Flux1 kontext (nunchaku+Multi_input+Lora、gguf) 70% time savings,Improved accuracy



















詳細
ファイルをダウンロード
モデル説明
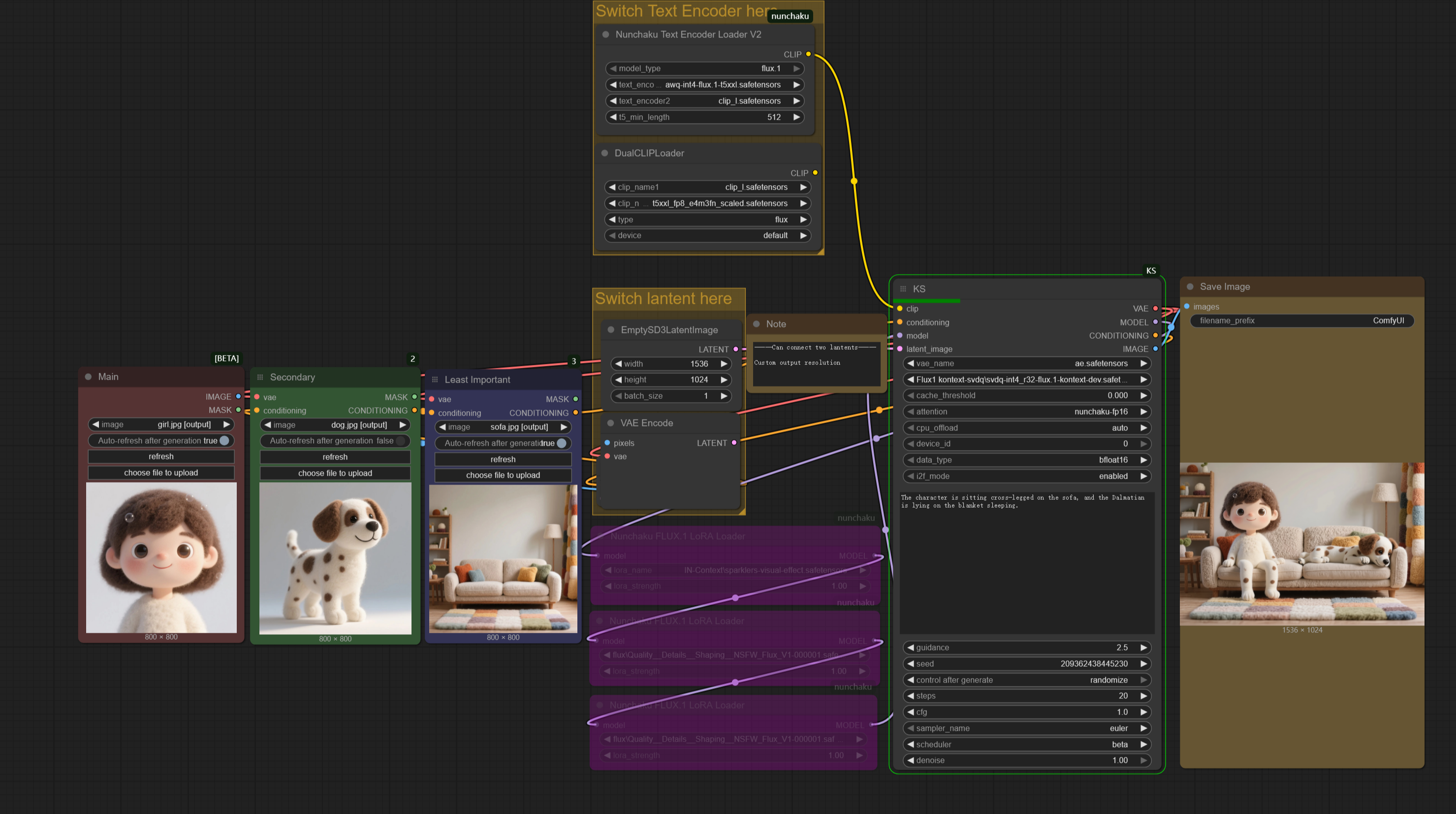
Nunchaku Multi_input+Lora
今、2つの別々のワークフローを含みます:
------Kontext_gguf&safetensors__Multi_input&Lora.json
------Kontext_nunchaku_Multi_input&Lora.json
mit-han-lab/ComfyUI-nunchaku をインストールしたが、正しく動かない人はこちらをご覧ください!
