T5xxl-Unchained Lora + Workflow






詳細
ファイルをダウンロード
このバージョンについて
モデル説明
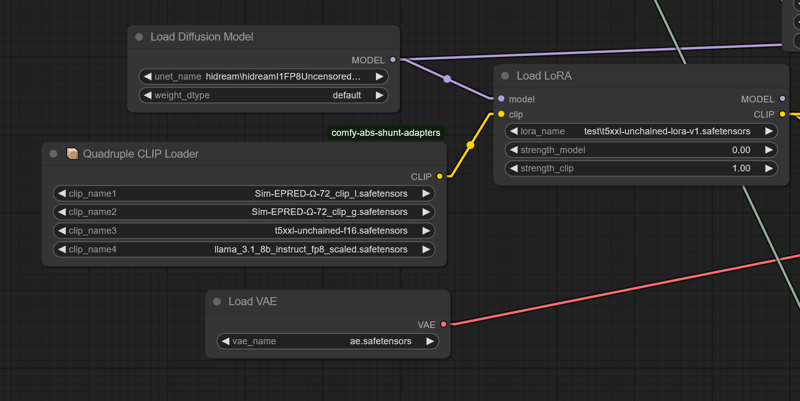
Flux フィックス更新 - 7/2/25 - 夕方:
t5xxl用のFluxローダーにバグがあり、本日の夕方のアップデート向けに修正して動作するようにしました。
SD3およびSD35に対しても同様の対応が必要になるでしょう。
ワークフロー公開 - 7/2/25 - 朝:
現在のワークフローはcomfy-clip-shuntsノードアドオンを必要とします。shuntsを使わなくても構いませんが、t5-unchainedをサポートするclipローダーが含まれています。
これらのローダーは、元のSD関数呼び出しを直接利用をリンクする関数呼び出しに置き換えることで動作しています。
shuntsを使用する場合、beatrixの代わりに標準のBERT uncasedまたはBERT casedを使用できますが、その場合は精度がやや低下します。
Unchained付きのShuntコード:
https://github.com/AbstractEyes/comfy-clip-shunts/tree/dev
完全に未学習のUnchainedモデル:
https://huggingface.co/AbstractPhil/t5xxl-unchained
ここには多数のCLIPをロードしています。オメガ24は元のViT-L-14やLAION ViT-BigGに近いため、非常に優れています。
https://huggingface.co/AbstractPhil/clips
res4lyfによって強化・改善されています。インストールを推奨します。
https://github.com/ClownsharkBatwing/RES4LYF
Kaoru8氏の基本的なt5xxl-unchained変換とリポジトリに心より感謝します。このモデルは元のT5に追加の学習を加えていないものですが、変換は成功しており、私が投入した学習データは明確に効果を発揮しています。
https://huggingface.co/Kaoru8/T5XXL-Unchained
まあ、1週間で十分に動作するSD35プロトタイプが出来たのは悪くない。
来週の今頃には、Fluxバリエーションが完全に動作し、CLIPスイートもプロトタイプ段階に達していることを期待しています。
正直、少し休む必要があると思います。この作業は私のメンタルヘルスに非常に負担をかけていたようで、回復と再生の時間を取ろうと思います。
今後はフルファインチューニングよりも、ツールの改善や小さなファインチューニングに集中します。大きなファインチューニングはコストが高く、プログラムが正しく動作しない場合、身体的・精神的に非常に消耗します。
はい、これはT5 LoRAです。T5xxlのlora_te3を「T5xxl」テキストエンコーダーと見なしています。元のSD35学習LoRAからlora_te3レイヤーを抽出し、再保存しました。シンプルなプロセスですが、どのような欠陥があるかはわかりません。ComfyUIまたはForge以外では読み込まれない可能性が高いですが、こちらにあります。
LoRA重みを適用した状態で、T5xxl-unchainedと通常のLLM推論を使って会話が可能です。要約もよく行います。
800MBのLoRAです。プロセスは思ったよりずっと簡単でした。
https://huggingface.co/AbstractPhil/SD35-SIM-V1/tree/main/REFIT-V1
from safetensors.torch import load_file, save_file
# Load the safetensors model
input_path = "I:/AIImageGen/AUTOMATIC1111/stable-diffusion-webui/models/Lora/test/sd35-sim-v1-t5-refit-v2-Try2-e3-step00003000.safetensors"
output_path = "I:/AIImageGen/AUTOMATIC1111/stable-diffusion-webui/models/Lora/test/t5xxl-unchained-lora-v1.safetensors"
model = load_file(input_path)
# Filter out TE1 and TE2 tensors
filtered = {k: v for k, v in model.items() if not (k.startswith("lora_te1") or k.startswith("lora_te2") or k.startswith("lora_unet")) }
print(f"Filtered out {len(model) - len(filtered)} tensors.")
print(f"Remaining tensors: {filtered.keys()}")
# Save result
save_file(filtered, output_path)
print(f"✅ Saved cleaned model without TE1/TE2 tensors to:\n{output_path}")
ご希望であれば自分で抽出してください。最新のT5はまだ学習中です。
T5xxlの正しいトークナイザーとコンフィグ、およびT5xxlモデル重みが必要です。
ベースのt5xxl-unchained、トークナイザー、正しい次元設定がなければ、サイズ不一致エラーが発生します。
巨大なT5xxl fp16またはfp8が必要です。fp16で学習されたため、ファインチューニングの結果はこれでより良くなります。ComfyUIまたはForgeにダウンスケールするよう指示するだけで済むでしょう。
https://huggingface.co/AbstractPhil/t5xxl-unchained/resolve/main/t5xxl-unchained-f16.safetensors
CLIPスイートが完成すると、プログラム内で自動的にスケーリングされ、ハードウェアレベルのクオンタイズ(Q2、Q4、Q8など)のホット変換およびComfyUI内での保存が可能になります。
その段階では、1つのモデルだけで、すべてがランタイムでMETA C++ライブラリを使用して変換されます。
https://huggingface.co/AbstractPhil/t5xxl-unchained/blob/main/config.json
https://huggingface.co/AbstractPhil/t5xxl-unchained/blob/main/tokenizer.json
Forgeを変更するには、これらのファイルを上記アドレスのファイルと置き換えます。ただし、sd3_conds.pyだけはコード内のテンプレートを直接修正する必要があります。
元のコンフィグをバックアップしておいても構いません。実際のところ、標準形のt5xxl-unchainedはオリジナルのt5xxlと全く同じ動作をします。
------------------------------------------------------------------------
configs
------------------------------------------------------------------------
modules/models/sd3/sd3_conds.py
backend/huggingface/stabilityai/stable-diffusion-3-medium-diffusers/text_encoder_3
backend/huggingface/black-forest-labs/FLUX.1-dev/text_encoder_2/config.json
backend/huggingface/black-forest-labs/FLUX.1-schnell/text_encoder_2/config.json
-------------------------------------------------------------------------
tokenizers
-------------------------------------------------------------------------
backend/huggingface/black-forest-labs/FLUX.1-dev/tokenizer_2/tokenizer.json
backend/huggingface/black-forest-labs/FLUX.1-schnell/tokenizer_2/tokenizer.json
backend/huggingface/stabilityai/stable-diffusion-3-medium-diffusers/tokenizer_3/tokenizer.json