Yellow Pearl AND Blue Pearl (Steven Universe)





















Details
Download Files (1)
Model description
This is an experimental model designed primarily to analyze how training can work.
Goals: To understand how training with words works. Why is this important? I always train exclusively on trigger words.
What you really need to know:
The model knows two characters—Blue Pearl and Yellow Pearl. I trained the model only on these two words.
The dataset included images of them separately and together. For some reason, the model occasionally and randomly shows elements from both characters in one image. For example, you might want to show Blue Pearl, but she ends up in Yellow Pearl’s outfit, or Yellow Pearl might appear in the background even though you didn’t want her to. Additionally, I’ve had tasks with the "2girls" tag, but Yellow Pearl would still appear in the background for some reason. Can this be fixed with words? Probably. I haven’t done many tests with negative prompts.
I’m leaving the dataset available for download so you can conduct your own analysis.
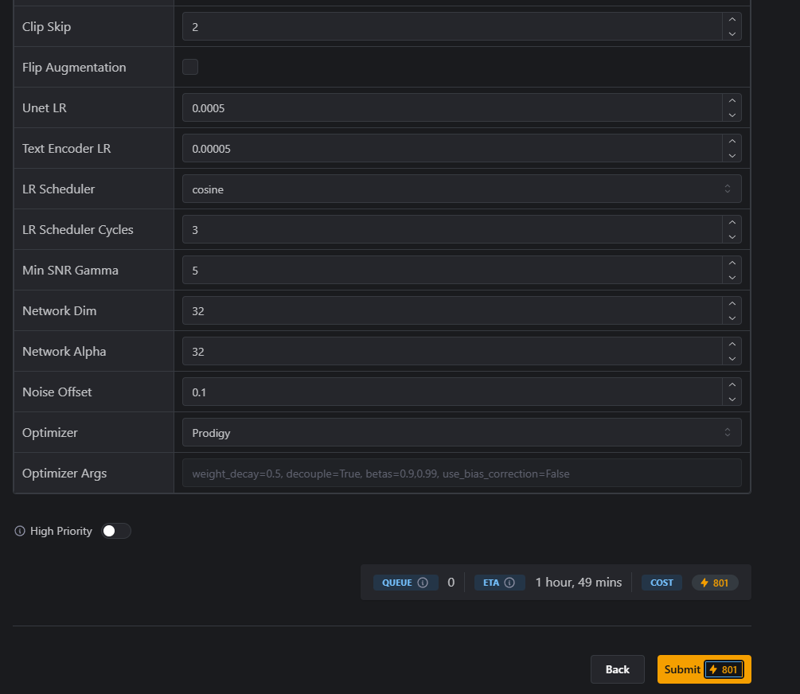
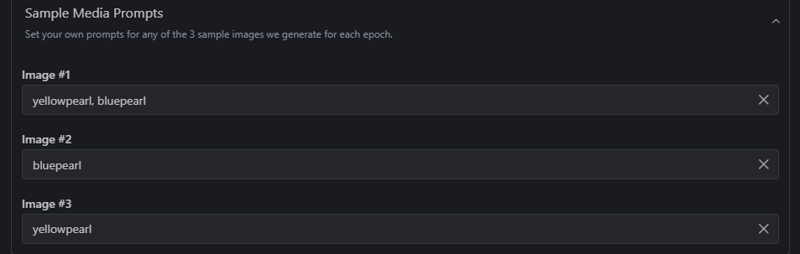
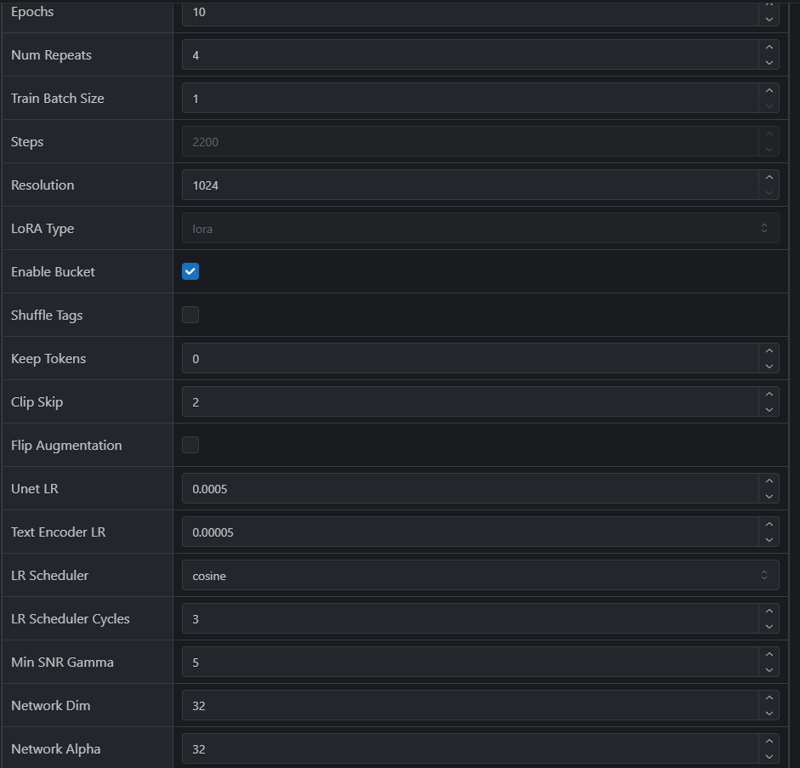
I’ll leave you screenshots of how this model was trained on CivitAI, which might be very useful if you ever want to train a model on one or more characters.
Next, I’ll talk about how the training went and what I should have done. This self-analysis might even be useful to you if you want to train models.
Since I only specified the characters’ names to the model and didn’t indicate any unique outfits, you can assume that the clothing sets will be chosen randomly if you don’t specify any outfits. Technically, you might get school uniforms since they were in the training set, but most of the time, you’ll get their traditional outfits from the cartoon. If I had added at least one or two tags to their traditional outfits, the training would have been much more controlled, but it would likely have required me to write those words out, as their absence in the prompt could have worked against me. We probably won’t find out, though, because this version suits me fine—I don’t really want to spend another 500–700 buzz on training.
I’ve trained quite a few models, to be honest. But I don’t publish many of them because a lot contain nuances that most people wouldn’t want to deal with.
This model has its flaws, but it handles the most interesting part well—style diversity. Since I trained it on a fairly large dataset, I was lucky that almost all the images had different styles, which helped the model avoid getting stuck on just one style. The model remembers similarities, and if the same style appears in 5 out of 10 cases, it might not be so easy for it to simply include some beautiful LoRA.
