ModelMerger for ComfyUI (Chroma/Flux.1/SDXL/SD1.5/Qwen-image)

詳細
ファイルをダウンロード
このバージョンについて
モデル説明
Qwen ver.2
Qwen-image版のマージャーは、モデルが大きいため、できるだけ軽量に作られました。しかし以前のバージョンでは、ckptローダーを使ってワークフローに3つの巨大なckptを読み込む必要があり、極めて重かったのです。ver.2はその点で大幅に改善されています。今回はフルバージョンも用意しました。
入力では、ワークフローには基本モデルのみをモデルとして読み込み、マージに使用するモデル情報はファイルパスのみを受け取り、内部では必要な部分のみをアクセスします。マージされたモデルはVRAMにBF16状態で配置されるため、重くなるのは避けられません。そこで、サンプラーの前にFP8への変換ノードを配置しました。FP8への変換を含めても、プレビューは高速になるはずです。アップロードされた画像のワークフローを参照してください。私の環境では、BF16のままにした場合、使用されるVRAM容量は約48GBでしたが、FP8に変換後は約21GBになりました。即時プレビューを諦めれば、マージ自体にはそれほどVRAMを消費しません。その段階では消費量は約10GB程度で、そのほとんどはマージ後にプレビュー用に使用されるテキストエンコーダーです。
十分なVRAM空間がない限り、オプションのプリロード設定は使用しないでください。私の環境(32GB)では十分ではありませんでした。また、FP16とBF16はADA生成でより高速なので、試してみる価値があります。通常はあまり気にする必要はありません。
パスを接続するには、同時にインストールされたCheckpointPathPickerを使用してください。
ワークフローはスクリーンショットに収まるように圧縮されているため、参考にしないでください。
Qwen-image マージャー
これはQwen-image版です。
現在のところ、シンプル版のみをアップロードしています。
フルバージョンの需要はありますか?
HiDream以来、モデルのサイズに悩まされてきました。ChatGPTに「モデルを部分的にダウンロードできるか?」と尋ねたところ、可能だと答えられました。そこで、この部分版のプロトタイプを作成しました。それでも約10GBのVRAMを消費します。メインメモリもそれなりに使用するため、注意してください。
FP8はサポートされていますが、GGUFはサポートされていません。
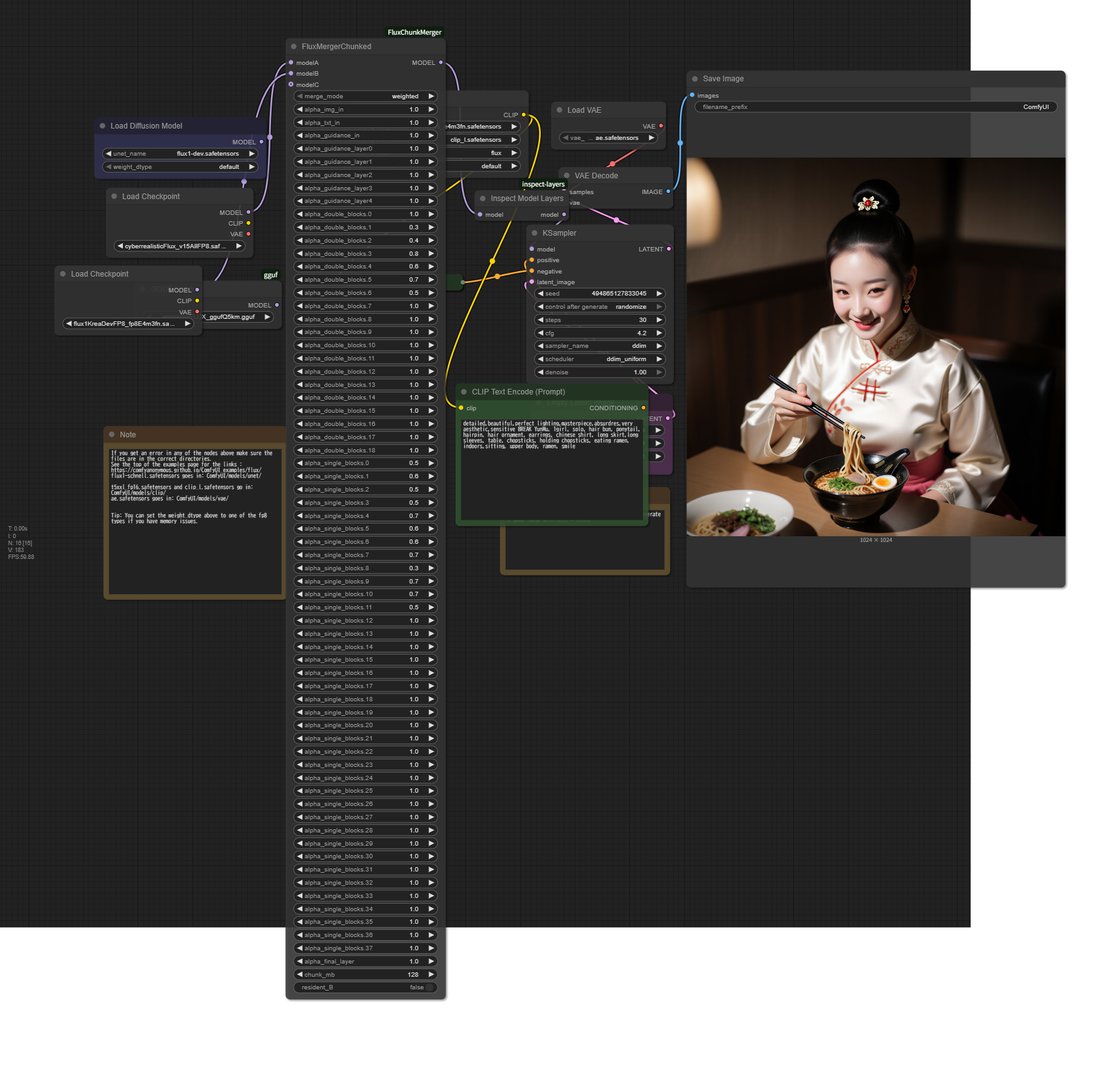
FluxMerger Chunked(低VRAM用)
このバージョンはVRAMをより少なく使用します。その代わりにメインメモリを多く消費します。フルサイズのT5を使用する場合、マージ時のVRAM使用量は約11GBです。しかし、ワークフロー内でKSsamplerに渡すと、BF16サイズ(約27GB)のVRAMを消費します。結果を確認するには、サンプラー直前にモデルを保存し、ComfyUIを再起動するのが速いです。再起動はComfyUI Managerから行います。
