Knife XL FFusion - CivitaI / LoRA + FA Text Encoder





















詳細
ファイルをダウンロード
このバージョンについて
モデル説明

🗡️ FFusionAIのナイフLoRAモデルデモ
このデモでは、3つの異なるLoRAトレーニングの詳細に深く入り込みます。各モデルは、パートナーであるNoramePhotography Studioのプロフェッショナルな環境で収集された200丁のナイフから成る独自のデータセットを基に、丁寧にトレーニングされています。画像は純白のスタジオショットから、素朴な木製の背景、きらめくコイン、ファンタジー風の室内装飾まで幅広くカバーしています。
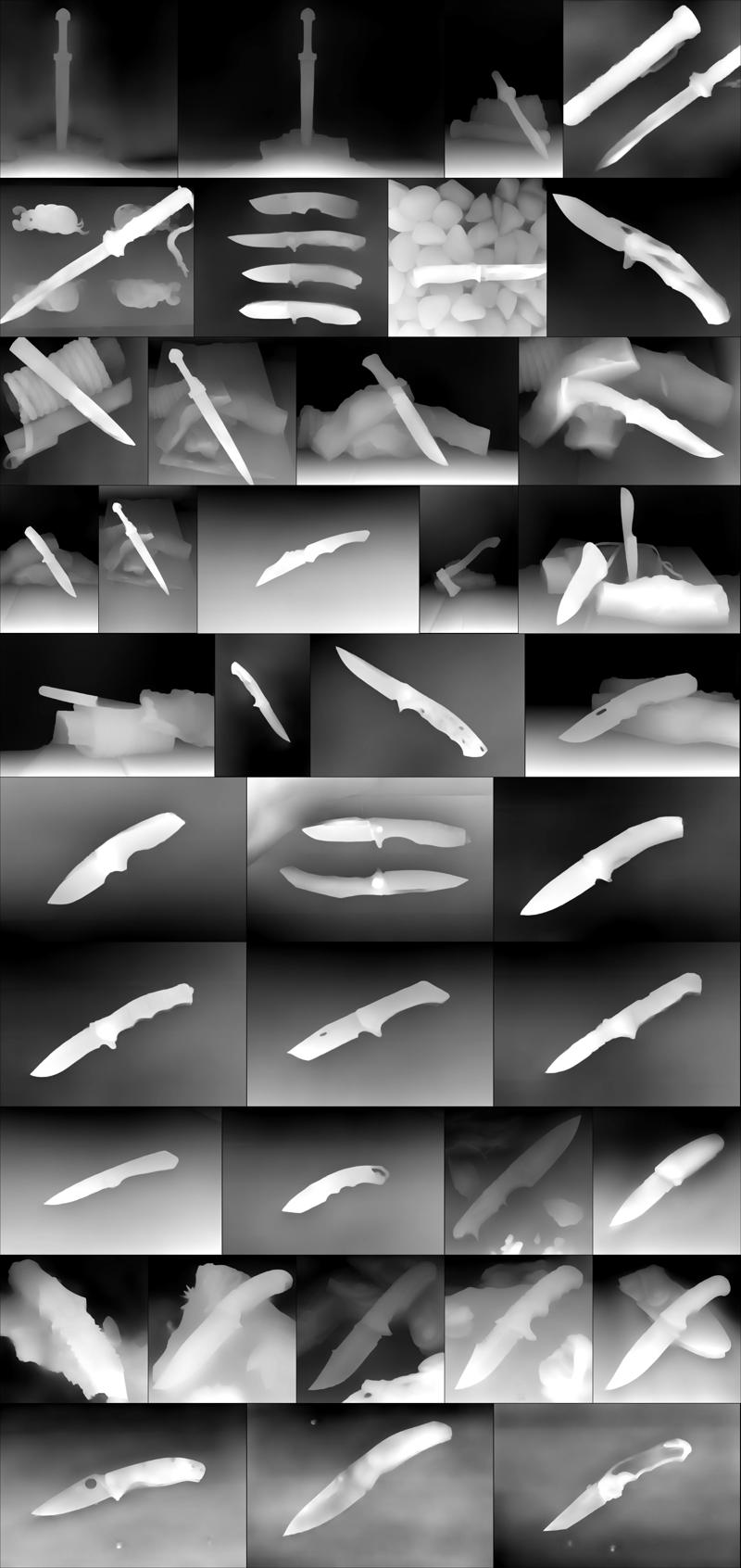
🔍 データセットの洞察:このデータセットは多様性に富んでいますが、主にデモ目的のために快速かつ非公式なタグ付け手法で選定されています。ナイフの写真セッションに興味を持ち、より詳細なトレーニングをご希望の場合は、ぜひお知らせください!
深さの変化については今後対応予定ですが、現在の焦点は異なるLoRAバリエーションの評価にあります。

