Hunyuan I2V (Image to Video) - Simplest / 12Gb VRAM - Full HD

Details
Download Files (1)
About this version
Model description
I present you the simplest Hunyuan I2V (Image to Video) ComfyUI workflow, which is very easy to understand and learn for beginners.
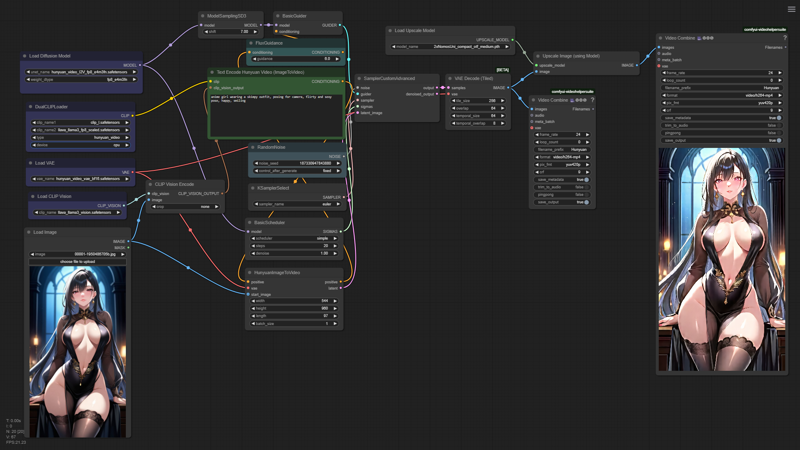 This workflow can easily be extended with additions like auto-prompting or frame interpolation, but for simplicity and ease of understanding I won't add those nodes here...
This workflow can easily be extended with additions like auto-prompting or frame interpolation, but for simplicity and ease of understanding I won't add those nodes here...
My low VRAM (12Gb only...) trick is hidden in the initial video resolution of the generated video (exactly half of full HD: (1920/1088)/2 = 960/544) and then upscaling it with a 2x model trained to recover low resolution images/videos.
You can get one of those models here: https://openmodeldb.info/users/helaman - in my case you can see this one: https://openmodeldb.info/models/2x-NomosUni-compact-otf-medium
I'm also running the workflow partially as fp8_e4m3fn, using the quantized version of Hunyuan Video by Kijai, adding two additional switches to the CimfyUI command line: --fp8_e4m3fn-unet --fp8_e4m3fn-text-enc, and selecting the weight type of the diffusion model loader as fp8_e4m3fn (+ I'm turning on the adwanced option in the DualClipLoader node to send it to the CPU instead of the GPU memory).
The output file you might consider cropping the extra few pixels from 1088 to 1080 for a pure 9x16 aspect ratio. If you need horizontal video - just flip the numbers in the corresponding node ;)
Disclaimer: This workflow is a modification of the official ComfyUI example from here: https://comfyanonymous.github.io/ComfyUI_examples/hunyuan_video/
Good Luck making awesome vids ;)