メモリ消費を抑えるため、処理のためのレイヤーをさらにチャンクに分割していますが、これにより効果が向上することはありません。むしろ軽微な悪影響が出る可能性があります。
注意:このバージョンはVRAMを減らす代わりにメインメモリを多く消費するため、マージが遅くなります。標準版で十分なVRAMがない場合にのみこのバージョンを使用してください。
SD15 FineMerger
これはSD1.5用のComfyUIモデルマージノードです。SDXLから得た教訓をもとに簡素化されています。
機能的には、以前のモデルとほぼ同一です。各レイヤーの重みを指定し、ウェイト付き、adddiff、traindiffでマージできます。また、いくつかの新機能も追加されています:
モデル全体のattn1とattn2にグローバルスケーリング係数を適用できます。
INおよびOUTレイヤーのスケーリング係数を同時に調整できます(私の理解では、MIDはIN12です)。
個人的には、これらの機能は非常に有用だと感じています。OUTのattn1のみを増強したい場合は、マルチステージ方式を使用してください。
サンプルワークフローでは5つのモデルと3つのブロックマージャーを使用しています。最もメモリを消費すると思われるtraindiffを使い、少し大きめの画像を4バッチに分けて表示した場合、最大VRAM使用量は17GBでした。しかし、モデルとノードのキャッシュをクリアしても6GBを消費するため、実際の使用量は約11GB程度です。
動作確認のために作成しただけでしたが、現在サンプルワークフローを見ると、とても奇妙に感じます…。このモデルは他の例よりも意味がありましたが、当初はNAI2リリース前に作られたBeyondにNAI2の要素を追加し、その後SimpleRetroの下層のネガティブtraindiffを混ぜ合わせ、Astarothの写実的表現を強化する実験を行ったものです。使用した値は極端に大きかったり小さかったりしますが、実用的には控えめな値の方が安全です。
SDXL FineMerger
これはSDXL 1.0版のモデルマージャーです。
実は私はSDXLをほとんど使ったことがなく、重要なポイントをまったく理解していません。モデル構成も極端で、レイヤーの粒度が全く異なり、誰がどうやって制御しているのか謎でした。今回少し試してみたところ、SD1.5では3レイヤーで処理していたものが、今や1レイヤーで済むようになったことに気づき、改善を実感しました。
SDXLでもSuperMergerが使用可能であり、ComfyUIには既にSDXLブロックマージノードが存在し、パラメータ数もそれほど多くないため、シンプル版が必要とは思えません。今回は、以前のバージョンとは逆に、より細かい制御を可能にする仕組みを試みました。
以下が主要スライダーの構成です。
time_embed., label_emb.
