rotatesword

詳細
ファイルをダウンロード
このバージョンについて
モデル説明
序文
ローランクアダプタは、その外見とは異なります。スターブルディフュージョンモデルのためのパラメータ効率的な微調整アダプタを作成するとき、私たちは画像合成プログラムに複雑な最適化問題を解かせ、まったく新しいプログラムを生成させています。
最適化問題の選択には、まだ有用で具体的、かつ厳密なルールが存在せず、どのような学習設定や学習データを使えば、望む通りの画像生成アダプタ(Stable Diffusion LoRA)を生成できるかを決定するのは容易ではありません。
この問題への対処を少しでも簡単にできるよう、この文を書きました。
ROTATE-SWORD
学習データの準備:

とにかく何かを描いてください。何でも構いません。使用するテクスチャの種類が、出力アダプタモデルの挙動に影響を与えるため、クレヨンのようなテクスチャではなく、絵の具のようなテクスチャを使うと、あなたの好みや創造的価値をよりよく反映できます。
唯一重要な制約は、描いたものをすべて塗りつぶし、深さ、反射性、テクスチャ上のパターンの違いを異なる色で表現することです。
画像をミラー反転し、4つの主要な方向(上下左右)と4つの対角方向にそれぞれ回転させることで、学習データを16倍に増やしてください。
学習データには、機械ビジョン用のラベリングツールを使用してください。機械ビジョンの専門家でない限り、画像キャプションの手動ラベリングはお勧めしません。私はテキスト分類器の微調整すらままなりません!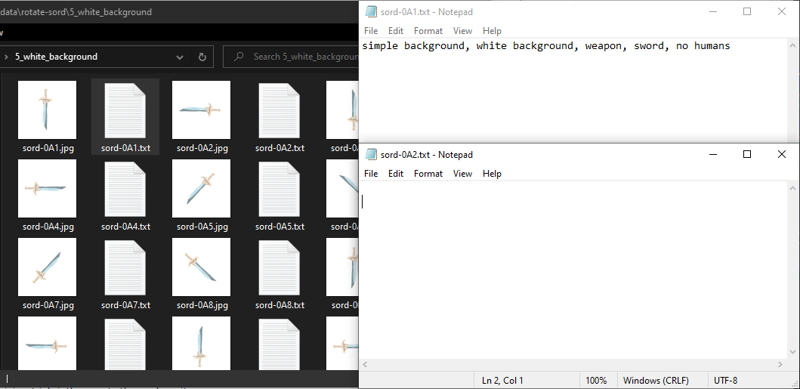
オブジェクトと背景を示すタグが、すべての個別画像に正しく適用されているか、学習データを確認してください。私の学習データセットでは、本来共有するはずのタグのほとんどが、ほとんどの画像に欠落していることに気づきました!
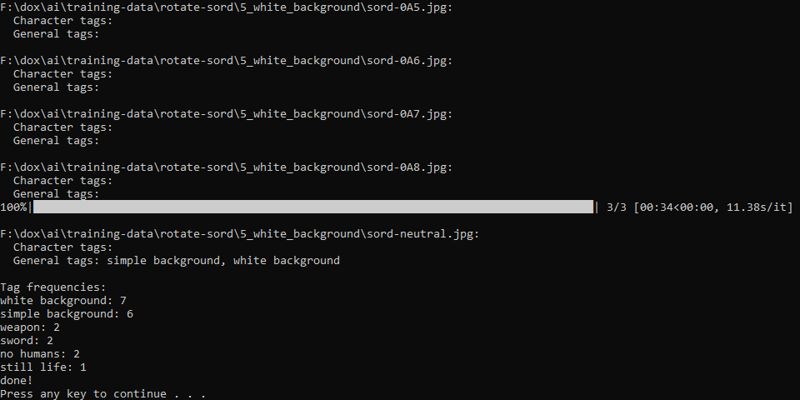
有効なタグをいくつかコピー&ペーストするだけで簡単に修正できます。もしコンピュータに強い方なら、シェルスクリプトを使ってこの作業をさらに効率化できるでしょう。
学習:
私はnetwork_dimを64、network alphaを64、学習率を5e-05(すべてのフィールドで)、内部解像度を768x768(トレーニングバッチサイズを下げれば、8GB GPUでも動作します!)、++min_snr_gammaを5.0++、multires noise discountを0.13と設定しました。最初の学習では、5回の'dataset repeats'と12エポックを使用しました。あなたの学習では、(repeats * epochs) の合計が50~70程度になることをお勧めします。アダプタモデルの変化を学習中に明確に観察しやすくするために、repeatsを0にして、60エポックを目指すことを推奨します。
++で示した学習設定は、おそらくプラセボ効果であり、少なくとも無駄です。良好な学習結果を得るためには、これらを模倣する必要はありません。
各エポックごとにチェックポイントを保存し、画像をサンプリングしてください!
出力モデル:
この学習プロセスは、学習パラメータを最適化せずに、わずか18分で終了し、収束した出力アダプタモデルを大幅にオーバーシュートした、ということを言及しましたか?
見つけられるすべてのモデルで、単一オブジェクト・単一テクスチャのLoRAを学習してみてください。SD1.5、SD2.0、お気に入りのフォトリアリスティックやアニメのDreamBoothすべてを試してください。
単純で明確な最適化目標を、制約された具体的なデータセットを通して与える限り、すべてのStable Diffusionモデルはあなたのデータセットから何らかの興味深いことを学習します。
以下は、この学習データセットと方法論を用いて、Stable Diffusion 1.5、NAI-leak、counterfeit-3、および私の個人的なブロック重みマージモデル(counterfeitと同様だが、紫色の斑点が少ない)で生成したrotate-sword LoRAです。
この方法で学習したLoRAには、Automatic1111のWebUI用のlora-ctlアドオンを使用することをお勧めします。アダプタモデルが、あなたの特定の美的目標として望まない無限の白い広がりや抽象的な背景を生成することを避けたいでしょう。lora-ctlのアルファカーブ<lora:loraname:1:[email protected],[email protected],[email protected]>を用いると、このような挙動を非常にうまく調整できます。