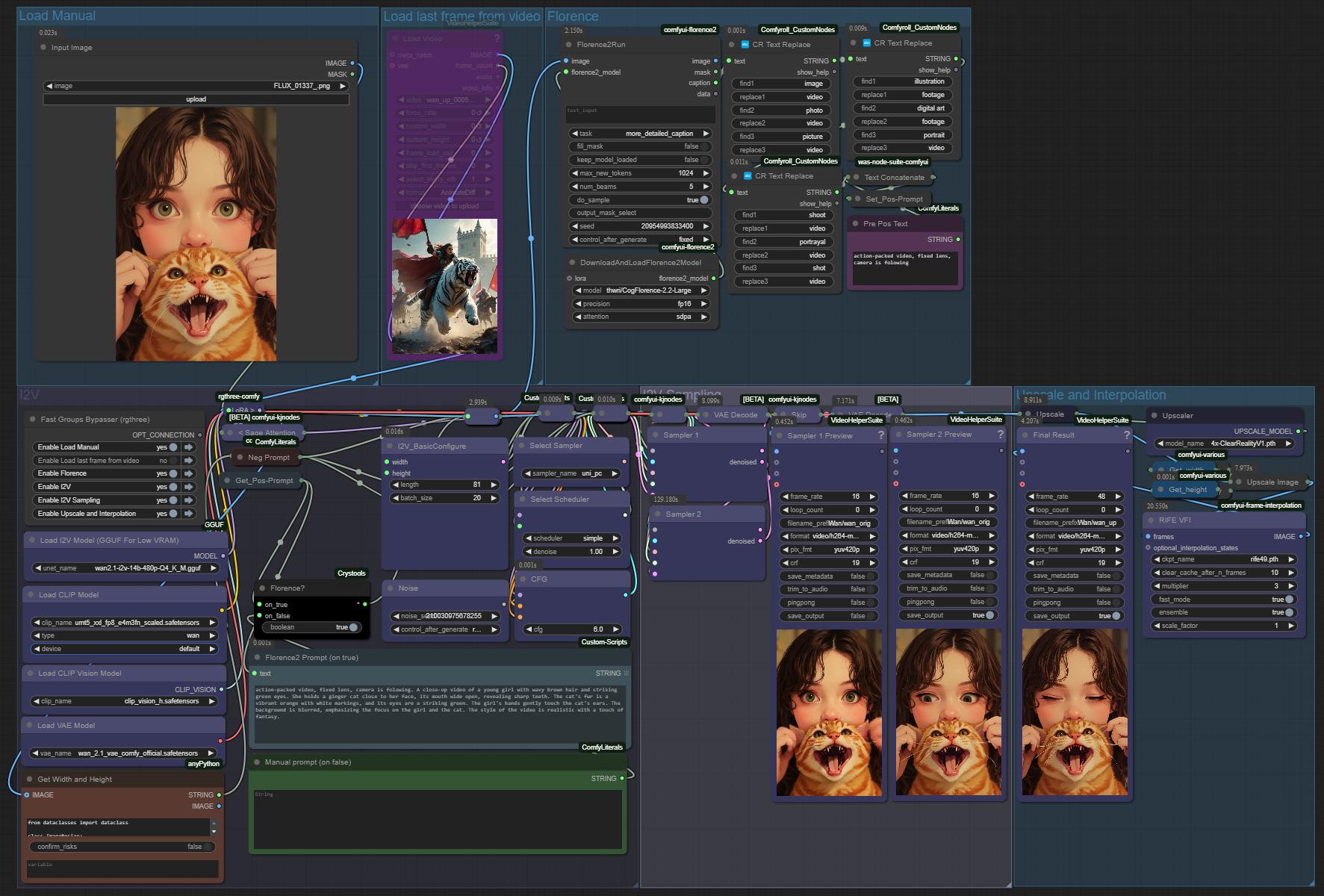
Wan Video Image To Video workflow + upscaler + interpolation + Florence2

详情
下载文件 (1)
关于此版本
模型描述
For v1.0
For v2.0
1) I2V Quant Model -> models/diffusion_models
2) CLIP VISION -> models/clip_vision
3) VAE -> models/vae
Prompt can write Florence2 LLM (workflow has toggle between Florence2 and manual user prompt).
Tested on 4080 16GB
v2.0 dev in development. If you have problems with AnyPython node, you should switch the channel recent or/and lower security_level (normal- OR weak) in the ComfyUI/Custom_nodes/ComfyUI-Manager/config.json