Lab @11 : nude pantyhose utility lora (+ a bit nsfw style)



詳細
ファイルをダウンロード
モデル説明
イントロ。
lab 11 は LoRA のシリーズであり、lab 10 のトレーニング用データセットを修正・強化するための「汎用」LoRA として作成されました。しかし、単体でも十分に使えることがわかったため、ご自由にお使いください。
補足:ヌード/透け感のあるレギンスは、予想したほど簡単ではありません…
やや色が違うだけ、あるいは細部の損失があると、とても不自然に見えてしまいます😅
そして興味深いことに、多くのベースモデルは、特定の一般的なスタイル(例:黒いレギンス)でレギンスを生成しやすく、細部や色の修正を教えるのが少し困難です。まだ鍵となる要素は明確に言えませんが、このようなアイデアは得られました。
それほど簡単ではありませんが、LoRA をゼロから段階的に構築し、さらに改良する方法を学ぶための良いトレーニングテーマです。ぜひお試しください。
自分でトレーニングしてみてください〜楽しく、思ったより簡単です。
お勧めの方法の一つ:
Civitai にある既存の LoRA を使って、プロンプトを調整し、データセットを一式取得してください(その際、HighRes と ADetailer で顔を補正することを忘れないでください)。その後、実験をしてみてください(11-x と 10-x のシリーズを自由に活用して、バッチデータを生成・試行してください)。
また、随時、いくつかの LoRA のデータセットをアップロードする予定ですので、気軽にダウンロードして編集・トレーニングしてみてください。
変更履歴
250519
LoRA 11-25、11-27、11-28 をアップロード(janku v3 ベース)
いくつかの考察・発見を更新(以下を参照)
250430
LoRA 11-02(janku v3 ベース)および 11-03(illustrious XL 0.1 ベース)をアップロード
更新 — LoRA データセットの品質を向上させるためのいくつかの技術:
汎用 LoRA の img2img 再描画手法を組み合わせ、画像の混沌を減らし品質を向上
衣服のラインを削除し、しわをより自然に
過度にハイライトされた領域の処理
足の形状の処理
以下を参照
250429
- LoRA 11-01 をアップロード(illustrious XL 0.1 ベース、Civitai でトレーニング)
使用方法
lab 11-28
トリガートークン:lrnude pantyhose または sheer lrnude pantyhose
ネガティブプロンプトとして以下を推奨:
oily pantyhose, pantyhose band, (black pantyhose), white pantyhose,
lab 11-27
トリガートークンは lab 11-28 と同じです。
悪質なので、使用しないでください。
lab 11-25
トリガートークン:lrnude, sheer beige pantyhose
ネガティブプロンプトとして以下を推奨:
oily pantyhose, pantyhose band, (black pantyhose), white pantyhose,
lab 11-02, lab 11-03(優れており、単体でも使用可能)
モデル --
lab 11-02 => janku v3 を推奨
lab 11-03 => illustrious モデルすべてで利用可能
重み:0.5〜1、ステップ:20以上(バグが多発しない範囲)
HighRes Fix および ADetailer は必須ではありません
ポジティブプロンプトとトリガートークンの例:
lrfixme,
- これは lab 10 の画像を修正するための汎用 LoRA として使用するため、このようなトークンを採用しました
sheer pantyhose,
sheer golden pantyhose,
sheer xxx pantyhose,
sheer bodystocking,
high detailed skin,
- (未検証)細部の品質を少し向上させる可能性あり?