🎯 モデル概要:
1. CivitAIのクイックLoRAトレーニング(Lora1)
📌 特徴:
CivitAIの新しいLoRAトレーナーを活用。
10エポックの迅速なトレーニングを20〜30分で完了。
デフォルト設定では品質が変動する可能性がありますが、時間は重要です!
📊 仕様:
日付: 2023-09-19T14:36:14
解像度: 1024x1024
アーキテクチャ: stable-diffusion-xl-v1-base/lora
Network Dim/Rank: 32.0
Alpha: 16.0
Knife_XL_FFusion.safetensors
Date: 2023-09-19T14:36:14 Title: Knife_XL_FFusion
Resolution: 1024x1024 Architecture: stable-diffusion-xl-v1-base/lora
Network Dim/Rank: 32.0 Alpha: 16.0
Module: networks.lora
Learning Rate (LR): 0.0005 UNet LR: 0.0005 TE LR: 5e-05
Optimizer: bitsandbytes.optim.adamw.AdamW8bit(weight_decay=0.1)
Scheduler: cosine_with_restarts Warmup steps: 0
Epoch: 10 Batches per epoch: 74 Gradient accumulation steps: 1
Train images: 282 Regularization images: 0
Multires noise iterations: 6.0 Multires noise discount: 0.3
Min SNR gamma: 5.0 Zero terminal SNR: True Max grad norm: 1.0 Clip skip: 1
Dataset dirs: 1
[img] 282 images
UNet weight average magnitude: 2.634092236933176
UNet weight average strength: 0.009947009810559605
Text Encoder (1) weight average magnitude: 1.696394163771355
Text Encoder (1) weight average strength: 0.008538951936953606
Text Encoder (2) weight average magnitude: 1.720911101275907
Text Encoder (2) weight average strength: 0.006699097931942388

2. テキストエンコーダーのみのLoRA FA(Lora2)
📌 特徴:
テキストエンコーダーのみでトレーニング。
このLoRAバリアントにはUNetは含まれません。
📊 仕様:
日付: 2023-09-19T20:04:24
解像度: 1024x1024
アーキテクチャ: stable-diffusion-xl-v1-base/lora
Network Dim/Rank: 32.0
Alpha: 32.0
Knife-FFusion-LoRA-FA.safetensors
Date: 2023-09-19T20:04:24 Title: Knife-FFusion-LoRA-FA
Resolution: 1024x1024 Architecture: stable-diffusion-xl-v1-base/lora
Network Dim/Rank: 32.0 Alpha: 32.0
Module: networks.lora_fa
Text Encoder (1) weight average magnitude: 3.986337637923385
Text Encoder (1) weight average strength: 0.018590648076750333
Text Encoder (2) weight average magnitude: 4.043434837883338
Text Encoder (2) weight average strength: 0.014620680042179104
No UNet found in this LoRA
3. 一般LoRAトレーニング
📌 特徴:
多様な仕様を備えた包括的なLoRAトレーニング。
485点のナイフ画像から成る広範なデータセットでトレーニング。
📊 仕様:
日付: 2023-08-26T23:08:56
解像度: 1024x1024
アーキテクチャ: stable-diffusion-xl-v1-base/lora
Network Dim/Rank: 32.0
Alpha: 16.0
FF-Minecraft-XL Resolution: 1024x1024 Architecture: stable-diffusion-xl-v1-base/lora Network Dim/Rank: 32.0 Alpha: 16.0 Module: networks.lora Learning Rate (LR): 0.0005 UNet LR: 0.0005 TE LR: 5e-05 Optimizer: bitsandbytes.optim.adamw.AdamW8bit(weight_decay=0.1) Scheduler: cosine_with_restarts Warmup steps: 0 Epoch: 10 Batches per epoch: 121 Gradient accumulation steps: 1 Train images: 458 Regularization images: 0 Multires noise iterations: 6.0 Multires noise discount: 0.3 Min SNR gamma: 5.0 Zero terminal SNR: True Max grad norm: 1.0 Clip skip: 1 Dataset dirs: 1 [img] 458 images UNet weight average magnitude: 2.9987627096874507 UNet weight average strength: 0.011098071585284945 Text Encoder (1) weight average magnitude: 1.729993708156961 Text Encoder (1) weight average strength: 0.008685239007756952 Text Encoder (2) weight average magnitude: 1.7630326984758309 Text Encoder (2) weight average strength: 0.0068346636309082635

🎨 Readme作成者:🤖 & FFusionAI 🚀
🌐 お問い合わせ先
FFusion.ai プロジェクトは、Source Code Bulgaria Ltd および Black Swan Technologies によって運営されています。
📧 ご質問やサポートについては、[email protected] までお問い合わせください。
🌌 以下のSNSでもご確認いただけます:
🌍 ソフィア・イスタンブール・ロンドン