Yoshi/ヨッシー (Don't Toy With Me, Miss Nagatoro)











詳細
ファイルをダウンロード
このバージョンについて
モデル説明
- Civitaiの利用規約により、一部の画像をアップロードできません。完全なプレビュー画像はHUGGINGFACEでご確認ください。
- モデルバージョンv1.5.1またはv2.0+の場合、他のLoRAと同様にWebUIでそのまま使用できます。これらはkohyaスクリプトで訓練されています。
- モデルバージョンv1.5またはv1.4-の場合、2つのファイルをすべて使用する必要があります。詳細は説明内の「Pivotal Tunedモデルの使用方法」をご覧ください。
- 削減されたキャラクタータグは「ツインテール」「茶色の目」「金髪」「イヤリング」「アホ毛」「ピアス」「髪飾り」です。キャラクターの主な特徴(例:髪の色)が安定しない場合、これらのタグをプロンプトに追加してください。
- ptファイルの推奨重みは0.7–1.1、LoRAの重みは0.5–0.85です。
- 画像は一部の固定プロンプトとデータセットに基づくクラスタリングプロンプトを使用して生成されています。ランダムシードを使用しており、選別は行っていません。ここでご覧いただけるものが、実際に得られる結果です。
- 衣装用の特殊な訓練は行っていません。衣装に対応するプロンプトは、提供されたプレビューポストをご覧ください。
- このモデルは205枚の画像で訓練されました。
- 訓練設定ファイルはこちらです。
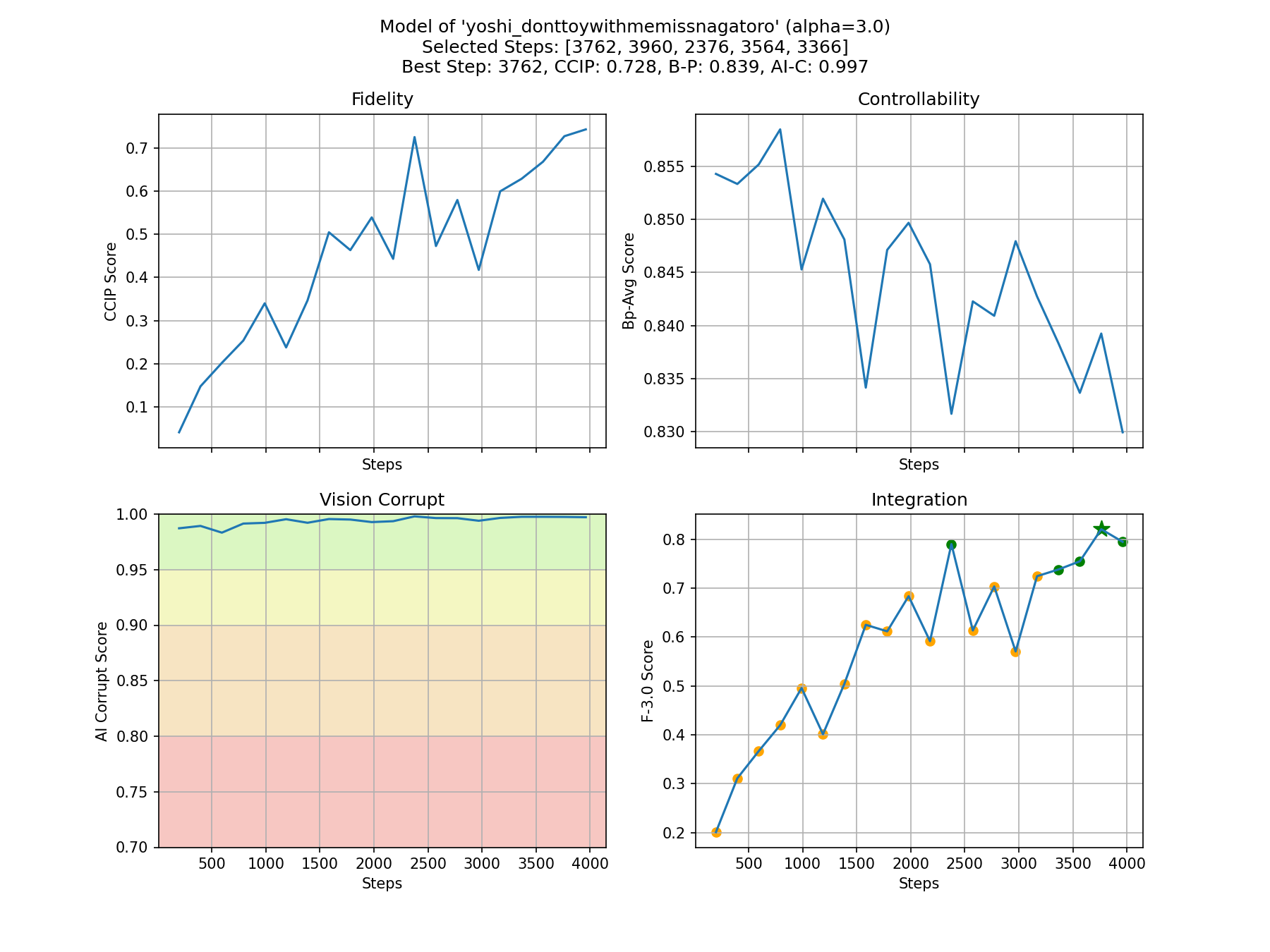
- モデルの忠実度と制御性のバランスを取るために、自動選択されたステップは3762です。すべてのステップの概要は以下のとおりです。他の推奨ステップはHuggingFaceリポジトリ - CyberHarem/yoshi_donttoywithmemissnagatoroで試してください。
このモデルの使用方法
このセクションはモデルバージョンv1.5.1またはv2.0+向けです。
他のLoRAと同様に簡単に使用できます。このモデルはkohyaスクリプトで訓練されました。
他のLoRAのように簡単に使用できます。このモデルはkohyaスクリプトで訓練されました。
다른 LoRA처럼 간단히 사용할 수 있습니다. 우리는 이 모델을 kohya 스크립트로 훈련했습니다.
您可以像其他LoRAs一样简单地使用它。我们使用kohya脚本对该模型进行了训练。
(ChatGPTによる翻訳)
キャラクターウァイフを探している方、または当社の技術に興味がある方は、私たちのDiscordサーバーへどうぞ。
このモデルの訓練方法
- このモデルは**kohya-ss/sd-scripts**を用いて訓練され、画像はa1111のWebUIとAPI SDKで生成されています。
- 自動訓練フレームワークはDeepGHSチームが管理しています。
- 訓練に使用したデータセットは、CyberHarem/yoshi_donttoywithmemissnagatoroの
