区域绘制工作流-Regional Prompter workflow—Densediffusion+Controlnet


















詳細
ファイルをダウンロード
このバージョンについて
モデル説明
英語が得意ではありません!英語が苦手な場合の警告!
注意:複数のキャラクター+他のLoRAを使用する場合、1回のアップスケールでは良い結果が得られない可能性があります。私のワークフローのように、アップスケール後にKサンプラーを1回追加して生成する方が最適です。(元のモデルでも可能だと思いますが、私は別のモデルを使用しています。生成やアップスケールでエラーが発生した場合、ほとんどの原因は解像度設定にあります。64の倍数に設定してください。)
ここで共有しているすべての画像は元画像です。ComfyUIにドラッグしてタグやその他の情報を確認できます。
ヒント:複数のLoRAモデルを用いて複数のキャラクターを生成する際、単一のアップスケール処理では最適な結果が得られないことがあります。私のワークフローに従って、まずアップスケールを行い、その後Kサンプラーを接続して最終生成を行うのがベストです。
エラーメッセージが表示された場合、解像度設定が原因である可能性が高いです。解像度は64の倍数に設定してください。
ここで共有しているすべての画像は元画像です。ComfyUIにドラッグしてタグやその他の情報を確認できます。
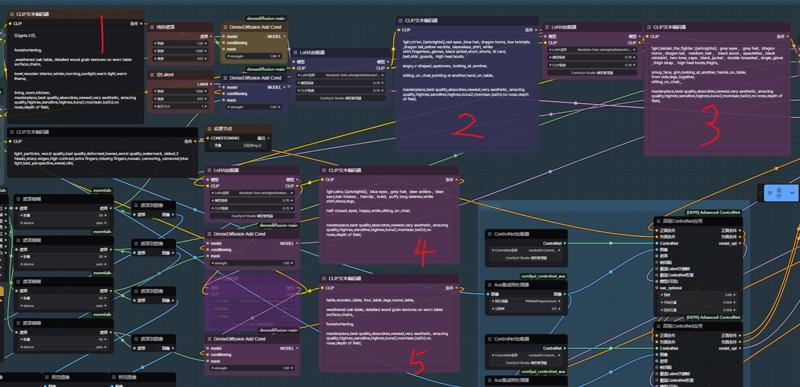
2.0 更新: デフォルトのレンダリング領域を4つに拡張しました。必要に応じて追加または無効化できます。実際の使用体験に基づき、構図の安定化のためにControlNetの深度(Depth)とタイル(Tile)ノードをワークフローに追加しました。
2.0 Update: デフォルトのレンダリングゾーンを4つに拡張し、使用要件に応じて追加または無効化が可能になりました。
経験的最適化の結果、画像のアップスケール処理を安定させるために、ControlNetの深度(Depth)とタイル(Tile)ノードを処理フローに組み込みました。
