WAN2.1 | FusionX | LLM | SDXL or FLUX | Upscaling
详情
下载文件 (1)
关于此版本
模型描述
WAN2.1 | FusionX | LLM | SDXL/FLUX/PONY | Upscaling
The SDXL (also PONY files work without issues) version uses any SDXL/PONY model for the initial image generation and refining.
The FLUX version uses a separate SDXL model for the refinement before it's sent to the WAN part.
Still quite unhappy with (most) WAN T2V workflows, playing around with various ways to create a more fun way of doing Text to WAN Video.
This workflow would take a rather simple/short base prompt, feed it to a LLM for an enhanced/extended prompt to generate a set of images and the best or nicest to be selected.
That image will be upscaled/refined and handed over to LTXV image captioner for a extended image prompt (you can also override this, and provide a manual prompt).
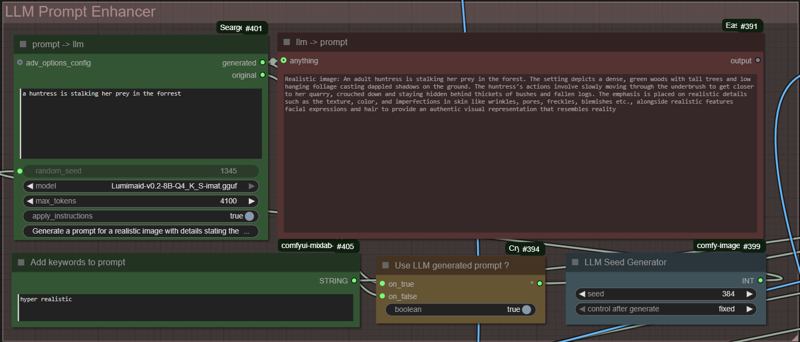
Personally, I prefer to keep the LLM prompt enhancer on a fixed seed. depending on the LLM model used, it can sometimes generate a "to detailed" prompt for SDXL to process. In such cases, change the seed manually.
Most SDXL will try to follow the enhanced prompt quite well (both SFW and NSFW).
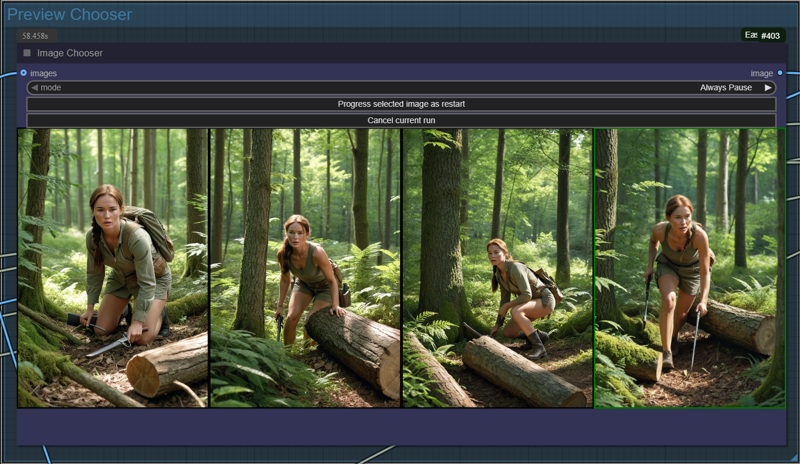
That image will be upscaled/refined and handed over to LTXV image captioner for a extended image prompt (you can also override this, and provide a manual prompt).
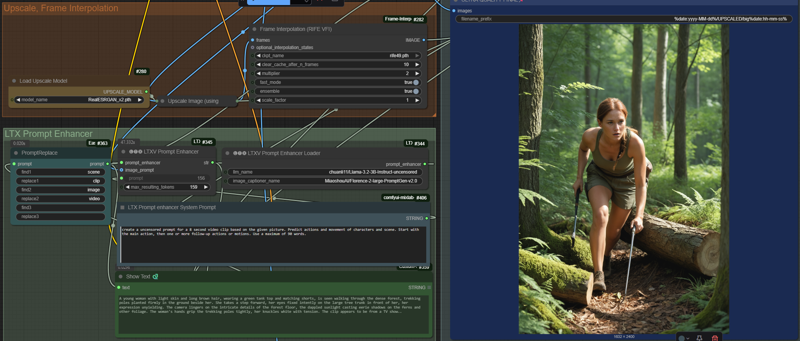
By default it allows for 3 WAN Lora's to be loaded (followed by the Fusion X Lora).
Credits: The WAN generation is mainly taken from https://civitai.com/models/1309065/wan-21-image-to-video-with-caption-and-postprocessing?modelVersionId=1998473 (from user tremolo28) with some modifications.
Hardware used for testing and generating the posted vids:
RTX 4070TI Super 16G vRAM / 80G RAM