
モデルの適用シーン Model application scenario
1. 本モデルは2D、2.5D、3D、スタイルLoRAと組み合わせて、PVC素材風のキャラクターやアイテムを直接生成できます(他のモデルと同様の使用方法です)
- This model can be used with 2d, 2.5d, 3d, and style lora straight PVC material style characters and objects (this is the same as other models)
2. 特定シーンのスタイル変換
本モデルは、2D、2.5D、3D画像をPVC素材風に変換できます。これは特定スタイルのブランド設計や製品デザインのビジュアルデザイン画像をPVC素材風に変換する用途に適しています。
Style conversion of specific scenes
This model can convert 2d, 2.5d, 3d pictures into PVC material style. This model can be applied to the pictures of specific style brand design and product design visual design to convert PVC material painting style
2.0バージョン推奨パラメータ(This parameter is recommended for version 2.0)
推奨パラメータ(Recommended parameter):
サンプリング方法(Sampler):
Euler :20~30ステップ
Euler a:20~30ステップ
Restart:15~20ステップ
DDIM:30ステップ以上
プロンプト誘導係数(CFG Scale):3~7
人物画像解像度(Character resolution):512x768、768x768、512x1024
高解像度修復(Hires.fix):
拡大アルゴリズム(Amplification algorithm):R-ESRGAN 4x+Anime6b、4x-UltraSharp、4x_SmolFace_200k
高解像度イテレーションステップ(High number of iteration steps):10~15
リドロー幅(Redraw amplitude):0.3~0.5
Clip Skip:2
否定的プロンプト推奨(Negative):(low quality, worst quality:1.4),(bad anatomy),(inaccurate limb:1.2),bad composition,inaccurate eyes,extra digit,fewer digits,(extra arms:1.2),(watermark,text,logo,username,multiple moles,mole on body,:1.2),
