80's porn centerfold

詳細
ファイルをダウンロード
このバージョンについて
モデル説明
ただの楽しい小さなLoRA実験で、思わずあまりにも多くの時間を費やしてしまいました。これは元々一度きりの試しで終わらせるつもりだったのに、3回もトレーニングしてしまいました。でも、その過程でかなりの知識を得られました。
1980年代のポルノ中心ページモデルの54枚の静止画像でトレーニングしました。目的は以下の2点です:1. 当時の人々の女性の一般的な外見、2. 当時のポルノ雑誌で使われていた動画・写真の照明と雰囲気を捉えること。
このLoRAは、急いで作成したサイドプロジェクト(あるいはそうするつもりでした)でしたが、十分な成果を出していると思います。
静止画像のみを使用したため、このLoRAはフレーム数が多い場合、うまく動作しません。最適なフレーム数は89です。121フレームでは動きはありますが、弱まります。145フレームになるとほぼ常に静止画像しか生成されません。無駄な時間を過ごさないでください。
キャプションは非常にシンプルでした:
A 1980's porn centerfold woman
上記のプロンプトに、何らかの一般的なポーズや場所を追加すれば、LoRAは十分に髪の毛が豊かな(頭にも下部にも)女性を生成してくれます。
試してみて、楽しんでください。
トレーニングデータに興味がない人は、ここで読み止めてください。
V1 - 8エポック、学習率(LR)8e5で、1600ステップを目標にトレーニングしました。
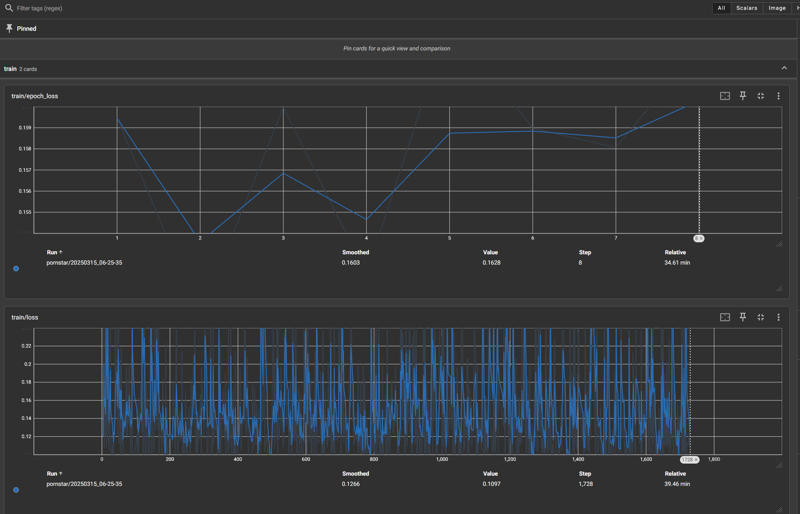
損失グラフを見ると、エポック2で急激に低下した後、エポック4で再び上昇しゆっくりと低下し、エポック5〜8で過学習が顕著に進行しました。
V2 - 前回の結果をすべて破棄し、過学習を防ぐために学習率7e5で10エポックトレーニングしました。
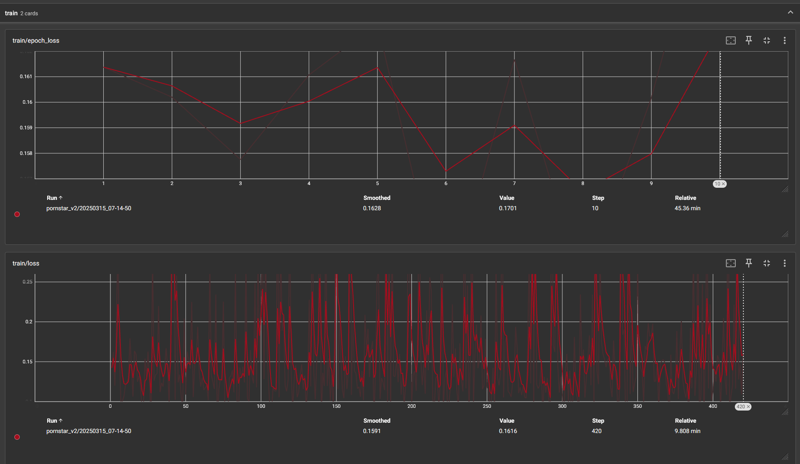
低い学習率はより良い結果をもたらしましたが、エポック6での低下は非常に急でした。その後再び上昇し、再び低下した後、徐々に過学習へと向かいました。
エポック6と8の間でテストしたところ、エポック8の方がプロンプトへの準拠度が高く、トレーニングされたテーマに対する整合性もより優れており、動きへの悪影響も目立たなかったのです。このテスト中の推論で、高フレーム数での動きの低下に気づきました。
V3 - 実験として、キャプションの先頭に「An image of...」を追加し、それまでの設定と同じでトレーニングしました。Discordで、この方法によりモデルが静止画像を元に概念を学習していることを理解し、過学習LoRAが動きに対して示す抵抗を軽減できる可能性があると読みました。
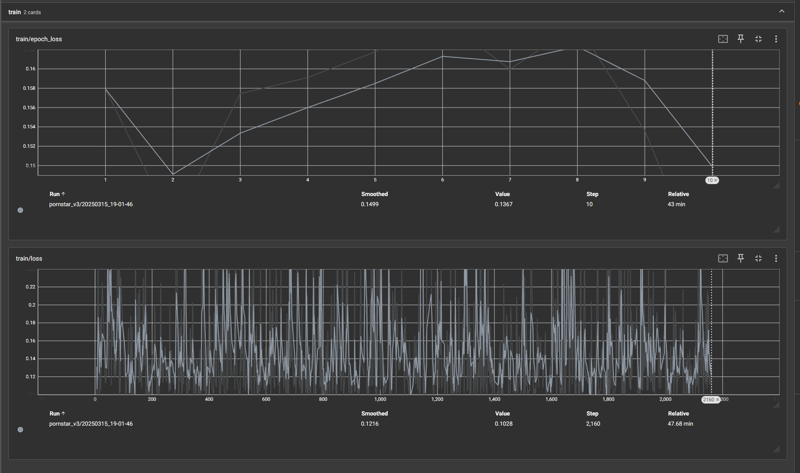
このケースでは、損失の低下が速く安定的で、その後ゆっくりと過学習が進行し、再び長くゆっくりと低下する曲線を描きました。テストした結果、V3のエポック2と10のLoRAは整合性が低く、V2のエポック8と比べてアーティファクトが大幅に増加しました。
したがって、私はV2のエポック8を最良の結果と選びました。
これは、少なくとも私の観点から、LoRAトレーニングにおけるキャプションの重要性を示しています。「an image of」と「a video of」の使用は、画像と動画の両方を含むデータセットでは意味がありますが、単一メディアのみの場合は必ずしも必要ではありません。
もう一つの教訓は、損失がわずかに上昇した後でもエポックを放棄しないことです。その次エポックが依然として有用な場合があります。
最終的な教訓は、トレーニング中に損失が中間で上昇した場合は、学習率を下げて安定化を図ることを試みてみてください。