今回は、このワークフローの設定に本当に時間をかけました。公式ノードを使ったことがあるけど、複数の画像入力の使い方や、生成解像度のカスタマイズ方法、あるいはnunchaku-textencoderモデルへの切り替え方が分からない人向けに、このスリム化されたワークフローは完璧です!
nunchakuのint4モデルを使用した画像生成時間は、以前に比べて約1/4に短縮され、品質の損失も非常に小さいです。正直、もうggufは使いたくありません。
Nunchakuチェックポイント:
https://huggingface.co/mit-han-lab/nunchaku-flux.1-kontext-dev/tree/main
aqw-int4-flux.1-t5xxl(オプション):
https://huggingface.co/mit-han-lab/nunchaku-t5/tree/main
Nunchaku ComfyUIノード:
https://github.com/mit-han-lab/ComfyUI-nunchaku
ComfyUI-nunchaku インストールガイド(Windows):
ComfyUI_windows_portableディレクトリのアドレスバーにcmdと入力してEnterを押してください。その後、以下のコマンドを入力して、torchとPythonのバージョンを確認します:
"python_embeded\python.exe""python_embeded\python.exe -m pip list"
例えば、私の環境ではPython 3.12、torch 2.5.1+cu124と表示されます。
ComfyUI-Managerを使ってnunchakuノード(ComfyUI-nunchaku v0.3.3)をインストールするか、
ComfyUI_windows_portable\ComfyUI\custom_nodesディレクトリのアドレスバーにcmdと入力してgit clone https://github.com/mit-han-lab/ComfyUI-nunchaku.gitを実行し、手動でインストールできます。https://github.com/mit-han-lab/nunchaku/releasesから、あなたの環境に合ったnunchakuのwhlファイルをダウンロードしてください。私はステップ1でバージョンを確認済みなので、nunchaku-0.3.1+torch2.5-cp312-cp312-win_amd64.whlをダウンロードします。ダウンロード後、このwhlファイルをComfyUI_windows_portableディレクトリに配置し、"python_embeded\python.exe -m pip install nunchaku-0.3.1+torch2.5-cp312-cp312-win_amd64.whl"でインストールしてください。インストール後、ComfyUIを最新バージョンにアップデートし、再起動することを忘れずに。また、ダウンロードしたnunchakuモデルを
