Fast WAN I2V Compact

详情
下载文件 (1)
模型描述
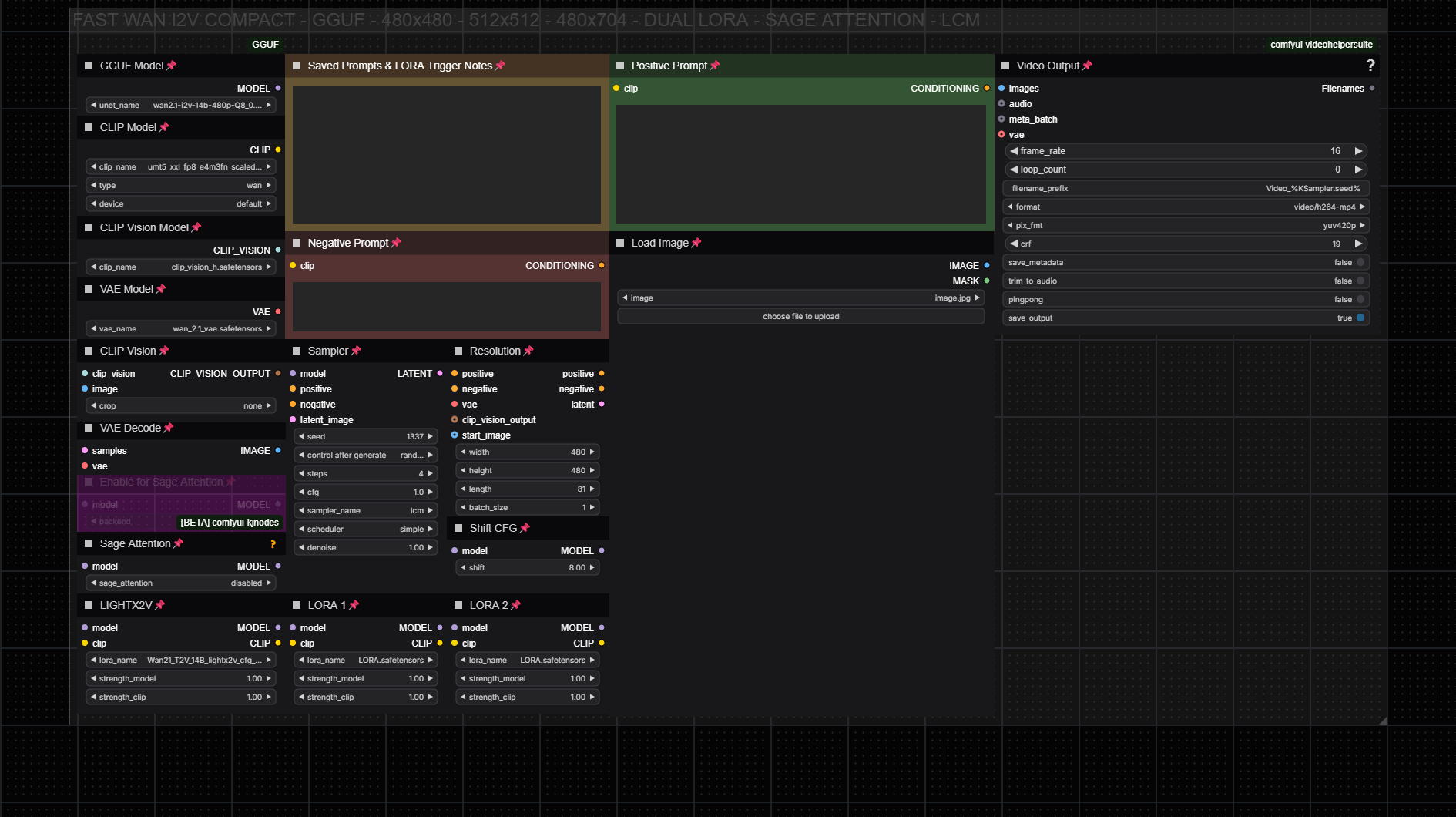
Designed to be visually compact and simplified for ease of use. Personally, I think this is the best streamlined workflow there is. The overall layout is designed to be user friendly, intuitive, and wastes as little space as possible while fitting very well into the ComfyUI workflow window. All in all, it's a one stop shop for all your WAN video generation needs.
_________
This workflow generates a 5 second 480x480 video in 60 seconds on a 4070ti with the Q8 GGUF or FP8 models without Sage Attention enabled and uses LCM sampling with Light X2V to speedup generation time.
This workflow uses mostly basic and common nodes and extensions, so it should be very easy to get working with minimal effort. Click "show more" for details like requirements and model download links.
