Anime Denser ✨ Wan2.1-T2V-14B

詳細
ファイルをダウンロード
モデル説明
ℹ️ メモ:ショーケース投稿の動画は、このLoRAが実現する内容を完全には表していません。代わりに、ギャラリーのグリッドに注目してください。
説明
これは、環境の構成的密度を制御することを目的とした(スライダー型)LoRAです。SD1.5時代から、詳細調整用や微調整用のLoRAが私の最も好きなタイプのLoRAでした。そのため、動画モデル用に同様のものを作成したいと考えました。
これは私が計画している強化型LoRAの最初のもの(ただし最後ではありません)。このLoRAは、ComfyTinkerがこのLoRAのために説明した手法に基づく、私が「差分LoRA」と呼ぶトレーニング概念に基づいています。私はこのアプローチに興味を持ち、それを再現することに決めました(ただし、ええと、別の分野で)。以下の2つのノートを参考にしました:1、2。
この概念自体は、単純かつ強力なアイデアに基づいています:ある特定の特徴のみが異なる2つのLoRAをトレーニングし、一方のLoRAをもう一方から減算することで、明確な概念を別のLoRAに「蒸留」することが可能になります。この派生LoRAを用いることで、推論時にその特徴の存在と強度を、単にその強度を調整するだけで制御できます。単一の概念を効果的に分離することで、非分離データセットで汎用的な概念LoRAをトレーニングした場合に避けられない副次的なノイズ特徴の「漏れ」を(理論的には)防ぐことが可能になります。しかし、2つのアンカーロラのトレーニングに使用するデータセットは、トレーニング対象の特徴以外はすべて非常に類似している必要があります。そうでないと、ターゲット概念LoRAを丁寧に抽出した後でも、特徴の漏れが発生する可能性があります。
この手法自体は決して新しいものではないことに注意してください。これは、以前から存在していたLECO、スライダーロラ(OstrisとAI Toolkitによって普及)、「Concept sliders」プロジェクト、FlexWaifu、SD Web UIのsd-webui-traintrain拡張機能、およびNLPのいくつかの手法(例:埋め込みのベクトル演算)と多くの共通点を持っています。kohya-ssの有名なsdv_merge_lora.pyスクリプトも同様です。しかし、これは私が動画モデルLoRAのトレーニングにこの手法を適用した初めての事例です(ただし、DiTの注意メカニズムは「古典的」トランスフォーマーとそれほど異なるわけではありません)。
(そして、この概念はMLに特有のものではなく、音声ノイズ低減のための位相キャンセルなど、古典的な信号処理の多くの手法と類似しています。)
使用方法
このLoRAは、独自でアニメスタイルを強制することはありません。しかし、私のリアルな動画への関心はゼロ以下であるため、私はこれを2DアニメーションLoRAと組み合わせて使用することを意図し、その文脈でのみテストしました。そのため、このLoRAを「Anime Denser」と命名しました。他の用途ではテストしておらず、今後もテストする予定はありません。
(とはいえ、このLoRAは2Dアニメーション専用にトレーニング・テストされていますが、私が正しく実装できていれば、リアルな動画にもおそらく動作するはずです。概念の分離というアイデアは、スタイルの違いを回避することを目的としています。ただし、これは私の推測にすぎません。)
私が公開したすべてのクリップは、このLoRAを「バニラ」(ベース)のWan2.1-T2V-14BモデルとスタジオジブリLoRAと組み合わせて生成しました。(ジブリLoRAは非常に強力で、独自に強化効果を発揮し、このLoRAの増幅効果を一部無視してしまう可能性があるため、最良の選択とは言えません。)また、このLoRAのデモ動画を作成するのに2日以上かからないように、self-forcing lightx2v LoRAも適用しました。
