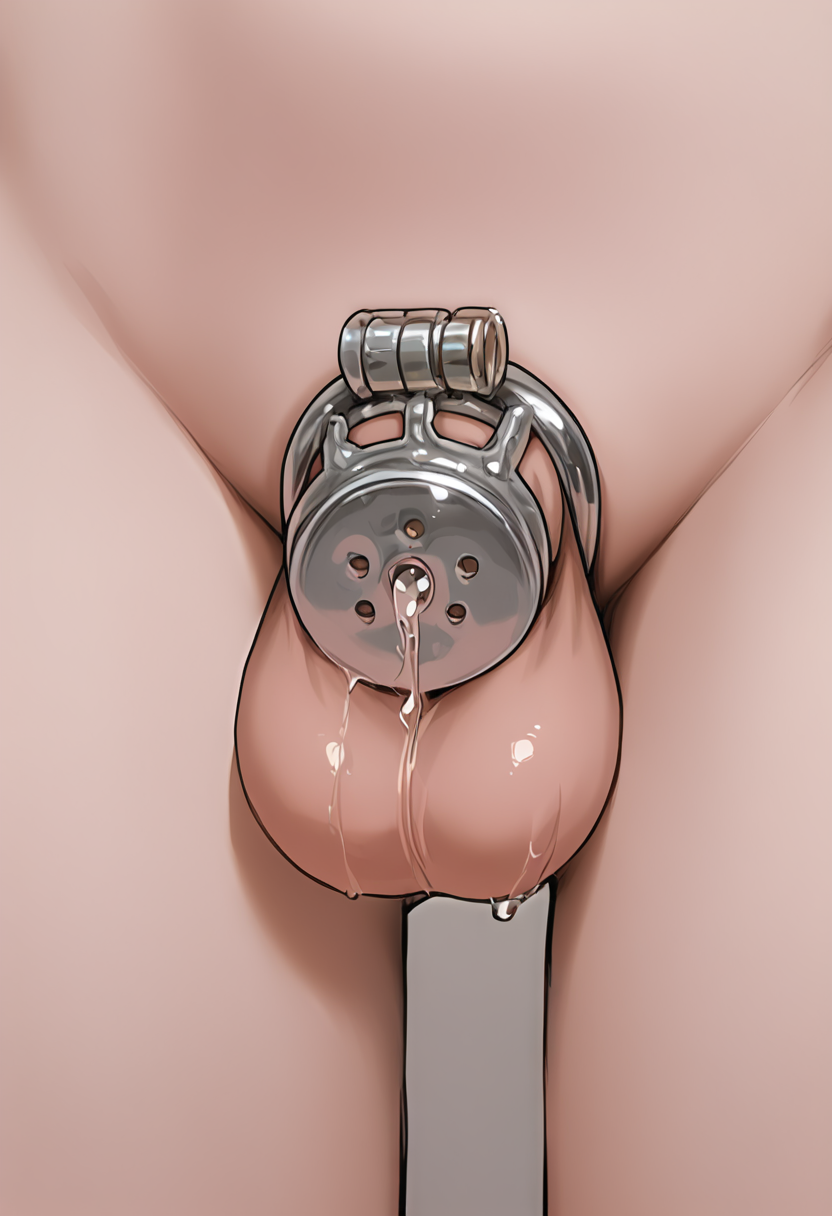
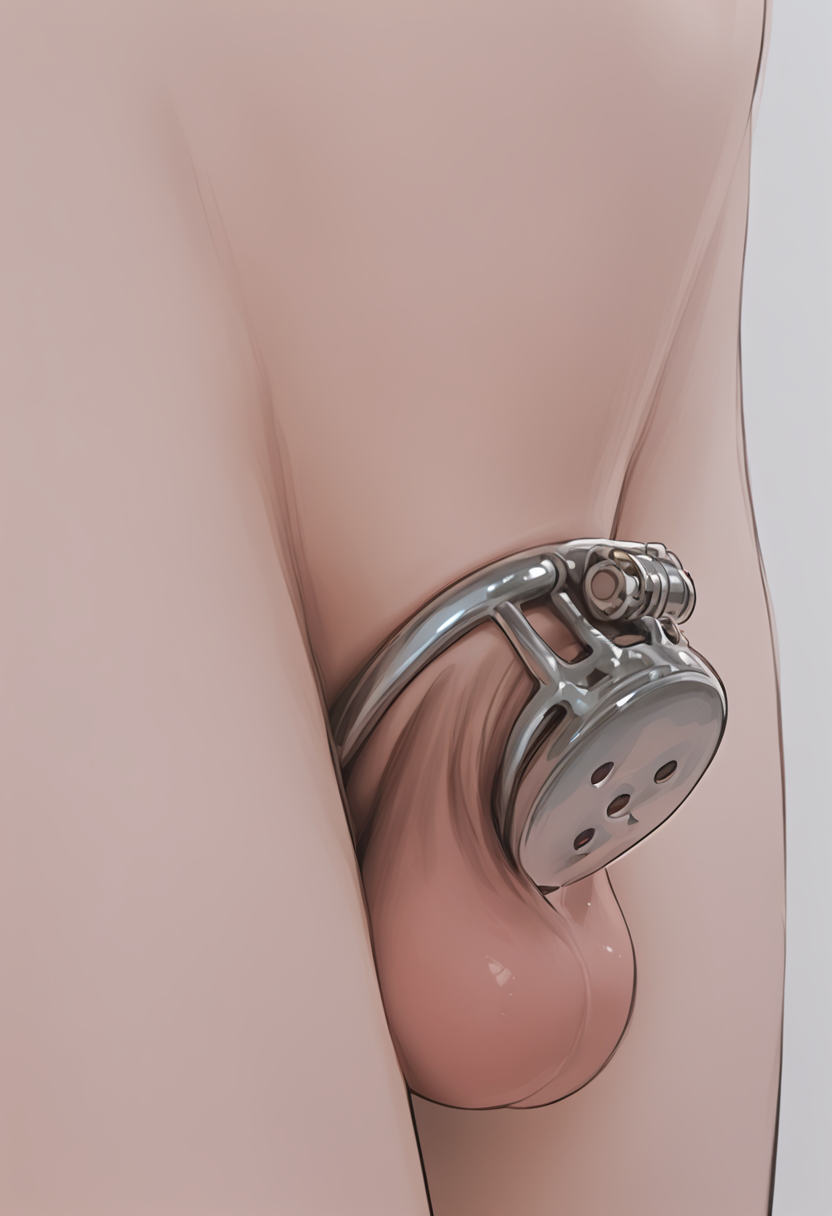
Chastity Cage (Metal Flat)



세부 정보
파일 다운로드 (1)
이 버전에 대해
모델 설명
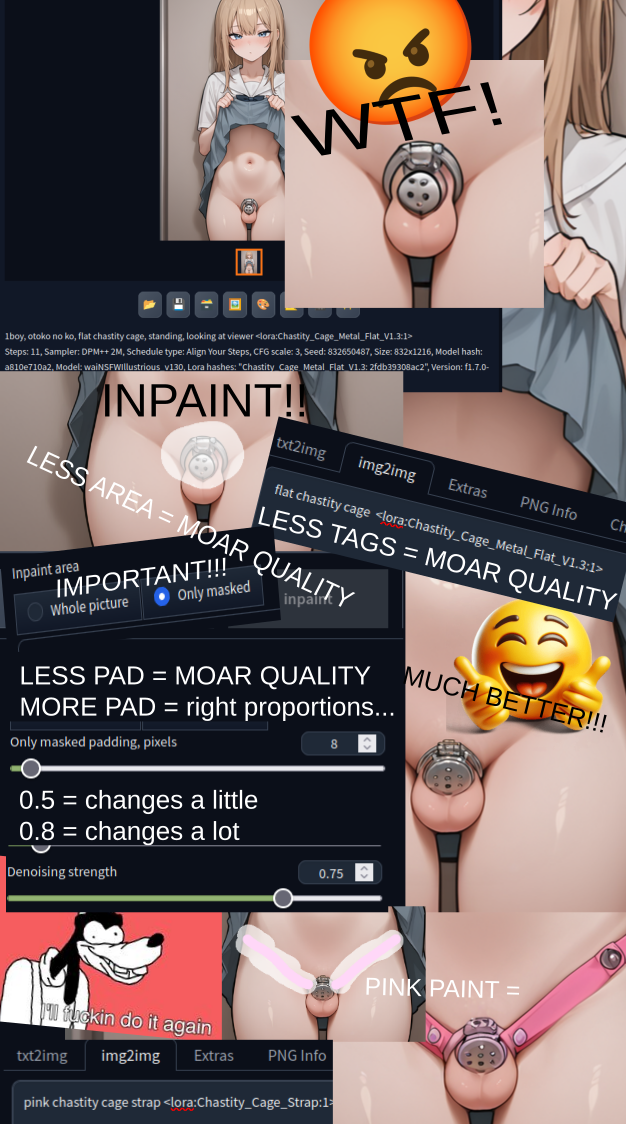
flat chastity cage lora best used with inpainting
check my specialized loras!
pov lora https://civitai.com/models/2541516/chastity-cage-pov-metal-flat
from behind lora https://civitai.com/models/2178609/chastity-cage-testicles-only
 v1.3
v1.3
more angles, precum, cum added. not as good as v1 for front pics but more versatile
trigger is flat chastity cage
v1
a test to see if i get the holes right. can only do front pics but very good at them
trigger is flat chastity cage