Fast WAN I2V Compact

詳細
ファイルをダウンロード
このバージョンについて
モデル説明
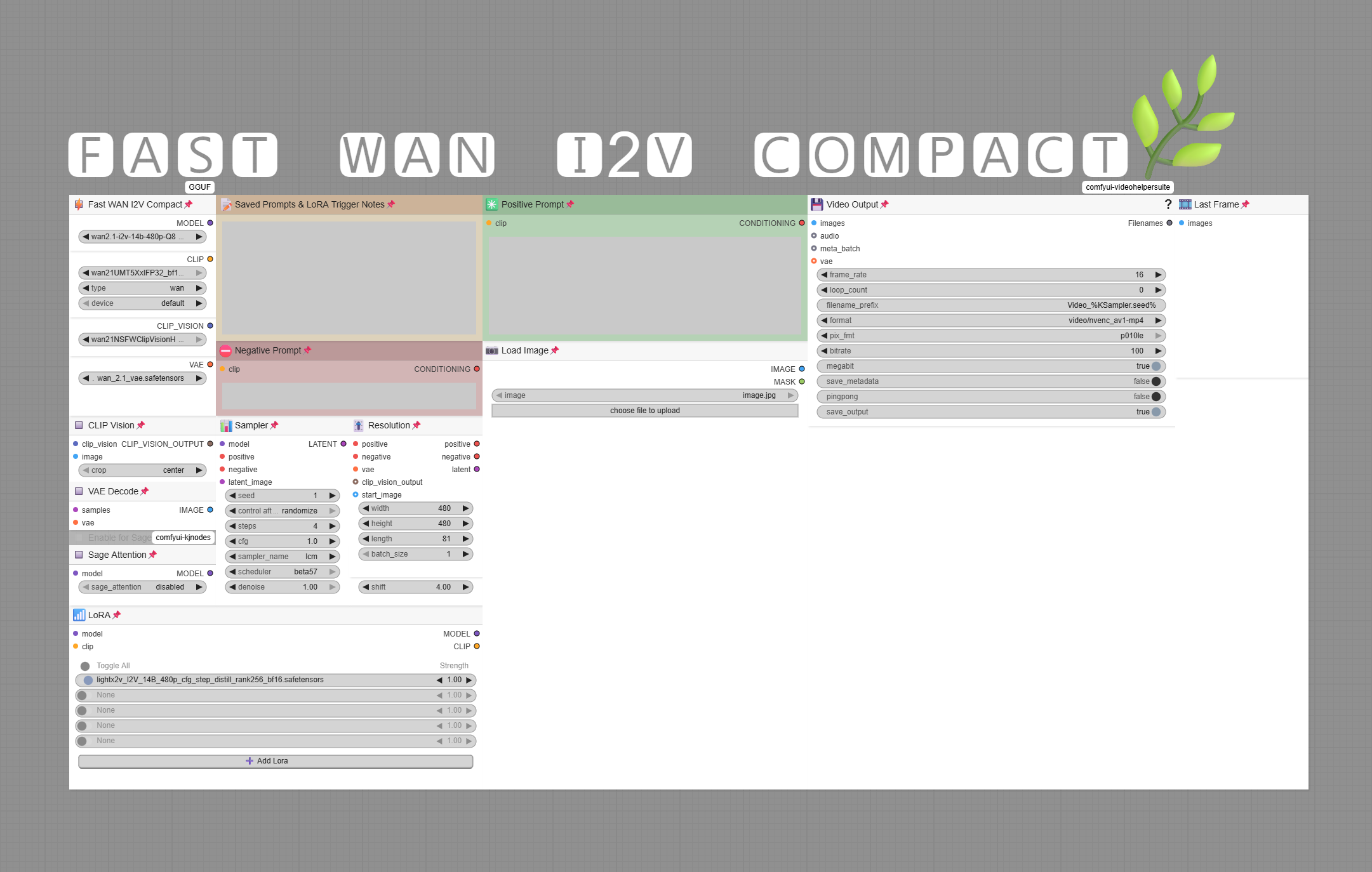
使いやすさを重視して、視覚的にコンパクトで簡素化されたデザインとなっています。個人的には、これが最も洗練されたワークフローだと考えています。全体的なレイアウトは、ユーザーにとって親しみやすく、直感的であり、ComfyUIのワークフウィンドウにぴったり収まるよう、スペースの無駄を最小限に抑えています。総じて、すべてのWAN動画生成ニーズに応えるワンストップショップです。
_________
このワークフローは、4070ti上でSage Attentionを無効にした状態で、Q8 GGUFまたはFP8モデルを使用して、60秒で5秒間の480x480動画を生成します。LCMサンプリングとLight X2Vを使用して生成時間を短縮しています。
このワークフローは主に基本的で一般的なノードと拡張機能を使用しているため、最小限の手間で簡単に動作させることが可能です。「もっと表示」をクリックすると、要件やモデルダウンロードリンクなどの詳細が表示されます。
注目すべき機能には、無限LoRAローダー、Sage Attention、生成の最終フレームを取得して動画拡張に使用する機能(最終フレームは手動で保存・読み込みが必要)、独立した動画結合ユーティリティワークフロー、および独立したアップスケーリング/補間ユーティリティワークフローが含まれます。これにより、生成された動画の選択的かつ簡単なポストプロセッシングが可能になり、パワフルPCから低性能PCまで、さまざまな使用シーンを考慮して設計されています。
_________
WAN 2.2用:
以前と同様のデザインですが、WAN 2.2の「低ノイズ」モデル専用に最適化されています。新しいワークフローの要件については、以下の「必要なモデル」セクションをご覧ください。
Light X2V LoRAは、WAN 2.2で1.1~2.0の強度で動作しますが、この強度はモデルの挙動を大幅に変化させ、有益な場合もあれば逆効果になる場合もあります。テストの結果、最も安定していると判断された1.5をデフォルト強度として採用しましたが、ご自身の環境に合う値を試してみてください。
WAN 2.2ははるかにダイナミックであり、WAN 2.1で使用していたプロンプトのスタイルとは少し異なる必要があります。LoRAへの影響も同様で、LoRAの強度が増幅される傾向があり、これは良い面もあれば悪い面もありますが、全体的には非常に良い結果が得られています。したがって、良い結果を得るための主なポイントは、プロンプトの書き方を学ぶこと、そしてLoRAの強度をLoRAの種類やプロンプト・画像入力との相性に応じて調整することです。ステップ数を6や8に変更することでも、結果が改善される可能性があります。
ワークフローのサンプラー/スケジューラ設定は比較的よく動作しますが、さらなる実験が必要です。特に下記要件に含まれるRES4LYFカスタムサンプラーとスケジューラ拡張機能では、他の組み合わせの方がより優れた結果を出す可能性があります。
一部の生成結果が予期しない方向に逸れる場合がありますが、設定を調整すれば、WAN 2.2はWAN 2.1では決して得られなかった多くの優れた結果を生成できます。
_________
WAN 2.1用:
変更したい主な設定は、出力解像度またはサンプラーのステップ数です。他のサンプラーまたはスケジューラも動作する可能性がありますが、LCM/SGM UniformまたはLCM/Beta57が最も整合性の高い出力を得られると思います。他に調整可能な設定としては、LoRAの強度があります。また、「SHIFT」のような設定も、CFGと似たような働きをします。私の経験では、この設定を変更することでプロンプトやLoRAの表現が大きく変わり、動きにも劇的な変化をもたらすことができますが、基本的にはデフォルト設定のままにしておくことをお勧めします。512x512や640x640の解像度も使用できますが、プロンプトの忠実度が若干低下する可能性があります。