stage3-p480-1200で、205枚の画像を含みます。 - モデルの忠実度と制御性のバランスを取るために、自動選択されたステップは3762です。
- 訓練設定ファイルはこちらです。
より詳しい訓練情報や推奨ステップについては、HuggingFaceリポジトリ - CyberHarem/yoshi_donttoywithmemissnagatoroをご覧ください。
Pivotal Tunedモデルの使用方法
このセクションはモデルバージョンv1.5またはv1.4-向けです。
このモデルには2つのファイルがあります。WebUI v1.6 以下のバージョンを使用している場合は、これらを一緒に使用する必要があります!!! この場合、yoshi_donttoywithmemissnagatoro.pt と yoshi_donttoywithmemissnagatoro.safetensors の両方をダウンロードし、yoshi_donttoywithmemissnagatoro.pt を embeddings フォルダに配置し、同時に yoshi_donttoywithmemissnagatoro.safetensors をLoRAとして使用してください。WebUI v1.7+をご使用の場合は、通常のLoRAのようにsafetensorsファイルのみを使用してください。これは、埋め込みバンドルされたLoRA/Lycorisモデルが現在、a1111のWebUIで公式にサポートされているためです。詳細はこちらをご覧ください。
此模型包含两个文件。如果您使用的是 WebUI v1.6 或更低版本,您需要同时使用这两个文件! 在这种情况下,您需要下载 yoshi_donttoywithmemissnagatoro.pt 和 yoshi_donttoywithmemissnagatoro.safetensors 两个文件, 然后将 yoshi_donttoywithmemissnagatoro.pt 放入 embeddings 文件夹中,并同时使用 yoshi_donttoywithmemissnagatoro.safetensors 作为 LoRA。 如果您正在使用 webui v1.7 或更高版本,只需像常规 LoRAs 一样使用 safetensors 文件。 这是因为嵌入式 LoRA/Lycoris 模型现在已经得到 a1111's webui 的官方支持, 更多详情请参见这里。
トリガー語はyoshi_donttoywithmemissnagatoro、削減タグはtwintails, brown_eyes, blonde_hair, earrings, ahoge, stud_earrings, hair_ornamentです。ある特徴(例:髪の色)が時折安定しない場合、これらをプロンプトに追加してください。
一部のプレビュー画像がキャラクターと異なるように見える理由