以下は特定シーンでの画像変換方法です
- Here is how to convert images from scene to scene
スタイル変換したい画像をControlNetプラグインの1ページに配置します。例:
- Put the image you want to change style on page 1 of the ControlNet plugin for example
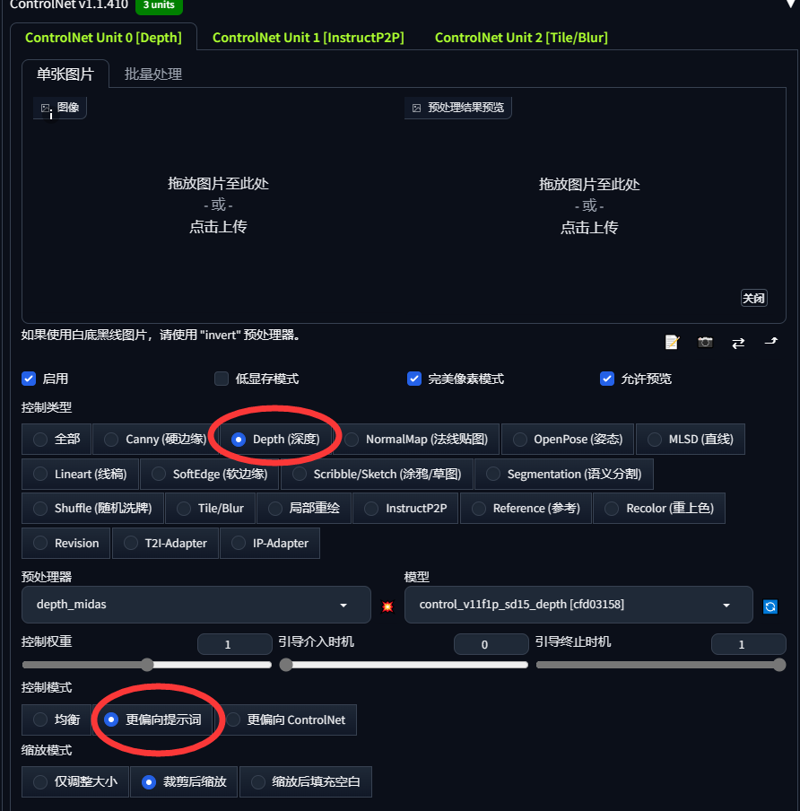
ステップ1:この人物は他のモデルで作成された画像で、私はこの人物のLoRAモデルを持っていません。画像のみを手办スタイルに変換する場合、この画像をControlNetプラグインの1ページ(unit0)に配置し、ディープマップを選択します
- The first step is for example this figure this figure is a drawing made by another model I don't have I don't have a lora model of this figure just by converting the image to hand-style we put this image on the first page of the ControlNet plugin which is unit0 select the depth map

次に「パーフェクトピクセル」にチェックを入れ、爆発アイコンをクリックして実行します
- Then check the Perfect Pixel and click on the explosion icon and run
ステップ2:2通りの方法があります。まず最初の方法を説明します。上記の画像はSD直接出力の元画像です
- The second step is divided into two types and I'll talk about the first one which is the original image of the SD straight map

元画像がある場合、画像をPNG情報抽出に載せ、正面プロンプトのみを抽出します
- If there is an original image, you only need to put the image into PNG information extraction and extract the image prompt words

フレームで囲った部分だけを抽出し、抽出したプロンプトをテキスト→画像に挿入します
- We just need that one area of the frame and put the extracted tips into the Vincennes diagram
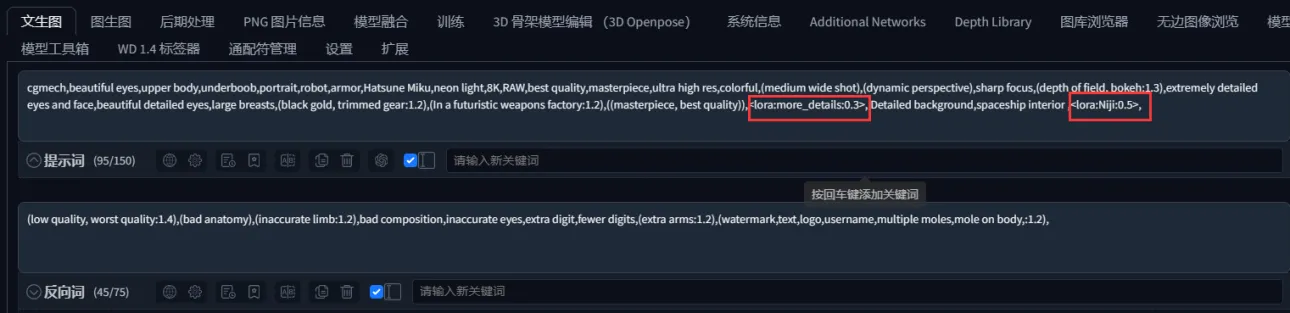
