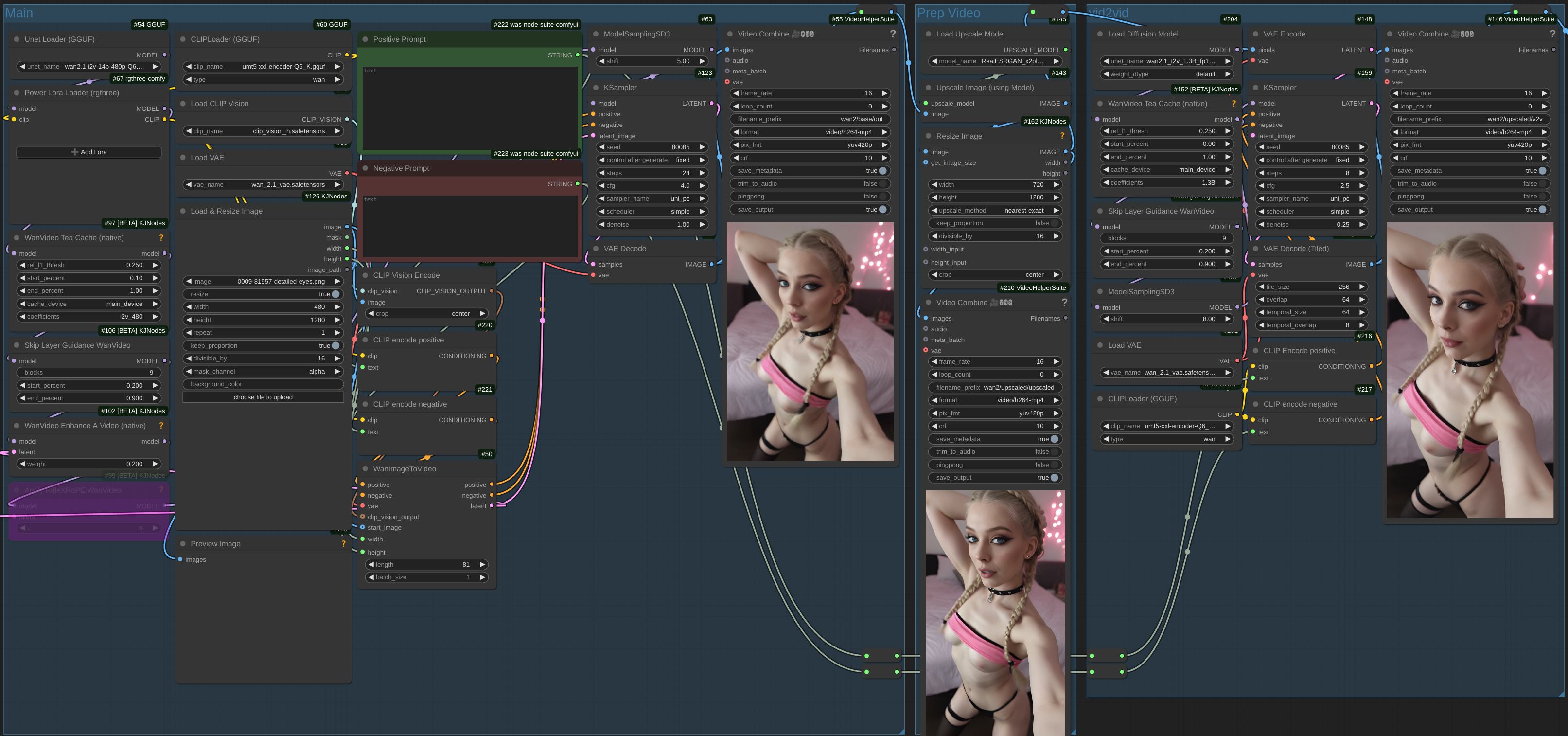
Wan i2v with upscaling, interpolating, and smoothing

Details
Download Files (1)
About this version
Model description
Now faster and easier to install
This workflow uses a small baseline generation using the 14B image to video model, followed by upscaling, and then smoothing out the result using the 5B model.
This lets you test prompts and iterate quicker on the base generation before upscaling to a final resolution.
Links for all the required models and where to put them are now included in the workflow.
FAQ
Do I need both Wan 2.1 and 2.2 VAEs?
Yes. The 2.2 VAE only works with the 5b model (confusing, I know). Make sure the main section loads the 2.1 VAE, and the upscale section loads the 2.2 VAE.
Its frozen on VAE decode
The second vae decode can take a long time. Just be patient.