Notable features include: an Infinite LoRA Loader, Sage Attention, the ability to grab the Last Frame of a generation for usage with extending videos (last frame must be manually saved and loaded), a standalone Video Combiner utility workflow, and a standalone Upscaling / Interpolation utility workflow, allowing for selective and easy post processing of your generated videos, and designed with consideration for a variety of use cases, from big to small, from power PC to potato PC.
_________
For WAN 2.2:
Same design as previously, but geared toward running the WAN 2.2 Low Noise model only. See "required models" section below for new workflow requirements.
The Light X2V LoRA works with WAN 2.2 at a strength of 1.1 to 2.0, and can dramatically alter the behavior of the model, in either beneficial or detrimental ways, so after testing I chose 1.5 as the default strength since that seemed to be the most reliable, but experiment to find what works for you.
WAN 2.2 is much more dynamic, which means it requires a slightly different prompting style than you might have used in WAN 2.1. The same goes for its affect on LoRA's, where they tend to be amplified in strength, which can be a good and bad thing, but overall I'm seeing some pretty good results with lots of keepers. So the main differences to get good results is to focus on learning how to prompt it and you may also need to tinker with LoRA strengths, depending on the LoRA and how it's behaving with your prompt and image input. Even changing it to 6 or 8 steps can also potentially improve results.
The workflow sampler/scheduler settings seem to work pretty well, but more experimentation is required, there could be other combinations that work better, especially in the RES4LYF custom samplers and schedulers extension (part of the requirements below).
There can be some bad generations that go off the rails, but all in all once you dial things in, WAN 2.2 can generate a lot of keepers that you could never get with WAN 2.1.
_________
For WAN 2.1:
The main settings that you may want to change would be primarily just output resolution or sampler steps. Other samplers or schedulers may work, but I find LCM/SGM Uniform or LCM/Beta57 provides the most coherent output. The only other setting you might want to fiddle with is the LoRA strengths. There are however other settings you can fiddle with, such as "SHIFT", which can somewhat work like a CFG setting. In my experience, it can be used to drastically change how a prompt/LoRA is expressed, while also creating more dramatic changes in movements, but generally this should be left at its default setting. A resolution of 512x512 or 640x640 can also be used, but can potentially lose some prompt adherence.
_________
Note: Sage Attention is disabled by default. To enable Sage Attention (if you have the pre-requisites installed) simply select the "Enable for Sage Attention" node and press Ctrl+B to enable it, then below it change the "sage_attention" option from disabled to enabled. Even if you don't plan on using Sage Attention, you will still need to install the extension for the workflow to operate.
_________
Required and alternative models:
GGUF WAN 2.2 i2v models (use only "low noise" version):
https://huggingface.co/bullerwins/Wan2.2-I2V-A14B-GGUF/tree/main
GGUF WAN 2.1 i2v models:
https://huggingface.co/city96/Wan2.1-I2V-14B-480P-gguf/tree/main
FP8 WAN 2.1 Light X2V (for FP8 workflow, no independent acceleration LoRA needed, recommended as new default way to run WAN, very good prompt adherence and many quality issues solved):
CLIP model:
Or the higher precision BF16 CLIP model:
https://huggingface.co/minaiosu/Felldude/blob/main/wan21UMT5XxlFP32_bf16.safetensors
CLIP Vision model:
Or the custom NSFW geared CLIP Vison model (recommended):
https://huggingface.co/ricecake/wan21NSFWClipVisionH_v10/tree/main
VAE model:
Light X2V T2V LoRA: https://huggingface.co/Kijai/WanVideo_comfy/blob/main/Wan21_T2V_14B_lightx2v_cfg_step_distill_lora_rank32.safetensors
Or the proper Light X2V I2V LoRA:
Or the other Light X2V experimentations by Kijai:
https://huggingface.co/Kijai/WanVideo_comfy/tree/main/Lightx2v
Or the even newer v2.0 of the Light X2V LoRA released in October 2025 (recommended if not using a model with the LoRA baked in):
https://huggingface.co/lightx2v/Wan2.1-Distill-Loras/tree/main
https://huggingface.co/lightx2v/Wan2.2-Distill-Loras/tree/main
RES4LYF custom samplers and schedulers:
https://github.com/ClownsharkBatwing/RES4LYF
_________
Secret Pro Tip: using a transparent or solid colored image, such as black, can turn the i2v model into essentially a t2v model. It will rapidly transition from the blank input image and generate something from scratch to try to follow your prompt. It's an easy way to get t2v capabilities without changing workflows/models.
_________
Other useful information:
WAN can change behavior dramatically with output resolution changes, it tends to respond best if the resolution is 480 in either width or height. WAN 2.2 is supposed to be a 480p and 720p model, but it may still behave differently at different resolutions, and require either settings tweaks or just not work well at certain resolutions. Some things can work well at 480x480, some things can work better or worse at 512x512 or higher resolutions, but typically you get the most stable outputs with 480 or 720 in the width or height.