このLoRAで使用しているワークフローはWanVideoWrapperを利用していますが、LoRAローダーを含む任意のネイティブワークフローでも動作します。サンプルワークフローは、ショーケース投稿の動画を1つComfyUIにドラッグするか、以下からダウンロードできます:JSON。
(縦グリッド動画には組み込みワークフローが含まれていないことに注意してください。)
このLoRAの安全な強度範囲は、-3(環境密度を低くする)から**+3**(環境密度を高くし、構成的な「ごちゃごちゃ感」を強化する)です。長く複雑なプロンプトの場合、テキストエンコーダーの影響を補正するために+4または-4まで引き上げることも可能ですが、それ以上にするとおそらくノイズの多い出力になります。
(広範なテストの結果、高強度時にこのLoRAが、特に屋内環境で時折(必ずしもではない)緑色の彩度をわずかに増幅することがわかりました。その理由は不明です。減算処理中に何らかの特徴マップが不均等に減算された可能性があるか、あるいは照明を「密度化」しようとしているのかもしれません。)
データセット
差分LoRAでは、データセットが極めて重要です。私が選んだ概念(構成的密度)のために、2つのデータセットが必要でした:1つは非常に詳細な(「密集」)シーン、もう1つは低密度な(「疎」)シーンです。これらのシーンが共通点を多く持つほど、減算時のノイズキャンセル効果は高くなります。理想的には、同じシーンを異なる詳細度で収集したかったのですが、最初はアニメ映画からいくつかの詳細なシーンを収集し、VACEまたは低ノイズ設定でV2Vパイプラインを適用することを計画していました。
💡 しかし、その後2つのことが起こりました:
構成的密度のような概念をトレーニングするには、画像だけで十分であり、むしろそれがより良い可能性があると気づきました。なぜなら、これにより時間的ノイズの可能性を完全に回避できるからです。これはLoRAのトレーニング要件を大幅に低下させ、さまざまな設定を試す余地を大きく与えてくれました。(このLoRAに落ち着くまで、少なくとも20個のLoRAをトレーニングしました…)
FLUX.1 Kontext [dev]がリリースされ、私のタスクに最適なデータセットを簡単に作成できる方法が得られました。
そこで、細部に凝った環境で有名な新海誠監督の映画のシーンから100枚以上のフレームを取得し、Flux Kontextを活用したバッチワークフローに以下のようなプロンプトを入力しました:
このシーンの詳細度を減らし、食べ物、台所用品、本、ポスター、装飾品などの小さなオブジェクトやごちゃごちゃしたものをすべて削除してください。また、衣装の要素やキャラクターのアクセサリーを簡略化し、複雑なパターン、小さなアイテム、過剰な詳細を削除してください。キャラクターと全体のアートスタイルはそのままに、シーン全体を非常にシンプルで、詳細が少なく、ミニマリスト的なものに仕上げてください。
これは完璧に機能しました。その結果、126組の画像ペア(トレーニングデータに含めています)が得られ、差分LoRAの両方のコンポーネント(「密集」LoRAと「疎」LoRA)のデータセットを構成しました。以下はデータセットの画像ペアの例です:
1️⃣ 詳細で「密集」バージョン(オリジナルフレーム)

2️⃣ 簡略化された「疎」バージョン(Kontextで生成)

キャプションについては、さまざまなアプローチを試しました:
- 各データセットごとに異なる短いキャプション
- 両データセットで同じ短いキャプション
- 各データセットごとに異なる詳細なキャプション
- 同じキャプションだが、密集データセットのキャプションに「詳細」を追加
- 密集データセットには「詳細な画像」、疎データセットには「画像」とだけキャプション
- 各ペアに一意のIDを割り当て:例えば疎画像は「anime_image_165656」、その対応する密集画像は「anime_image_165656, detailed」とキャプション(このアイデアは、テキストラベルにシーンの内容をエンコードして「詳細度」の概念の減算を促進することでしたが、うまくいきませんでした)