ネガティブプロンプトの例:
pantyhose band,
- 個人の好みですが、参考までに
shiny, oily,
- 油っぽすぎる場合に使用
データセットも添付しています。ダウンロードして以下を確認してください:
- トレーニングデータセットの品質が LoRA に与える影響(例:11-01 と 11-02 の比較)
lab 11-01(悪く、推奨しません)
更新 #250519
考察(図解)— 汎用 LoRA を用いてトレーニング用データセットを生成する
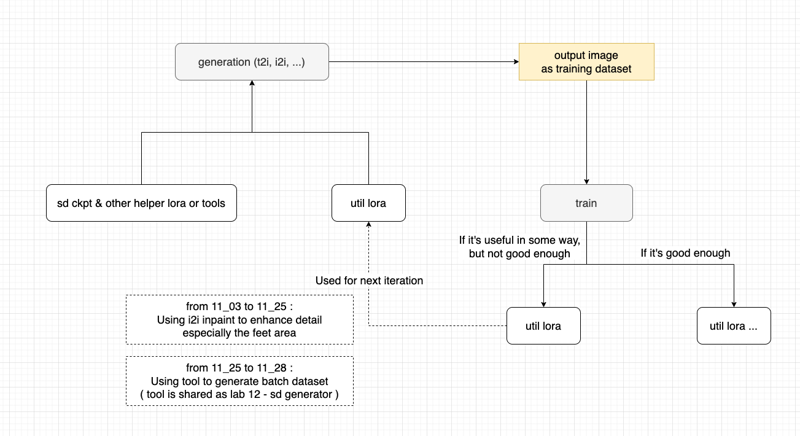
テキストを確認してください:
キャプションについて
11-27 は
xxx_word形式(アンダースコア_をセパレータとして使用)11-28 は
xxx word形式(スペースをセパレータとして使用)
発見:
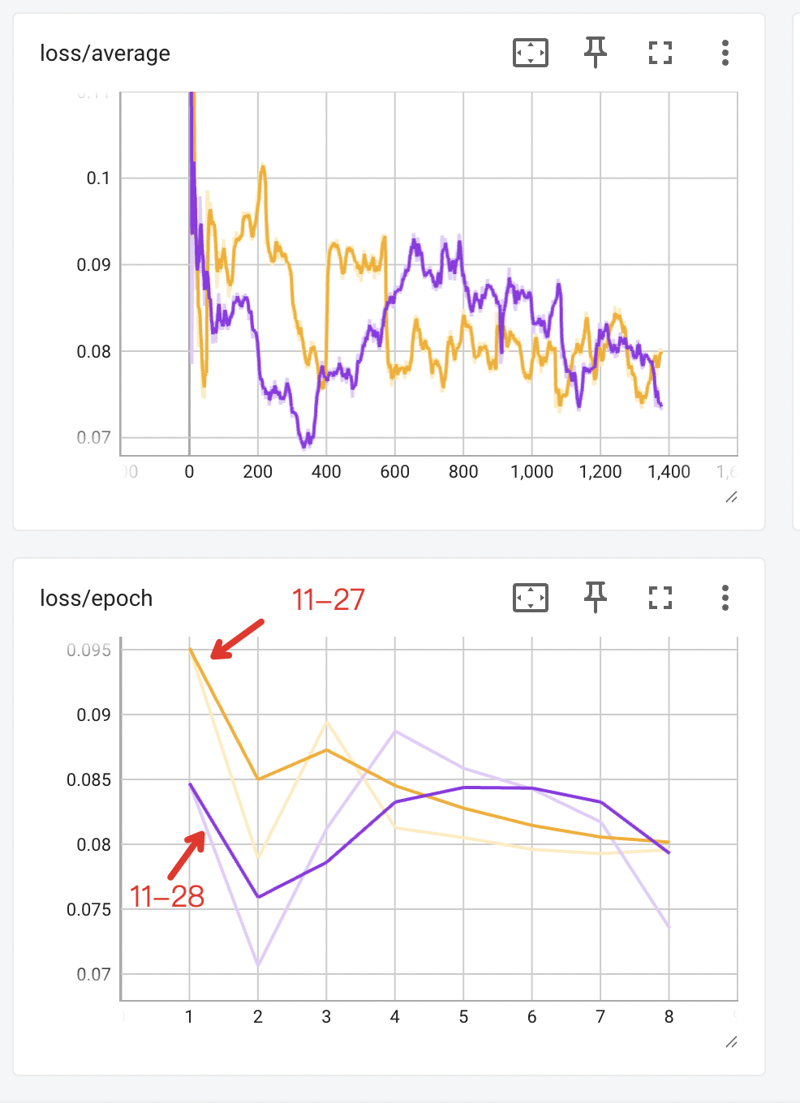
- 同じデータセット画像を用いて、11-28 の方が 11-27 より優れている
トレーニング損失曲線は以下の通り:
更新 #250430
共有:汎用 LoRA と SD を用いて、自分自身のデータセット画像を改善する方法
モデル互換性と適用範囲
まず、一つの発見を共有します:illustrious XL 0.1 をベースにトレーニングした LoRA は、illustrious XL 系列のさまざまな派生モデルにおいて非常に良好な性能を発揮します。しかし、illustrious XL のサブブランチモデルでトレーニングした場合、適用範囲はやや制限されます。たとえば、janku v3 ベースのバージョン 11-01 と比較してください(janku は illustrious → rouwei → janku と進化しているようです)。
完全に私が学ばせたい感覚を獲得できているわけではありませんが、全体的には自然に見えます。
質問:なぜ汎用 LoRA を使うのか?
まず、なぜ汎用 LoRA をトレーニングしようと考えたのでしょうか?
なぜなら、データセットは最近準備したもので(画像品質にあまり注意を払っていなかったとき)、品質向上が必要だったからです。芸術的基礎がほぼなく、単純な描画ソフトで基本的な修正しかできない人にとって、どうすればよいでしょうか?
私は img2img を用いて再描画し、品質を向上させる方法を検討しました(このアプローチが有効であれば、手動での画像品質調整よりも優れているはずです)。