LoRAは削除してください。このLoRAは私たちが持っていないため、有無に関わらず同じです。削除して「生成」をクリックしてください**
- Lora remove because this lora we do not have him or not he is the same suggest delete and click Generate

次に2番目の方法ですが、前回の方法と同様で、画像がSD直接出力ではなく、画像情報が保存されていないモデルの場合、画像を画像→画像に配置します。例:画像にタグがなく、画像→画像に配置します
- And then the second method is similar to the first one which is that the image is not SD straight out and the model that doesn't keep the image information is to put the image inside the graph generation diagram for example if I find a graph that has an image without a tag let's put the image behind the graph generation diagram
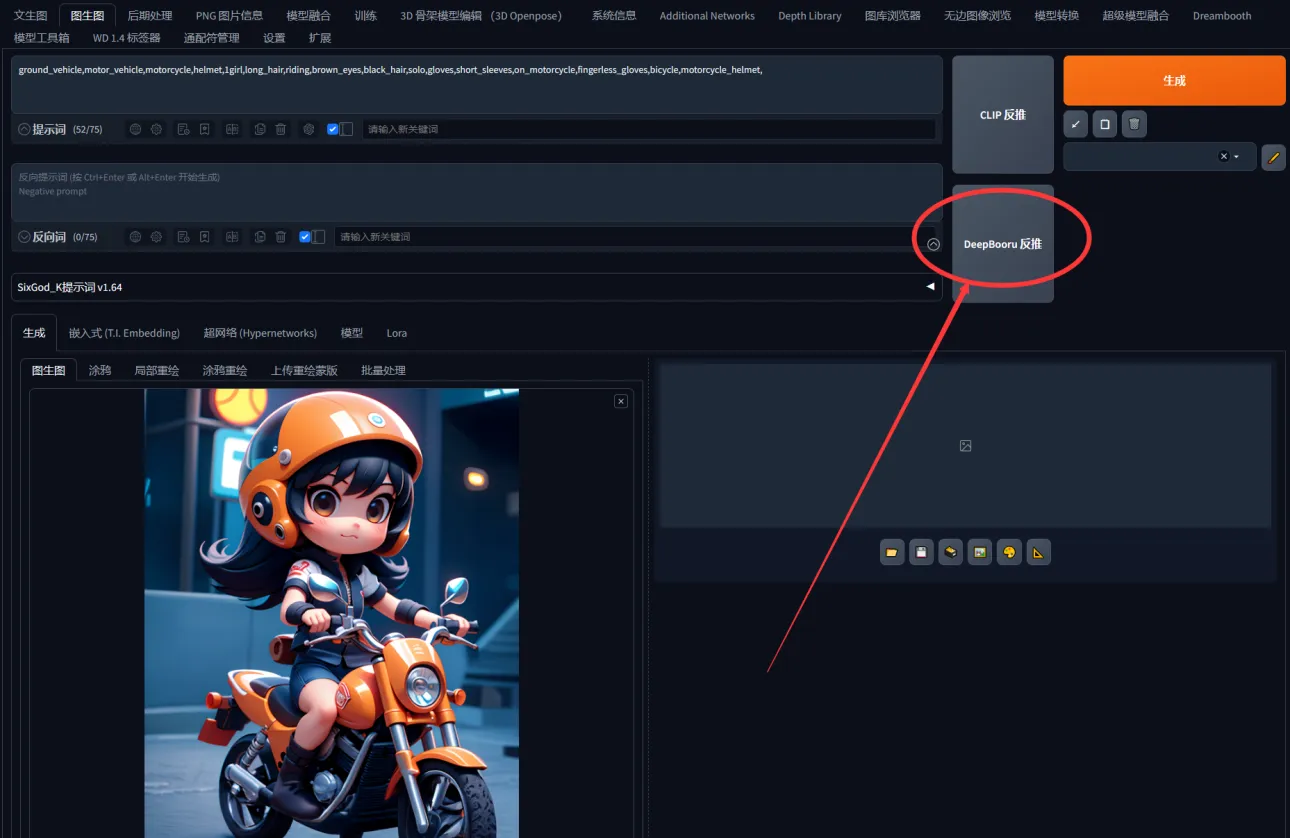
DeepBooruをクリックして逆プロンプトタグを抽出し、それをテキスト→画像にコピーして貼り付けます
- Click on DeepBooru to reverse push and you'll get the backpushed tag and then copy and extract the tag into the Vincennes diagram

その後、前の手順を繰り返します。この画像をControlNetプラグインの1ページ(unit0)に配置し、ディープマップを選択します
- Then repeat the previous steps we put this image on the first page of the ControlNet plugin which is called unit0 to select the depth map
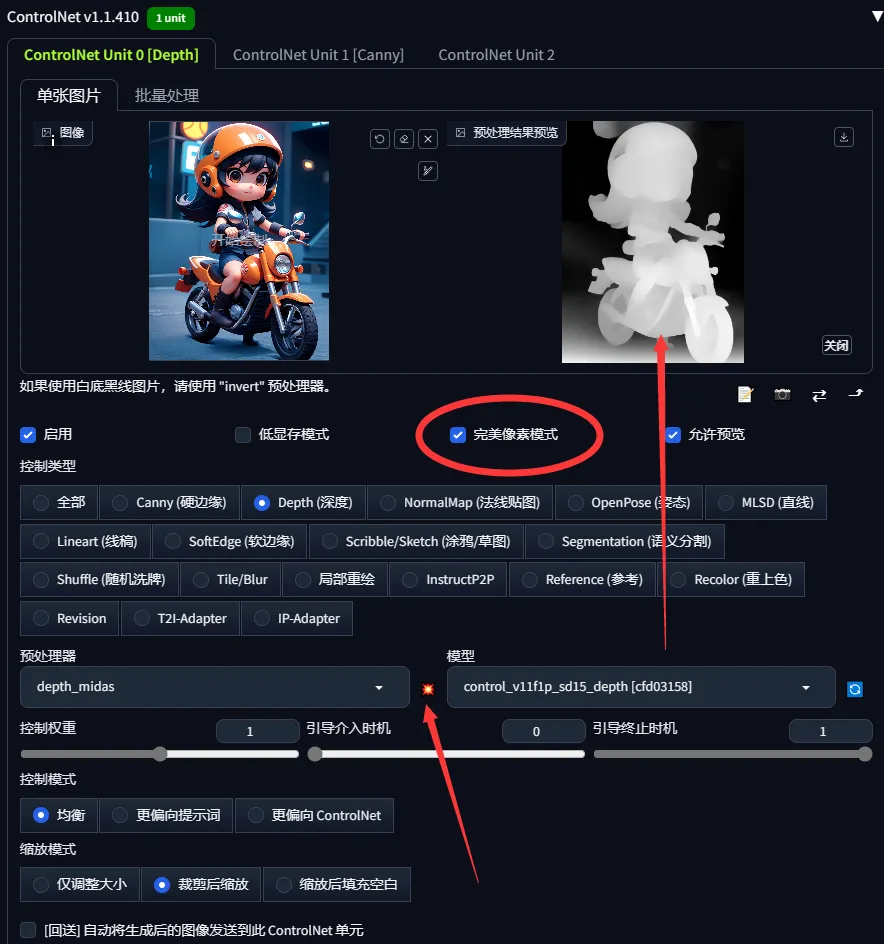
「パーフェクトピクセル」にチェックを入れ、爆発アイコンをクリックして実行し、ディープマップが生成されたら「画像生成」をクリックしてください。以下が結果です
- Then click on the Perfect Pixel and click on the explosion icon and run the depth map and then click on the raw image below to see the effect