- 空のキャプションを使用 🥳
そして(明らかに)空のキャプションが最も効果的であることがわかりました。
これはある程度理にかなっています。以下の画像、特に右側を見てください。Wanトランスフォーマーでは、MMDiTとは異なり、自己注意とクロス注意の部分は交互に配置されていません。
(この画像は、KijaiがBanodocoに投稿したもので、ソースはこちらです。)
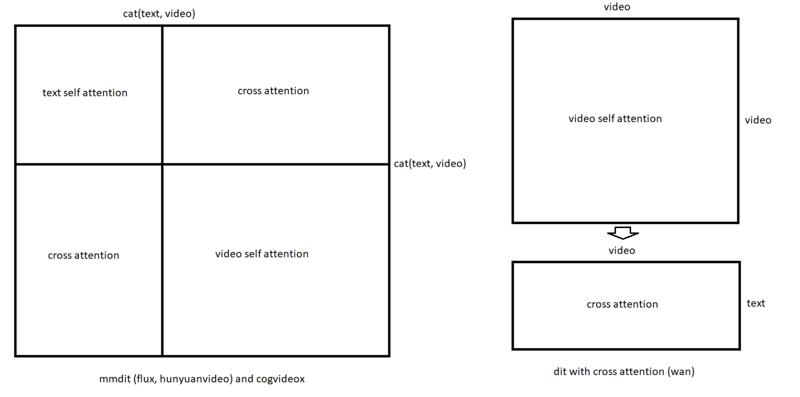
テキストキャプションは、テキストエンコーダーのアラインメントメカニズムを通じてLoRA重みにクロスアテンションノイズを導入する可能性があるため、空のキャプションで完全に無視することで、最小限のノイズを無条件に導入するのが最善の方法かもしれません。そして、Wanではクロスアテンションが「コア」の自己注意とは分離されているため、空のキャプションを使用することは、他のブロックを妨害せずにテキスト条件付けを効果的に「オフ」にすることを意味します。
(意味が通じないかもしれませんが、説明を探していたところ、これが私の最良の推測です。ただし、これは経験的観察とGemini Proの助けに基づいています。)
トレーニング
トレーニングには、いつものようにMusubi Tunerを使用しました。(Windows 11、RTX 3090、64GB RAM)
画像でのトレーニングが可能になったおかげで、差分LoRAの単一コンポーネントのトレーニングは非常に速くなりました。また、「密集」と「疎」の違いを捉えるだけであれば、詳細そのものを教える必要がないため、192pでトレーニングすることもできました。実際、具体的な詳細を学習したくなく、抽象的なコントラストのみを分離することが目的でした。
その結果、1組の複合LoRAを通常2~3時間でトレーニングでき、さまざまな設定を試す余地が大きく得られました。いくつかのトレーニング設定を試した結果、Lionオプティマイザ、学習率2e-5、50ステップのウォームアップを含むconstant_with_warmupスケジューラ、LoRAランク16、5000ステップ、バッチサイズ1を採用しました。(すべての設定ファイルをトレーニングデータに含めているため、ここでは詳述しません。)
正直、これらの設定はそれほど重要ではなかったと思います。いくつかのオプティマイザ、ステップ数、学習率、スケジューラパラメータを試しましたが、どれも大きな違いを生まなかったように思えます。また、「ごちゃごちゃ感」という抽象概念をトレーニングする前に、簡単な「昼間」LoRAを作成して練習しました:正午のシーンとKontextで生成した夜のシーンの20枚の画像を用意し、さまざまな設定で複数回トレーニングしました。共有データセットに40枚の画像しかなく、1時間もかからずトレーニングできました。この実験で最も効果的だった設定が、後にAnime Denserのトレーニングに使用した設定です。
したがって、私の意見では、最も重要なのはデータセットの「純度」と差分スクリプトに渡すパラメータ(後述)です。
両方のコンポーネントLoRAのトレーニング中に得られたサンプル画像は、非常にひどいものでした。しかし、それは良いことでした。なぜなら、それがまさに私が期待していたものだったからです(192x192の静止画でトレーニングして、きれいな結果を期待するなんてあり得ません!)。しかし、最も素晴らしい点は、両方のサンプルセットが似たようにひどい見た目でありながら、重要な違いがあったことです:密集LoRAは構成的なごちゃごちゃ感を注入する方法を明確に記憶しており、疎LoRAは空で無機質な環境を再現する方法を学習していました。したがって、減算処理中にそれらの「文脈に依存する」特徴が効果的にキャンセルされ、最終的なLoRAには環境の密度と詳細度の概念だけが残ると期待できました。その時点で、完成させる時が来たと感じました 👨🍳。
差分LoRA