しかし、ベースモデルや他のモデルを直接使用したところ、強度を高く設定すると、データセットに含まれる望ましい特性が薄れ、逆に強度を低く設定すると、十分な画像最適化効果が得られませんでした。
実験の結果、特定の処理技術を用いることで、ベースモデルや以前問題のあった LoRA のみでも、画像品質を効果的に向上できることを発見しました。
しかし、数枚の画像を処理した後、この方法はコストが高いと感じました。img2img の強度を高く設定できないため、目立つ効果を得るために追加の調整が必要だったからです。
そこで、私は次の考えに至りました:小さなバッチの画像の品質を向上させ、それらを使って高品質な LoRA をトレーニングすれば、その LoRA は txt2img では平凡でも、img2img で低重み・低ノイズ強度で安定して機能し、画像修正が容易になるはずです。
これが全体的なアプローチです。そこで私はこのような汎用 LoRA をトレーニングしました。
汎用 LoRA で修復後の効果例(0.x 強度):
まず問題点を確認しましょう。以下がオリジナル画像で、問題点は以下の通りです:
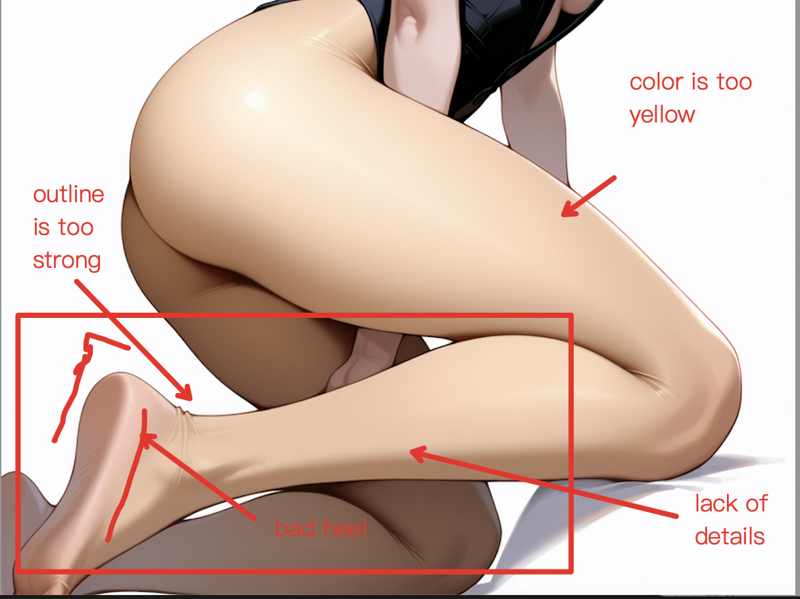
足の部分をマスクして、汎用 LoRA を 0.2〜0.4 の強度で3回迅速に処理した結果:

もちろん、特定の加湿器と一般的なタイプ、あるいは特定の美人と一般的なタイプのように、微細な変化に非常に敏感な特徴の比較には、この方法は適用できません。
注意:以下で述べる画像処理では、無料オンラインツール https://www.photopea.com/ を使用しました。
技術:マスクを用いて img2img の処理領域を制御する
マスクを用いて対象トレーニング領域を保護し、マスク外の領域に img2img 処理を適用します。これにより、保存したいコンテンツを守りつつ、優れたモデルが関係のない部分を処理(汎用 LoRA の有無、ADetailer のオン・オフに関わらず)します。この場合、より高い強度が使用可能です。
対象トレーニング効果自体が十分な品質を持っており、再描画の必要がない場合、上記の方法を適用した後、対象領域の境界をマスクで定義し、汎用 LoRA を低強度で適用して、より自然な細部のトランジションを実現します。
対象領域の調整が必要だが特に画像処理を必要としない場合、汎用 LoRA を用いて、選択領域の設定をせず、画像全体を低強度で再描画できます(選択領域の設定は面倒なので、無視してもOK😂)。必要に応じて、方法1と2を適用します。