_________
注意:Sage Attentionはデフォルトで無効になっています。Sage Attentionを有効にするには(事前準備が整っている場合)、"Enable for Sage Attention"ノードを選択し、Ctrl+Bを押して有効化し、その下の"sage_attention"オプションを「無効」から「有効」に変更してください。Sage Attentionを使用しない場合でも、ワークフローを動作させるにはこの拡張機能をインストールする必要があります。
_________
必要なモデルおよび代替モデル:
GGUF WAN 2.2 i2vモデル(「低ノイズ」バージョンのみ使用):
https://huggingface.co/bullerwins/Wan2.2-I2V-A14B-GGUF/tree/main
GGUF WAN 2.1 i2vモデル:
https://huggingface.co/city96/Wan2.1-I2V-14B-480P-gguf/tree/main
FP8 WAN 2.1 Light X2V(FP8ワークフロー用、独立した加速LoRAは不要。新しいデフォルト推奨方式。プロンプト忠実度が非常に高く、多くの品質問題が解決されています):
CLIPモデル:
または、より高精度なBF16 CLIPモデル:
https://huggingface.co/minaiosu/Felldude/blob/main/wan21UMT5XxlFP32_bf16.safetensors
CLIP Visionモデル:
または、カスタムNSFW対応CLIP Visionモデル(推奨):
https://huggingface.co/ricecake/wan21NSFWClipVisionH_v10/tree/main
VAEモデル:
Light X2V T2V LoRA:https://huggingface.co/Kijai/WanVideo_comfy/blob/main/Wan21_T2V_14B_lightx2v_cfg_step_distill_lora_rank32.safetensors
または、正式なLight X2V I2V LoRA:
または、Kijaiによる他のLight X2V実験版:
https://huggingface.co/Kijai/WanVideo_comfy/tree/main/Lightx2v
または、2025年10月にリリースされたさらに新しいLight X2V LoRA v2.0(LoRAがモデルに組み込まれていない場合、推奨):
https://huggingface.co/lightx2v/Wan2.1-Distill-Loras/tree/main
https://huggingface.co/lightx2v/Wan2.2-Distill-Loras/tree/main
RES4LYFカスタムサンプラーおよびスケジューラ:
https://github.com/ClownsharkBatwing/RES4LYF
_________
隠しプロのテクニック:透明または単色の画像(例:黒)を使用すると、i2vモデルをほぼt2vモデルとして動作させることができます。空白の入力画像から急速に遷移し、プロンプトに従って新しくコンテンツを生成します。ワークフローやモデルを変更せずに、t2v機能を簡単に実現できる方法です。
_________
その他の有用な情報:
WANは出力解像度の変更により挙動が大きく変化します。解像度が幅または高さのいずれかが480のときに最も良好な応答を示します。WAN 2.2は480pおよび720pモデルとして設計されていますが、異なる解像度では挙動が異なり、設定の調整が必要だったり、特定の解像度ではうまく動作しない場合があります。480x480で良好に動作する場合もあれば、512x512やそれ以上の解像度でより良い(または悪い)結果が出る場合もありますが、一般的に、幅または高さのいずれかが480または720のときに最も安定した出力が得られます。