2つのLoRAが得られた後、一方のLoRAをもう一方から減算する必要がありました。幸いにも、ComfyTinkerがこの手順の詳細な説明を共有してくれました(前にリンクしましたが、実際のコードは含まれていませんでした)。しかし、13年以上のソフトウェア開発経験を持つ私には、恐れることはありませんでした。Cursorを開き、説明を貼り付け、それに基づいてスクリプトを生成するよう指示しました。
その後、初期スクリプトのさまざまな改良を試しました(ここでは説明しません。まだ作業中だからです):名前パターンや数値インデックスで特定のブロックをターゲットにする、ターゲットノルムに基づいてアルファ値を自動計算する、マグニチュード閾値を使用してマージに参加するレイヤーをフィルタリングする、パーセンタイルベースのフィルタリングによる自動閾値計算、差分の大きさを計算して最も明確なレイヤーを見つける、高速ランダムSVDを追加して迅速なプロトタイピングを可能にする、デバッグ用のブロック構造分析の追加、非ターゲットレイヤーを出力からnullifyまたは完全に除外するオプションの追加などです。今後、他の差分LoRAプロジェクトでもこのスクリプトを継続的に改良・強化する予定ですが、現在の形でも十分な機能を果たしています。(差分LoRAを生成するためのスクリプトも、トレーニングデータのアーカイブに含めています。)
このテキストの使用方法について、詳細な指示で文字量を増やしません(コメントで質問されない限り)。本質的には、これは2つの入力LoRAの差分を計算することで新しいLoRAを生成します。以下が、私が差分LoRAを作成するために実際に使用したコマンドです:
python differential_lora.py ^
--lora_a animedenser_pos_wan14b.safetensors ^
--lora_b animedenser_neg_wan14b.safetensors ^
--target_blocks attn ^
--output animedenser_v01rc.safetensors ^
--rank 4 ^
--dtype float32 ^
--alpha 1.0 ^
--device cuda ^
--analyze_blocks ^
--exclude_non_targeted
(私はこれらのパラメータを、その影響を明確に理解せずに多数試しました。より効果的な方法でマージLoRAを作成できる可能性もあります。)
マージでは、アテンション層のみを対象としました(--target_blocks attn)。したがって、生成されたLoRAはモデルのアテンション機構のみに影響を与え、他のすべてのブロックはターゲットLoRAから除外されます(nullify されません、単に除外されます)。もし --exclude_non_targeted を省略した場合、他の層はnullifyされ、ベースモデルの重みに干渉して悪影響を及ぼします。その他の層(フィードフォワード、正規化など)は、ベースモデルの重みをそのまま使用します。私は、アテンション(特にクロスアテンション)ブロックが、構成的密度を導入するのに最適な場所だと判断しました。そして、うまくいったようです🤷♂️
選んだアルファ値は経験的に決定したもので、必ずしも最適とは限りません。(「最適」なアルファ値を自動計算する仕組みを実装しようとしましたが、期待通りに動作せず、逆に出力LoRAの効果を低下させました。)
このスクリプトを使用しようとしているなら、SVDは非常に計算コストの高い処理であることを認識してください。RTX 3090ですら、ランク16の2つのLoRAをランク4の差分LoRAにマージするのに約1時間かかりました。高速にテストしたい場合は、--fast_svd フラグを使ってスクリプトを実行できます。これは特異値分解の損失のある近似手法で、約5〜10秒でマージLoRAを生成し、その有効性を推定できます。結果が有望であれば、その後で完全なSVD分解を実行して最適なマージを得ることができます。