例:(この投稿がNSFWにならないように、顔の比較のみ行います)

技術:画像のアスペクト比を変更する
これまでのトレーニング経験に基づき、以下の重要なポイントを紹介します:
一貫したトレーニング寸法の画像を提供するように努めましょう。
まず高解像度で画像を処理し(トレーニングサイズと同じ比率を維持)、すべての画像最適化をこの大きなサイズで行い、頻繁な拡大・縮小を避けましょう。
処理が完了したら、ロスレス手法で一括してトレーニングサイズに縮小し、表示時に拡大して色の揺らぎがないか確認してください(lab_10 のトレーニングでの発見を参照)。
例:画像を 1024 × 1156 から 832 × 1216 の比率に調整する場合:
まず対象方向に軽く調整し、その後対象比率に調整します。両方のプロセスでは極めて低い強度(私は0.01を使用)を用い、自動的に余分な領域を埋めます。
次に、描画ソフトで問題のある部分を削除し、画像を再インポートしてマスクを用いて変更影響を受けた領域を再調整します。
技術:リクアイフィーを用いた構造的形状調整
リクアイフィー(変形)ツールを用いて、足のかかとの位置などの構造的調整を行います。一部の領域が「長方形」のように見えすぎていることがあります。かかとはより丸みを帯び、自然な形状であるべきです。
ドラッグ調整後、より自然な形状が得られます。その後、img2img で微調整・完成させます。
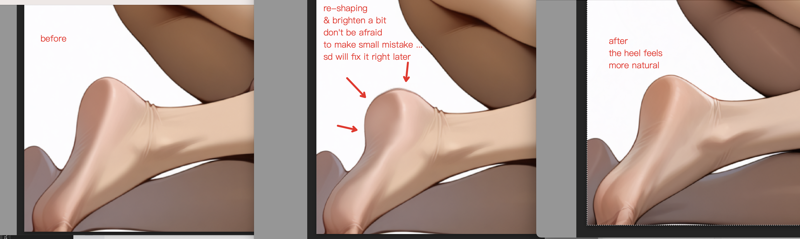
技術:細部の調整
細部の微調整、たとえばしわの削減や過剰なハイライトの回避には、以下の3つの効果的な方法があります:
色オーバーレイ:まず透明レイヤーを作成し、周囲の色を使って色付けします。ブラシの硬さと透明度を低く保つことを忘れずに。
ヒーリング:局所的に平坦な領域に有効です。ぼかし処理後、アルゴリズムが小さなしわや斑点を自動的に除去します。
ブラーとハイライト:不要な過度にシャープな部分(非常に目立つハイライト領域など)に使用できます。また、ハイライトが必要な領域に低透明度の明るさを追加することも可能です。さらに、「shiny, oily」などのネガティブプロンプトと組み合わせて、img2img が明らかに油っぽい効果を生じないように制御できます(油っぽさは、細部のない安っぽいプラスチックのような外観を生むことがあります)。
以下は衣類の縫い目ラインの削除例です:しわをより自然に(実際にはすべてを削除しているわけではありません)… そうすることで、あまりにもNSFWにならないようにします。
