AmateurTrigger_XL





















詳細
ファイルをダウンロード
モデル説明
ここで私が取り組んできた最大のプロジェクトですが、すでに20日間続けており、いくつかのテストを実施してきました。
要するに、LoRAという名前が示すように、非常にアマチュアで、素朴で手作りのような風貌を目指しています。
私が望むレンダリングをマスターするための技法を見つけるのに、長い時間がかかりました。
何より、画像を一つずつダウンロードする時間を無駄にしたくなかったので、アマチュア/手作りのコンテンツが確実に見つかるいくつかの有名サイト用に画像スクレイパーをプログラムしました。リンクを入力するだけで、スクリプトはすべてのページから画像を一括でダウンロードできるようになりました。
大量の画像を入手できたのは素晴らしいことですが、品質も必要です。訓練の品質を低下させるような劣化した画像を大量に含めることは絶対に避けたかったので、ダウンロードフォルダを整理するための別のスクリプトを設計しました。「ファイルサイズ」「重量」「品質」で並べ替えました。画像をそれぞれのフォルダに整理した後、上位ランクの画像だけをルートフォルダに戻しました。
結局、わずか数分で15,000枚の画像をダウンロードし、その中で残したのは…5,000枚だけでした。でも、LoRAにとっては5,000枚は十分な量です。
自動並べ替えの後、さらに手動での仕分けを実施しました。
私は絶対に5,000枚の画像でLoRAを訓練したかったため、「ファインチューン」タイプの訓練を選択しました。学習率は約2e-05、ネットワーク次元は96、アルファは16。合計11,800ステップ(2回に分けて訓練。青い曲線が最初の訓練結果)
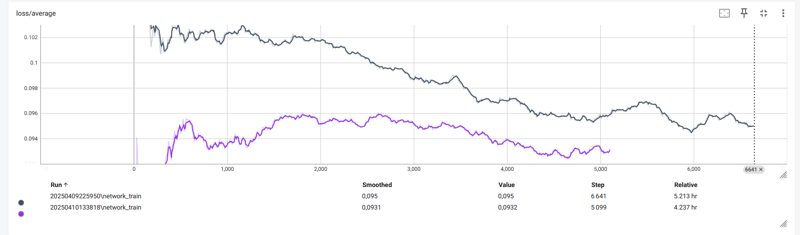
キャプションはJoyCaption Alpha 2で作成(5,000枚の画像で時間がかかりましたが、一晩で完了しました)
すべて「記述的|中程度の長さ」プリセットを使用。
BigLustiMix_rebirthで訓練しましたが、いつものようにLustify/BigASP2ベースのすべてのモデルと互換性があります。
チェックポイントに大きく影響するため、強度は約0.8程度に抑えることをお勧めします。しかし、それが私の狙いでもあったので、これは当然の結果です。当初、ファインチューンを目指していたからです。
低圧縮率、比較的シンプルな照明(しばしばスマホのフラッシュのような光源を使用)、しかし解像度を落とさない、有名なノイズ・粒状質の画像スタイルが特徴です。私はこのLoRAを標準的な解像度1024x1024ではなく、1216x1216で訓練したため、SDXLの通常の基準をやや超える解像度を可能にしています。
また、身体の形状もより自然で、ポーズも全体的に素朴で、それほど「完璧」ではない印象です。
特別なトリガーTokenは特に必要ありません。このLoRAは小さなモディファイよりも、むしろ大規模なDLCのようなものです。最も頻繁に使われているタグを知るには、LoRAをメタデータアナライザーにインポートすることをおすすめします。あるいは、私が作成したスクリプトをご利用ください。