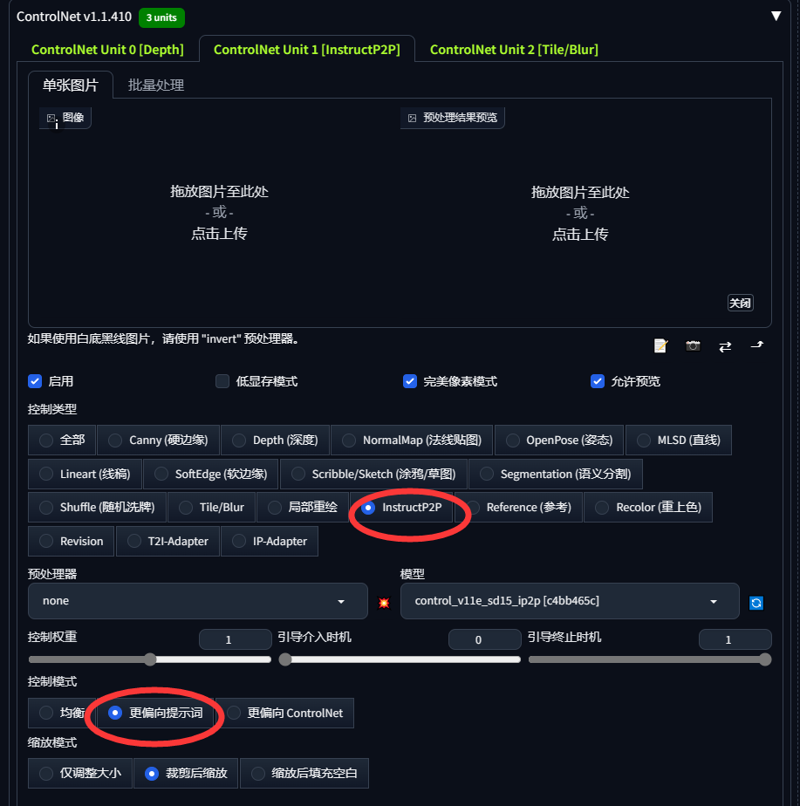
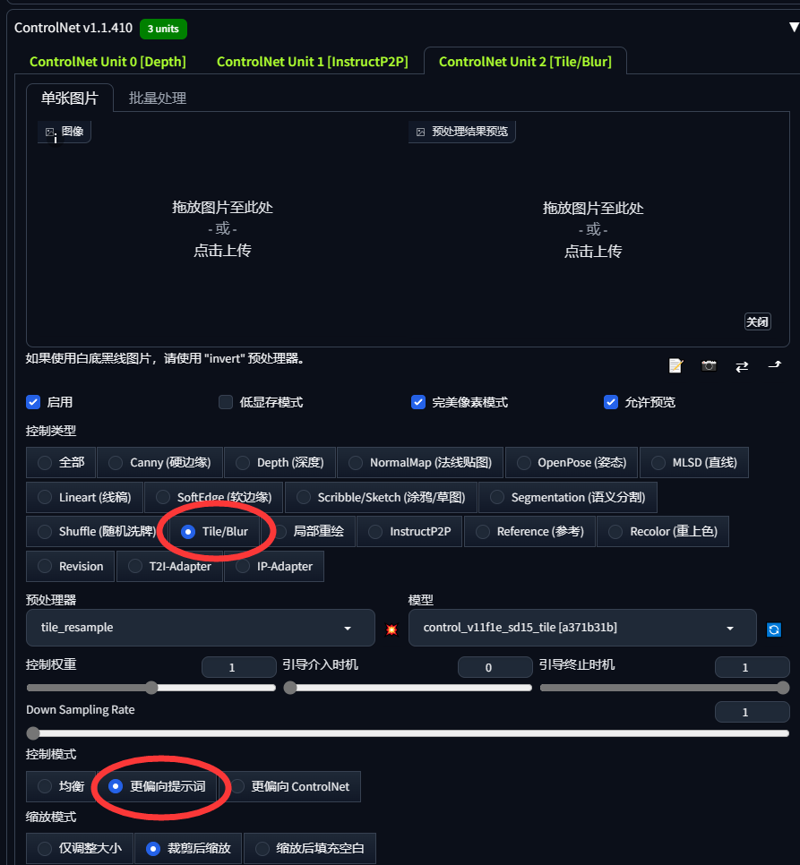
多くのシーンではControlNetのディープマップのみを使用しますが、特定の細部を再現したい場合は、ControlNet unit1、unit2に**Canny(硬エッジ)、Lineart(線画)、SoftEdge(柔らかいエッジ)などの追加プラグインを組み合わせて画像の質を向上させることができます
- Most scenarios only need the ControlNet depth map. In some scenarios, if you want to restore some details, you can add other plug-ins in ControlNetunit1, unit2, such as Canny (hard edge), Lineart (line draft), etc. SoftEdge (soft edge) and the like to assist the image effect
以下は私が個人的に画像マットに使用しているControlNetプラグインのパラメータです
- I am sending the parameters of the ControlNet plugin for my personal map
私が使用するプロンプト
- I pad use prompt
(masterpiece, best quality, unity 8k wallpaper, highres, absurdres, background)
間に逆プロンプトを挿入します
- Add a push-back prompt in the middle
(NSFW:0.8),
画像のソースとトレーニングコードはインターネットから取得しており、本モデルは学術的・研究目的でのみ使用されます。著作権侵害の場合は、お手数ですが連絡の上削除してください。ありがとうございます。
The image source and training code are from the Internet, and the model is only used for scientific interest exchange. If there is infringement, please contact to delete, thank you.------------------------------------------------------------------------------------------
v1.0使用推奨( v1.0 Recommendations of use):
他のLoRAと本モデルを組み合わせる場合、LoRAの重みは約0.8程度を推奨します。人物にPVC素材風が反映されていない場合は、LoRAの重みをさらに低くしてください。