diffusion_modelsフォルダに配置してください。NVIDIA 40シリーズ以下のGPUにはint4を、50シリーズにはFP4を選択できます。私のテストでは、Python 3.11ベースのComfyUIは正しく動作しなかったため、注意が必要です。ただし、完全に確実ではありません。
gguf+Lora
「ワークフローが複雑すぎる?」、「ハードウェア要件が高すぎる?」、「モデルはどこからダウンロードすればいいの?」、「出力が入力画像を無視してしまうのはなぜ?」という疑問をお持ちの方へ。
このワークフローは初心者向けに作られています。本当にこれ1つのワークフローファイルだけで十分です。正直、私はほとんど何もしていません。公式ComfyUIワークフローを少し調整し、ggufとLoRAのサポートを追加しただけです。
使い方:
ワークフローまたはサンプル画像をComfyUIにドラッグし、不足しているノードをインストールしてください。
モデルをダウンロードし、
diffusion_modelsフォルダに配置して、ComfyUIをアップデートして再起動してください。
チェックポイント:
https://huggingface.co/bullerwins/FLUX.1-Kontext-dev-GGUF/tree/main
ガイド:
https://docs.bfl.ai/guides/prompting_guide_kontext_i2i
https://docs.comfy.org/tutorials/flux/flux-1-kontext-dev
https://comfyui-wiki.com/en/tutorial/advanced/image/flux/flux-1-kontext
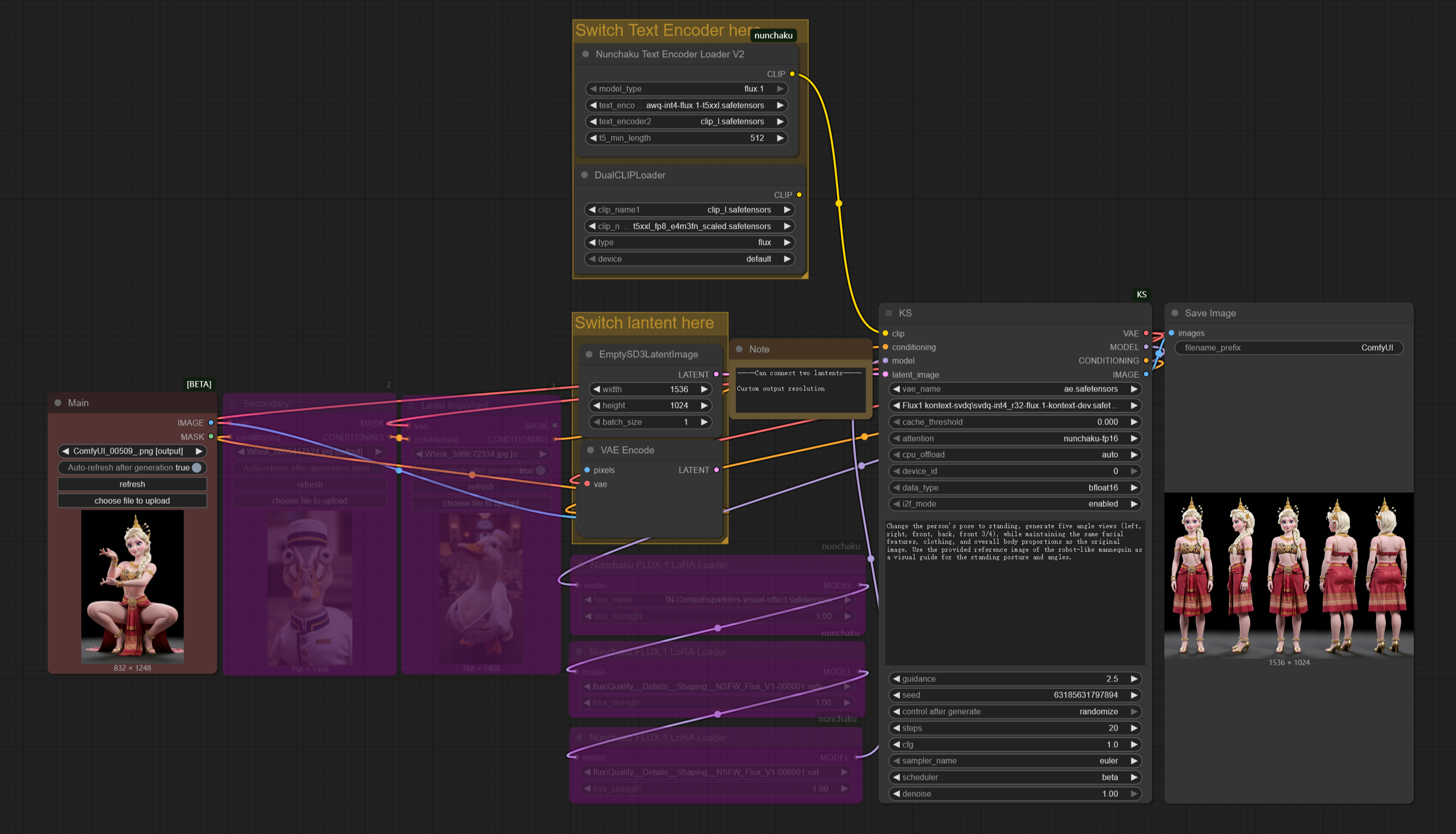
現在、Flux1 Kontextが可能なことはこれだけでも書ききれないほどありますが、主な機能を以下に挙げます:
画像スタイルの変更/スタイル転送。
画像内のオブジェクトの追加または削除。
キャラクターの行動(回転など)や表情を変更しつつ、外見を一貫させること。
複数のキャラクターやシーンの組み合わせ。
モデルのバーチャル試着。(私のテストではまだうまくいっていません。動いたことはありますが、結果に満足できませんでした。~ただし、これはオープンソースで無料です。)
だから、服を販売しているなら、モデルの試着にこの機能を活用してください!特定のモデルを指定せず、服の画像だけを提供すれば、Kontextがモデルを自動生成してくれます。この方法の方が、はるかに良い結果が得られます!