ぼかし処理後、低強度の img2img を用いて滑らかにすることで、より自然な効果を得ます。

より専門的なツールや高度なブラシ効果を用いれば、画像に豊かな細部を追加することも可能です。
技術:論理的エラーの修正
たとえば、不自然な三本指の足のような明らかな問題に対処する場合:
まず選択ツールで迅速に領域を選択し、位置と変形を行います(押し引きにはリクアイフィーを活用してください)。その後、img2img で中〜低強度の再描画を行い、修正部分を全体と自然に融合させます。
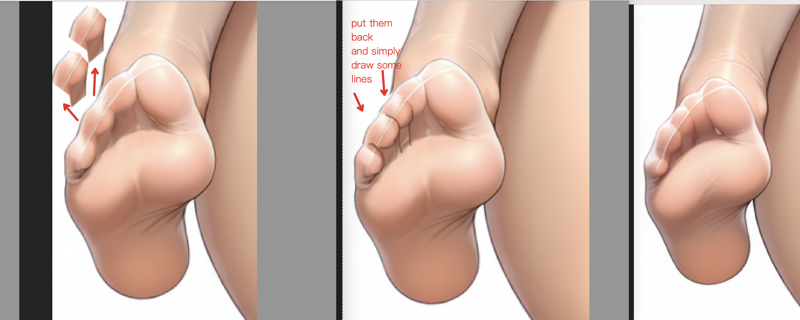
技術:選択領域の管理と Segment Anything
画像処理では、正確に処理された複数の選択領域が必要になることがあります。WebUI を使うと、選択編集機能が簡素で、細かいコントロールが難しく、一度に一つの選択領域しか扱えず、都度再描画が必要になり、非常に不便です。
画像編集ソフトで選択領域を細かく編集し、レイヤーで複数の事前選択領域を保存しておき(いつでも再利用可能)、使用する方法を検討してください。
また、さまざまな選択処理方法や反転処理も非常に有用なツールです。
さらに、Segment Anything を用いると、選択領域を非常に簡単に取得できます。詳細は以下を参照:https://github.com/continue-revolution/sd-webui-segment-anything?tab=readme-ov-file
更新 #250429
使用方法:
重み:0.5〜0.7(検証済)、ステップ:30以上(ステップが少し低すぎると、一部の生成で膣の描画が不自然になることが確認されています)
HighRes Fix(または HighRes img2img)を推奨
- ADetailer は不要かもしれません
lab 11-01:Civitai でトレーニング
hmmmm… まだ結果の LoRA をテストする機会がありませんので、追加のコメントはありません。
促:しかし、全体のワークフローはシームレスです(データセットの準備から訓練済みLoRAの公開まで)。
欠点:正則化画像セットをアップロードする方法が見つかりませんでした。
欠点:ステップごとの損失(例:TensorBoard)を確認する方法がありません。
欠点:トレーニングサイズは固定された正方形であり、832 x 1216のような指定はできません。