結論
このLoRAは、すべての本番利用ケースに実用的とは言えません(WanVideoのような強力なモデルでは、プロンプトに「ごちゃごちゃ感」や「空虚感」を直接指定する方が効果的かもしれません)。しかし、私は得られた結果を楽しめました。このLoRAが実用性の点で重要だとは言いませんが、この概念と方法が、「ごちゃごちゃ感」といった抽象的で「分散的」な概念に対しても有効であることを証明しています。
誰かがこの結果を役立てて、この方法をさらに発展させることを願って、共有します。もっと多くの人がこの手法を受け入れ、進化させてくれることを期待しています。これは、ビデオモデル用のスライダーを構築する比較的安価で信頼性の高い方法であり、非常に可能性があると考えています。(個人的には、モーションエンハンサー、デブラー、ディテールラー、そしてさらに奇妙なアイデアを訓練することを楽しみにしています。)
💾 このLoRAを再現するために必要なすべてのトレーニング資料(データセット、設定、スクリプト)を同梱します。この分野にはまだ多くの探索余地があり、私のスクリプトや方法は、達成可能な完全さや精度には遠く及びません。例えば、特定のブロックでのみLoRAをトレーニングしたり、マージ時に特定のブロックをスキップしたりする方が有益かもしれません。私は初期ブロック(0–10)、中間ブロック、または両方のみをマージして効果を向上させようと実験しましたが、明確な利点は見つけられませんでした。さらに、Wan DiTブロックをオン/オフ切り替えるシンプルなノードを作成して、どのブロックが何を担当しているかを理解しようとも試みました。(HVトレーニングでは、画像用のLoRAトレーニング時にダブルブロックをスキップするのが一般的だったと記憶しています。)残念ながら、これによって最適な戦略を特定することはできませんでした。私がマージに使用したコマンドからも分かるように、私はアテンションブロックにのみ焦点を当て、それらがシーンの無条件(プロンプト非依存)な「形状」を担当していると仮定しました。このアプローチは、すべてのブロックをマージするよりも効果的でした。
🤔 また、静止画でのトレーニングは(少なくとも計算的には)有効性を証明していますが、モデルのモーション能力に暗黙的なノイズを導入する可能性があると考えています。(次に差分LoRAを動画でトレーニングする予定なので、この点を早く解明したいです。)
🚀 さらに、Flux Kontextについても言及したいです。これは私にとって救世主となりました。誰もが知っているように、Kontextは、生成方法を知らないソース画像を入力し、それをKontextが理解できるものに変換することで、データセットを「逆向き」に構築できます。これは簡単かつ効果的です。私は、このツールが画像トレーニングを超えてさらに多くの用途を見出せる可能性があると考えています。おそらく、その力を活用する新しい革新的な方法がすぐそこにあります。
謝辞
🏆 最初に述べたように、この方法はもともとComfyTinkerによって提示されたものです。彼がこの方法をコミュニティと共有してくれたことに深く感謝します。彼のノートがなければ、私はおそらくこの方法を再現できず、あるいはそれにははるかに長い時間がかかっていたでしょう。
🏆 self forcing training method の作者たちにも大いに感謝します。彼らのWan蒸留モデルのおかげで、LightX2V プロジェクトが実現しました。blyss には、このモデルからWan Accelerator LoRAを抽出していただき、comfyanonymous にはComfyUIの開発に感謝します。そして何より、Kijai にはWanVideoWrapperでの素晴らしい貢献に心から感謝します。
🏆 最後に、banodocians の皆様へ。皆さんはWan関連(およびその他)のチャネルで毎日貴重な情報を共有してくれています。皆さんの洞察とアイデアは、このLoRAの作成に大きく貢献しました。