プレビュー画像で使用されたすべてのプロンプトテキスト(画像をクリックすると確認可)は、訓練データセットから抽出した特徴情報を基にクラスタリングアルゴリズムにより自動生成されています。画像生成に用いられたシードもランダムに生成されており、いずれの画像も選別または修正は行っていません。そのため、上記のような現象が発生する可能性があります。
実際の運用では、当社の内部テストによると、このような現象を示すモデルの多くは、プレビュー画像よりも実際の使用時に良い結果を出します。必要なのは、使用するタグを調整することだけです。
このモデルが過学習または未学習のように感じられる場合、どうすればよいですか?
ここに表示されているステップは自動選択されたものです。他の推奨ステップもご試用ください。こちらをクリックしてお好みのステップを選んでください。
当モデルはHuggingFaceリポジトリ - CyberHarem/yoshi_donttoywithmemissnagatoroに公開されており、すべてのステップのモデルが保存されています。また、訓練データセットはHuggingFaceデータセット - CyberHarem/yoshi_donttoywithmemissnagatoroでも公開しており、参考になるはずです。
なぜより良い画像だけを選んで使わないのですか?
このモデルのデータ収集、訓練、プレビュー画像生成、公開に至るまでのすべてのプロセスは、人間の介入なしに100%自動化されています。これは当チームが行った興味深い実験であり、その目的のためにデータフィルタリング、自動訓練、自動公開を含む一連のソフトウェアインフラを開発しました。そのため、可能であれば、より多くのフィードバックや提案をいただけると非常に助かります。
期待するキャラクターの衣装が正確に生成されない理由
現在の訓練データは複数の画像サイトから収集されており、完全な自動パイプラインでは、キャラクターがどの公式画像を保有しているかを正確に予測することが困難です。したがって、衣装生成は訓練データセットのラベルに基づくクラスタリングを用いて、可能な限り最適な再現を試みています。今後もこの問題の改善と最適化を継続しますが、完全に解決できるとは限りません。衣装の再現精度は、手動で訓練されたモデルのレベルに達することは難しいでしょう。
実際、このモデルの最大の強みは、キャラクター自体の内在的な特徴を再現する能力と、より広いデータセットによる比較的高い汎化能力にあります。したがって、このモデルは衣装の変更、キャラクターのポージング、そしてもちろんキャラクターのNSFW画像生成に最適です!😉。
以下のグループの方々には、このモデルの使用をお勧めしません。ご了承ください:
- キャラクターのデザインに、わずかな違いであっても許容できない方。
- キャラクターの衣装再現に高い精度が求められる用途をお持ちの方。
- Stable DiffusionアルゴリズムによるAI生成画像の潜在的なランダム性を受け入れられない方。
- LoRAによるキャラクターモデルの完全自動訓練プロセスに不快感を覚える方、またはキャラクターモデルの訓練は手動で行うべきであり、キャラクターに不敬にならないと考える方。
- 生成された画像の内容が自身の価値観に反すると感じられる方。