InfiniteTalk - with Single speaker - Simple workflow (subgraphs)

详情
下载文件 (1)
关于此版本
模型描述
Switched over to InfiniteTalk model
Please note : this version uses subgraphs, please update your UI if necessary.
No spaghetti nightmare -- like some workflows.
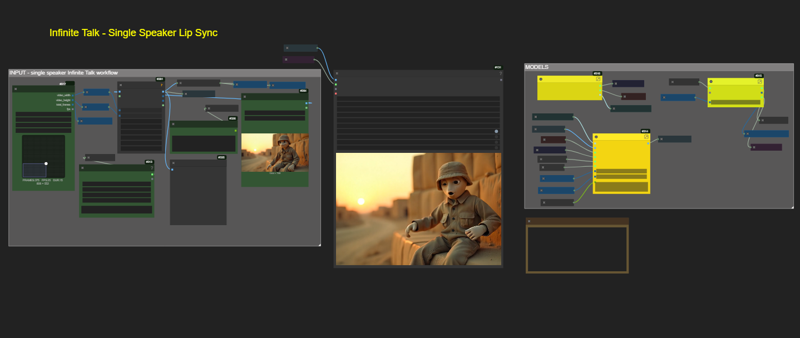

Switched over to InfiniteTalk model
Please note : this version uses subgraphs, please update your UI if necessary.
No spaghetti nightmare -- like some workflows.