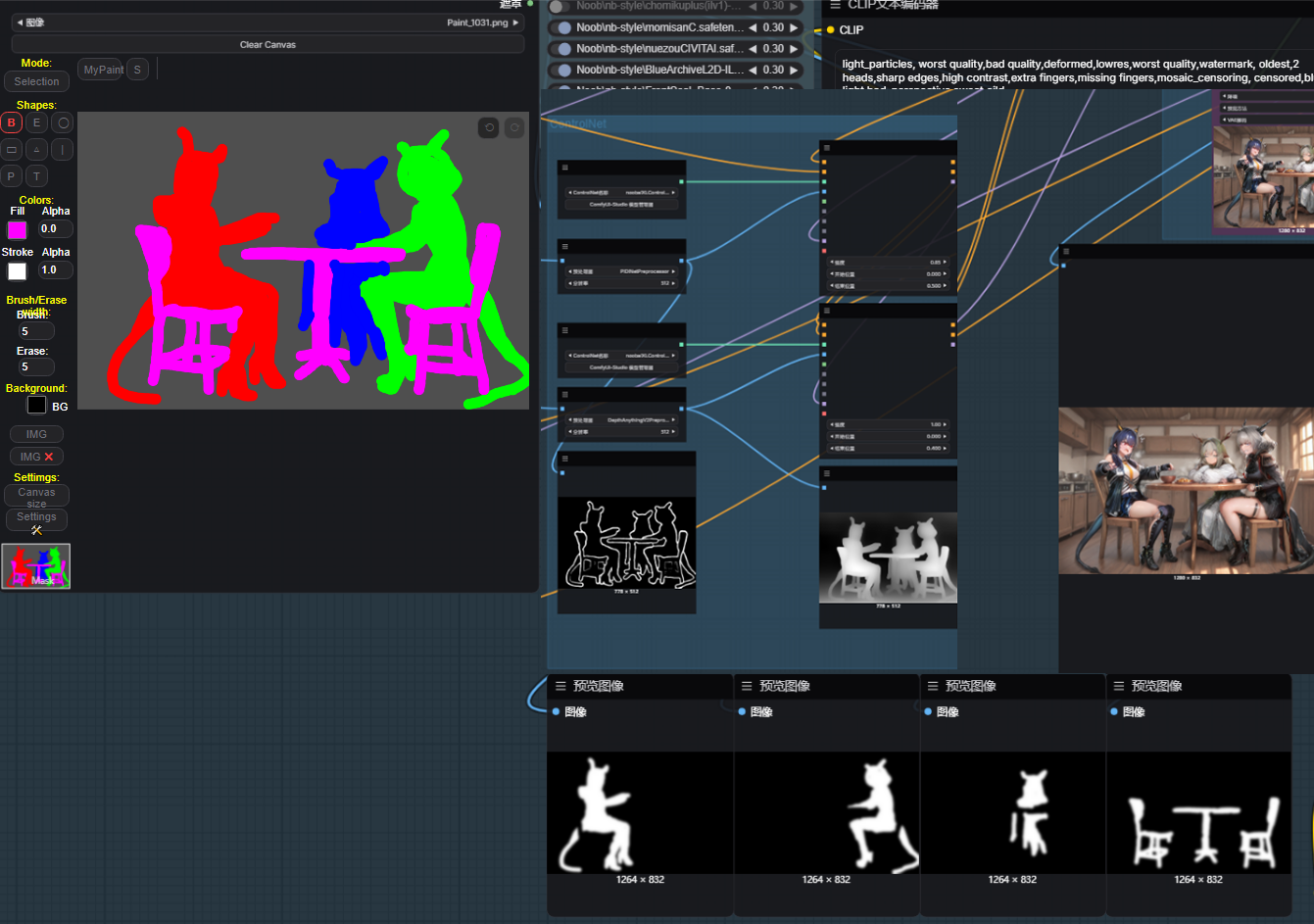
1: 最初の領域には大まかな構図タグを記入します。たとえばこの画像では、メイン被写体を明確に指定:3girls、シーン:living_room, kitchen, wooden interior, winter, morning, sunlight など。必要に応じて、視点タグ(上から、下からなど)も追加できます。
1: 最初の領域には大まかな構図タグを記入します。たとえばこの画像では、メイン被写体を明確に指定:3girls、シーン:living_room, kitchen, wooden interior, winter, morning, sunlight など。必要に応じて、視点タグ(上から、下からなど)も追加できます。

2、3、4 の領域には、前段のLoRAノードに生成したいキャラクターのLoRAを追加してください。各領域内のテキストは、生成したいキャラクターのトリガーワードと、望むアクション内容です。