Finally, I’ll leave you with some tips that come to mind:
Teach the model what it doesn’t already know. It already knows what a cloak is and how it can billow in the wind, but, for example, your character’s horns might be too unique—you should probably specify them. The model remembers everything it sees. I really liked the example my dear Almaz left me. The guy’s name is literally Almaz. That’s powerful. But anyway. If you train the model on 1,000 images of matchboxes, where every match inside is multicolored, and in just one image, one match is black—the model will remember that black match. If you didn’t label the colors, the model will just keep generating black matches for you, because it remembers everything. Fear God if you train with artifacts, especially if your character is generated. You’ll only make the model always remember and draw those artifacts. It’s better to rethink your dataset sometimes. In some cases, I’ve even abandoned ideas just because the quality was poor. By the way, quality sometimes matters. Sometimes it even makes sense to upscale images. But you should consider a lot of factors. For example, if we’re talking about image resolution, have you ever wondered what the specified resolution means in training? Fact: images will be compressed if they’re larger than the specified size. Do you know what method is used to compress images during training? I personally can’t even imagine, so it’s better to compress everything yourself in advance if you’re worried about your work. But if you have no idea what’s going on, it’s perfectly fine to just let things happen. When training becomes something bigger and truly important to you, you’ll start analyzing your mistakes.
I could talk about many more parameters that are important to understand in training, but perhaps it’s better to create a separate section for that.
Oh, I almost forgot—one unique element of the characters is the gem on their chest. Including it in the training could have made a difference and added even more control, but I was too lazy. :y
Well, and it goes without saying that the neural network already knows how to undress characters without your help. You don’t need to teach it to draw bare chests unless your images feature unique elements like birthmarks. Keep in mind that to achieve the same results in generations, you’ll need to use the same prompts—meaning every unique feature is part of the tokens in generation. And tokens are usually not infinite. Or maybe I’m missing something, and there’s actually no problem generating with 100–200 words.