It is suggested that the weight of lora should be around 0.8 when using other LORAs with this model If the character does not have PVC material, put the weight of lora lower
推奨スタートプロンプト(Suggest a hand):
best quality,masterpiece,realistic,HDR,UHD,8K,best quality,masterpiece,Highly detailed,ultra-fine painting,physically-based rendering,extreme detail description,Professional,1girl,
出力画像がぼやけている場合は、Ultimate SD upscaleで拡大することをお勧めします。
If the output is not very good, it is recommended to use Ultimate SD upscale amplification
------------------------------------------------------------------------------------------
推奨パラメータ(Recommended parameters):
サンプリング方法(Sampler):
Euler a:20~30ステップ。
DPM++ 2S a Karras:25~30ステップ。
DPM++ SDE Karras:20~30ステップ。
DPM++ 2M SDE Karras:20~40ステップ。
プロンプト誘導係数(CFG Scale):7
人物画像解像度(Character resolution):512x768、768x768、512x1024
高解像度修復(Hires.fix):
拡大アルゴリズム:R-ESRGAN 4x+Anime6b、4x-UltraSharp、4x_SmolFace_200k
高解像度イテレーションステップ:10~15
リドロー幅:0.3~0.5
Clip Skip:2
否定的プロンプト(Negatives):(worst quality, low quality:2),monochrome, zombie, (interlocked fingers:1.2),
------------------------------------------------------------------------------------------
- モデルに関するフィードバックは、内線メッセージでお送りください
画像のソースとトレーニングコードはインターネットから取得しており、本モデルは学術的・研究目的でのみ使用されます。著作権侵害の場合は、お手数ですが連絡の上削除してください。ありがとうございます。