2、3、4 の領域には、前段のLoRAノードに生成したいキャラクターのLoRAを追加してください。各領域内のテキストは、生成したいキャラクターのトリガーワードと、望むアクション内容です。
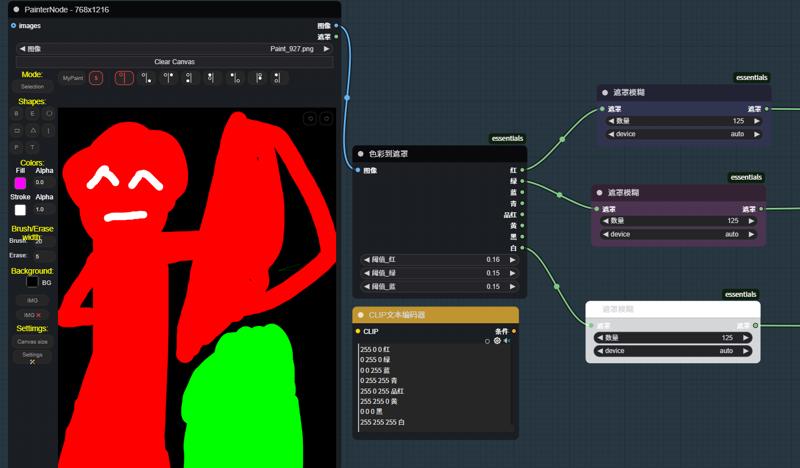
5: ここではシーン生成の補助として、ピンクのマスクでテーブルと椅子を描き、その領域のタグには「table and chair」とだけ記入しています。
5: ここではシーン生成の補助として、ピンクのマスクでテーブルと椅子を描き、その領域のタグには「table and chair」とだけ記入しています。

生成結果を見てみると、あまり良くなさそうですね… はい、この段階でローカル再生成を使用します。
生成結果を見てみると、あまり良くなさそうですね… はい、この段階でローカル再生成を使用します。

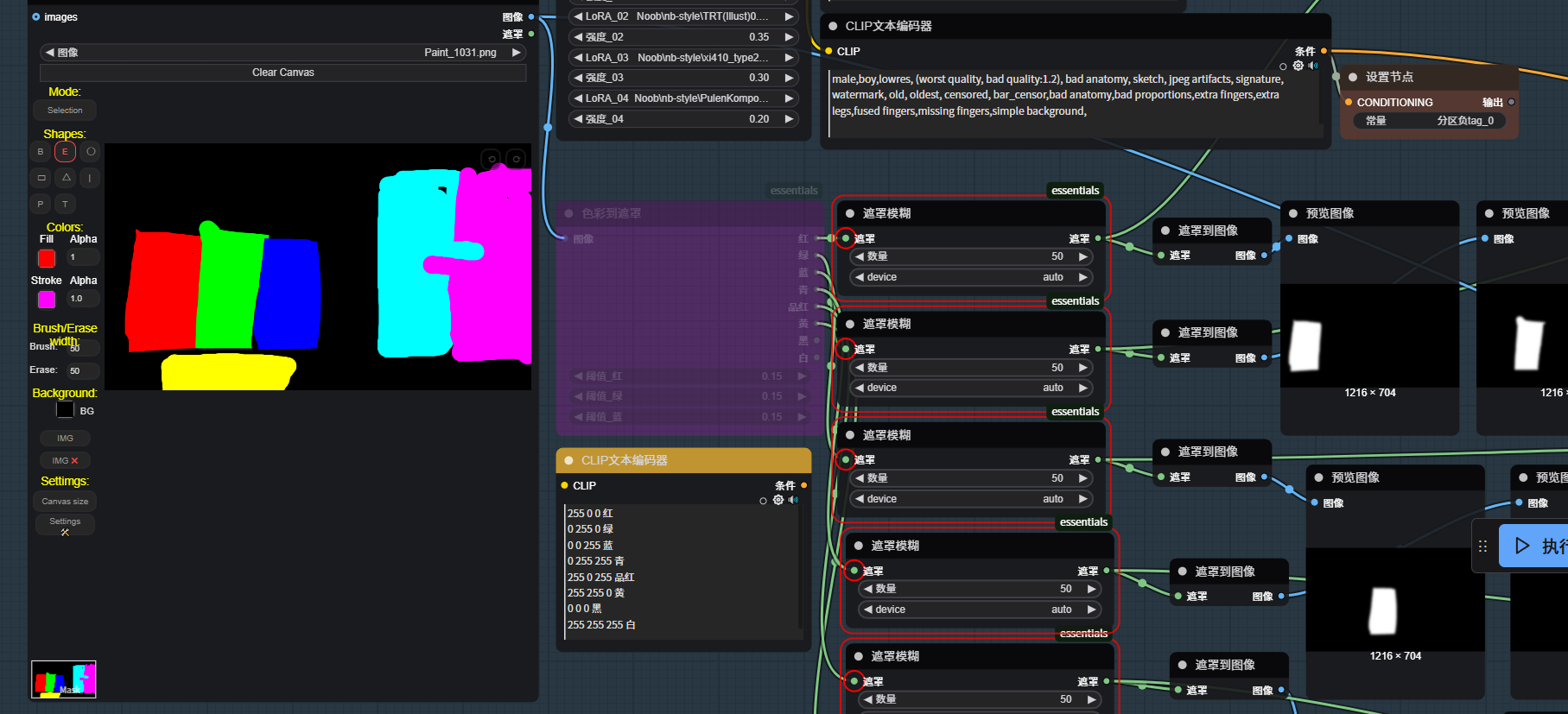
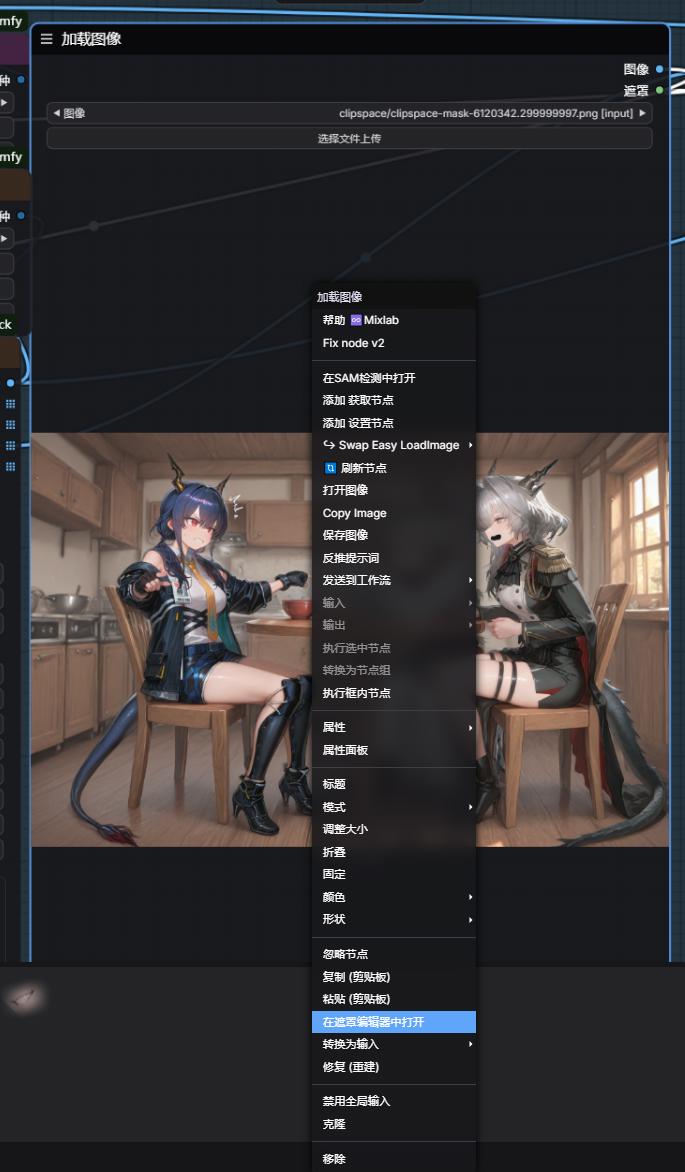
