Shidoshi Fun Mix




















详情
下载文件 (1)
关于此版本
模型描述
Added version 1.9. Someone requested 1.2, but I think this one is better. This is a pruned model. Read more:
Same advice as version 1.0 (read below). Images were generated using Vladmandic's SD.Next (updated daily, latest features and much faster than A1111).
I find with these mixes, less is better and tuning the prompts once you have something close. Adding a 100 word negative prompt usually makes it look like crap. Same goes with the positive prompt. Adding too much strength to stuff like, "(8k, absurdres, WOW, INCREDIBLE DETAIL, Nikon DS500 120 gigapixel:1.8)", will also make it look like crap.
I start with "Masterpiece" in the positive prompt and "(worst quality:2.0), (low quality:1.8), (normal quality:1.6)" in the negative prompt.
This model is semi-realistic, so I don't think adding camera models will make it look better? Try it... I don't know.
I also I tried the online generator supplied by civitai. Output is garbage. Recommend generating locally on your own GPU.
Also if anyone wants the full float of this for their own mixing purposes, I'll upload it.
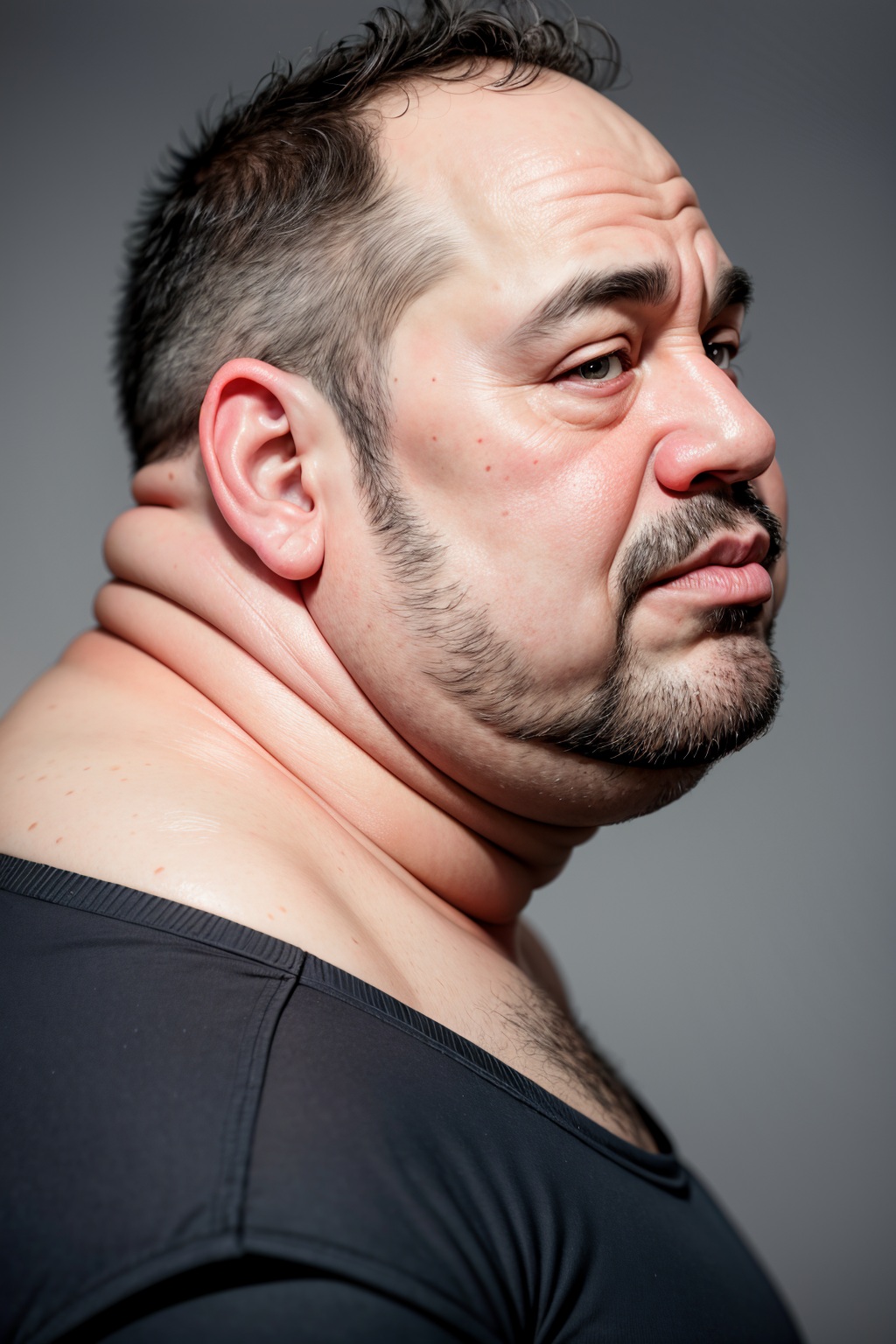
So, I decided to make a mix new model (non-SD XL). I guess it's what you'd call a semi-realistic model.
It's based off my original Shidoshi mix, added some of PSoft's lora's (fat man, ugly man, etc... Best loras on here), added some other hentai models using training difference add, mixed some more, and so on.
I think the result is "fun". So I called it "Fun Mix".
Try it out and post some samples.
No VAE burned in. Use vae-ft-mse-840000-ema-pruned.
Some advice:
Recommended neg: (worst quality, low quality, normal quality:1.8) -- Try different strengths. i.e. 1.4, 1.6, 2.0. Also for 1.9: (worst quality:2.0), (low quality:1.8), (normal quality:1.6), (stepping it seems like it has better results).
Sampling: I use DPM++ 2M SDE on first pass (30 steps). I follow up on second pass/ hires fix using DPM++ 2M SDE Karras with higher steps.
Clip skip: Either 1 or 2. 1 Works fine.
CFG scale: Keep low. 6-8. Oversaturation occurs at 9.5+ or use "Dynamic Thresholding". v1.9 Seems to work at 11.0+ at times.
Thanks and enjoy. I like feedback and post some samples!