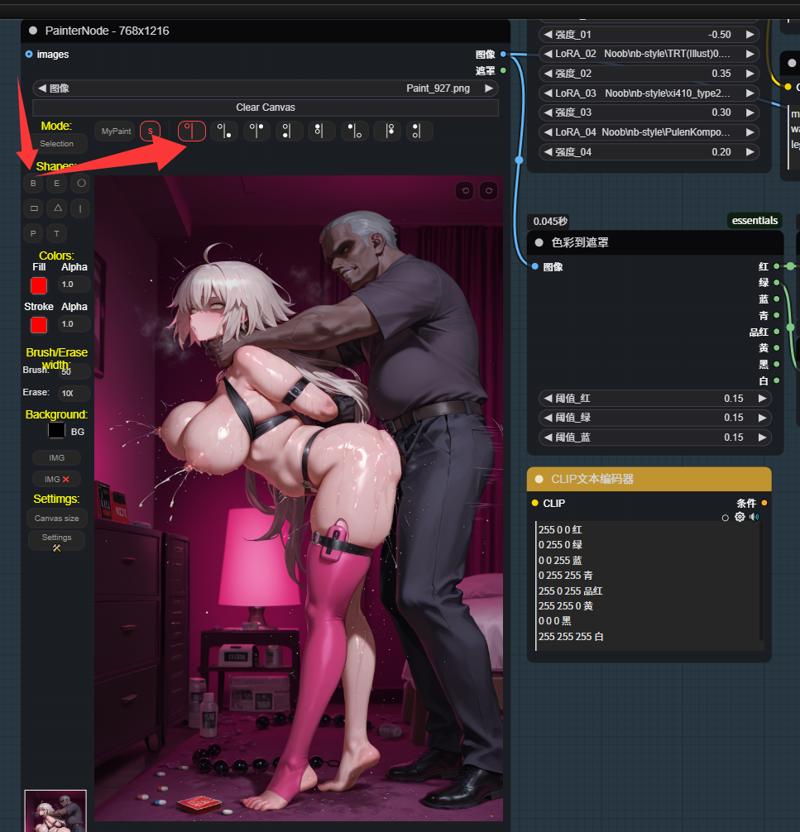
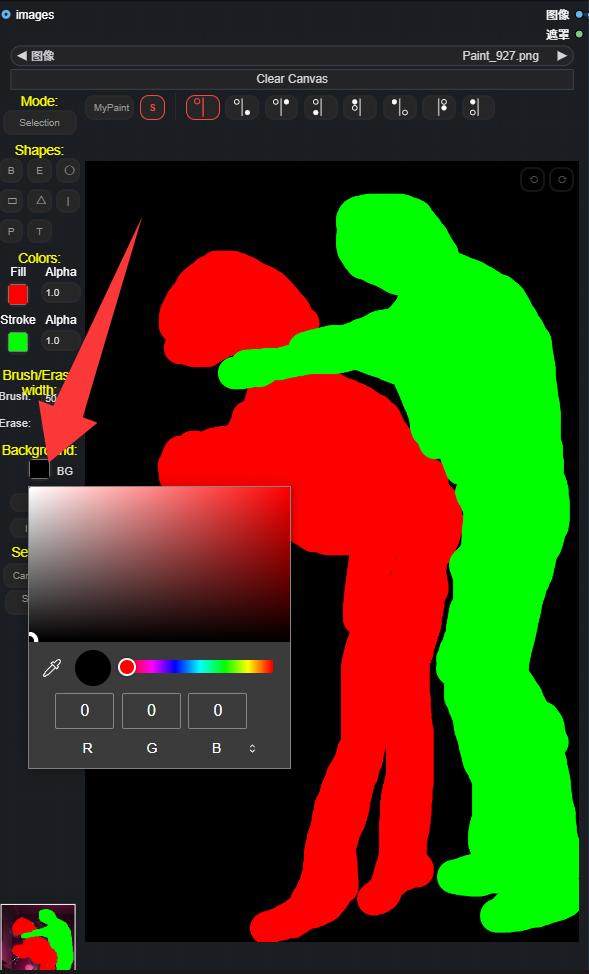
画像を右クリックしてマスクエディターを開き、修正したい部分を塗りつぶします。この例では、3人のキャラクターを識別してマスキングしています。もちろん、シーン部分を塗りつぶして再生成することも可能です。
画像を右クリックしてマスクエディターを開き、修正したい部分を塗りつぶします。この例では、3人のキャラクターを識別してマスキングしています。もちろん、シーン部分を塗りつぶして再生成することも可能です。
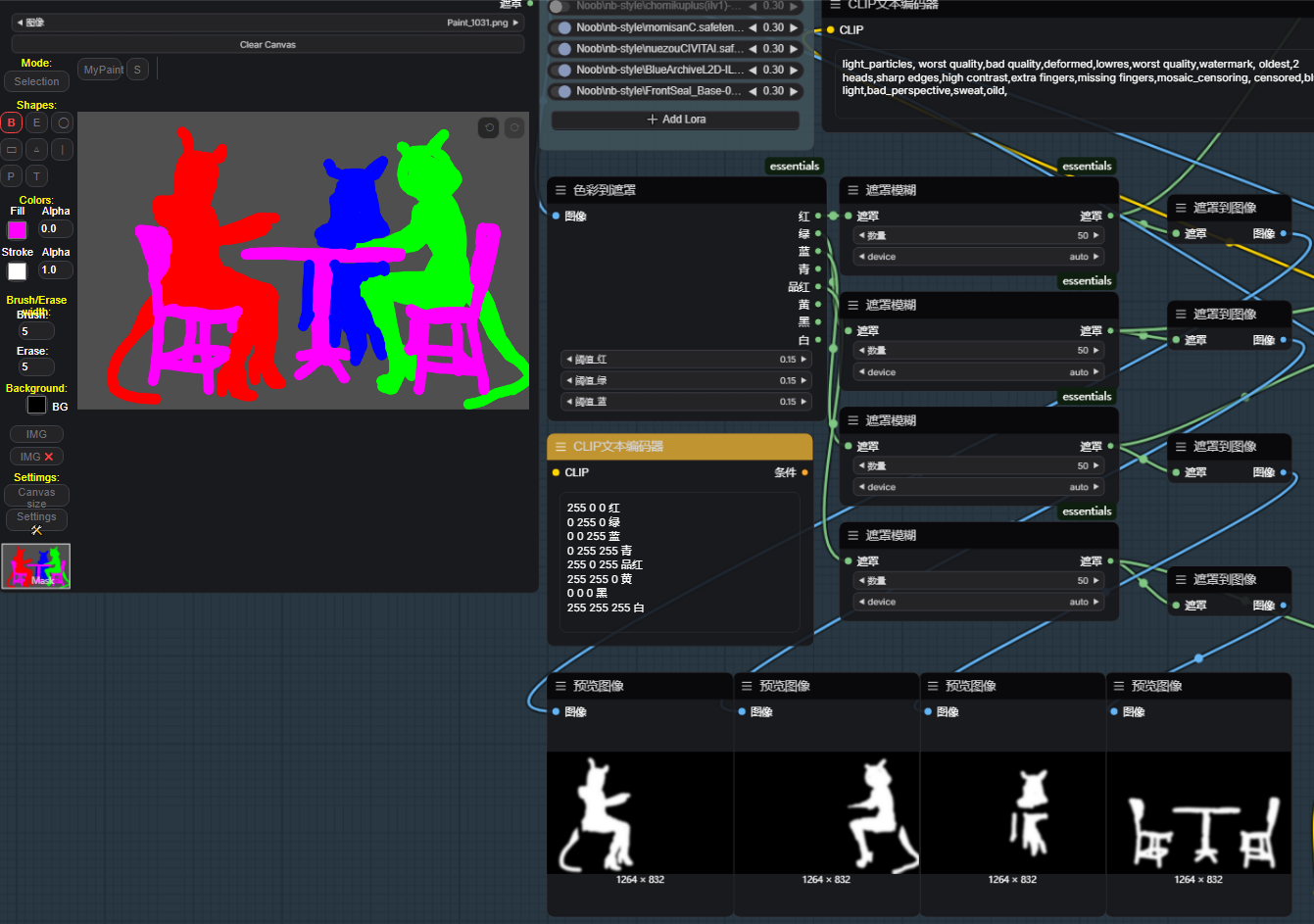
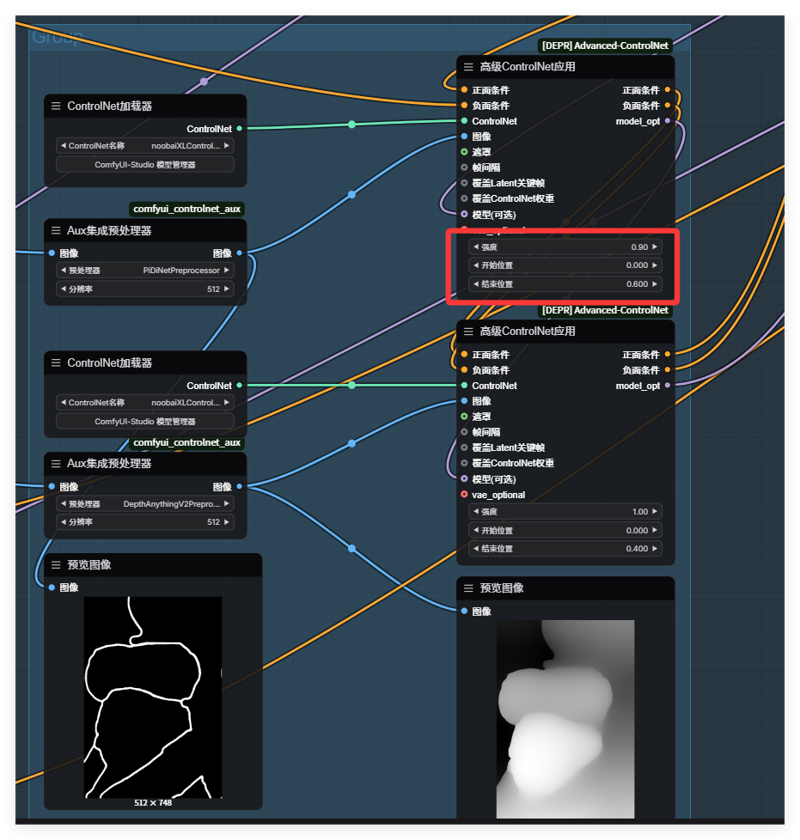
ちなみに、画像生成時にはControlNetをすべて有効にする必要はありません。目的の結果を得られる範囲で適宜使用してください。有効にしすぎると生成速度が落ちます。
ちなみに、画像生成時にはControlNetをすべて有効にする必要はありません。目的の結果を得られる範囲で適宜使用してください。有効にしすぎると生成速度が落ちます。
最後に、複数キャラクターの背景画像の選択について。この画像では、前述のメイン被写体とシーンを用いて、3つのキャラクターLoRAを適用せずに最初の背景画像を生成し、その画像の上にキャラクターのマスクを重ねました。もしアイデアが思いつかない場合は、AIに任せて生成させても構いません。
最後に、複数キャラクターの背景画像の選択について。この画像では、前述のメイン被写体とシーンを用いて、3つのキャラクターLoRAを適用せずに最初の背景画像を生成し、その画像の上にキャラクターのマスクを重ねました。もしアイデアが思いつかない場合は、AIに任せて生成させても構いません。

経験の更新:
経験の更新:
線画の強度値は高すぎないようにしてください。高すぎるとこのような結果になります。
線画の強度値は高すぎないようにしてください。高すぎるとこのような結果になります。


また、複数キャラクターの領域にいるのに1人しか生成されない場合は、その領域のタグに「multiple girls」のように複数のキャラクターをカンマ(,)で区切って記述してみてください。プロンプトは非常に敏感なので、適切な表現を工夫しないと良い結果が出ません。
また、複数キャラクターの領域にいるのに1人しか生成されない場合は、その領域のタグに「multiple girls」のように複数のキャラクターをカンマ(,)で区切って記述してみてください。プロンプトは非常に敏感なので、適切な表現を工夫しないと良い結果が出ません。
1.0:
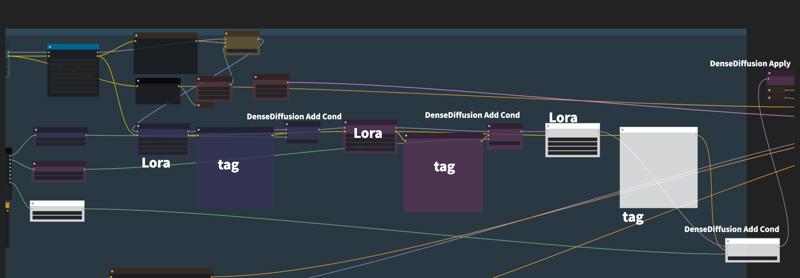
追加方法は以下の通りです:
追加方法は以下の通りです:
参考 / Related article: https://www.bilibili.com/video/BV1TK21Y8EuL/?spm_id_from=333.1007.top_right_bar_window_history.content.click