input_blocks.0.(128)
input_blocks.1.(128)
input_blocks.2.(128)
input_blocks.3.(128)
input_blocks.4.(64)
input_blocks.4.B0.(64)
input_blocks.4.B1.(64)
input_blocks.5.(64)
input_blocks.5.B0.(64)
input_blocks.5.B1.(64)
input_blocks.6.(64)
input_blocks.7.(32)
input_blocks.7.B0-2.(32)
input_blocks.7.B3-5.(32)
input_blocks.7.B6-9.(32)
input_blocks.8.(32)
input_blocks.8.B0-2.(32)
input_blocks.8.B3-5.(32)
input_blocks.8.B6-9.(32)
middle_block.0.(32)
middle_block.1.(32)
middle_block.1.B0-2.(32)
middle_block.1.B3-5.(32)
middle_block.1.B6-9.(32)
middle_block.2.(32)
middle_block.2.B0-2.(32)
middle_block.2.B3-5.(32)
middle_block.2.B6-9.(32)
output_blocks.0.(32)
output_blocks.0.B0-2.(32)
output_blocks.0.B3-5.(32)
output_blocks.0.B6-9.(32)
output_blocks.1.(32)
output_blocks.1.B0-2.(32)
output_blocks.1.B3-5.(32)
output_blocks.1.B6-9.(32)
output_blocks.2.(32)
output_blocks.2.B0-2.(32)
output_blocks.2.B3-5.(32)
output_blocks.2.B6-9.(32)
output_blocks.3.(64)
output_blocks.3.B0.(64)
output_blocks.3.B1.(64)
output_blocks.4.(64)
output_blocks.4.B0.(64)
output_blocks.4.B1.(64)
output_blocks.5.(64)
output_blocks.5.B0.(64)
output_blocks.5.B1.(64)
output_blocks.6.(128)
output_blocks.7.(128)
output_blocks.8.(128)
out, sampling_sigma, noise_augmentor.
調整する価値がないと判断した設定はグループ化しました。レイヤー内のサブブロックごとに重みを指定できます。これらは個別に使用可能であり、これだけで以前のマージャーよりもはるかに精密な制御が可能です。また、括弧内の数字はそのレイヤーが処理するUnetの画像サイズです。個人的には、これを知ることで他の部分を推測できると考え、追加しました。
ただし、細分化レベルが1段階下がったため、Transformerレイヤーで補完しない限り、SD1.5よりも粗くなります。ここでは、10段階のVision Transformerを3段階にグループ化し、重みを指定できるようにしています。
また、2つ目のスライダーも接続可能です。2つ目のスライダーは特定のTransformerレイヤー専用で、attn1、attn2、ff/normの比率を指定できます。適用される値は1つ目のスライダーと掛け算されます。これらの方法で得られるアルファ値は、3つのモードでマージできます:Weighted(通常マージ)、AddDifference、TrainDifference。アルファ値の取り扱いとマージモードはSuperMergerに基づいており(ComfyUIとは逆に、0と1の値が反転しています)。
コントローラーノードを使わずにマージ可能です。コントローラーノードのスライダーのデフォルト値は1(=何もしない)なので、変更したい設定のみ調整してください。
input_blocks.4.attn1
input_blocks.4.attn2
input_blocks.4.ffnorm
input_blocks.5.attn1
input_blocks.5.attn2
input_blocks.5.ffnorm
input_blocks.7.attn1
input_blocks.7.attn2
input_blocks.7.ffnorm
input_blocks.8.attn1
input_blocks.8.attn2
input_blocks.8.ffnorm
middle_block.1.attn1
middle_block.1.attn2
middle_block.1.ffnorm
middle_block.2.attn1
middle_block.2.attn2
middle_block.2.ffnorm
output_blocks.0.attn1
output_blocks.0.attn2
output_blocks.0.ffnorm
output_blocks.1.attn1
output_blocks.1.attn2
output_blocks.1.ffnorm
output_blocks.2.attn1
output_blocks.2.attn2
output_blocks.2.ffnorm
output_blocks.3.attn1
output_blocks.3.attn2
output_blocks.3.ffnorm
output_blocks.4.attn1
output_blocks.4.attn2
output_blocks.4.ffnorm
output_blocks.5.attn1
output_blocks.5.attn2
output_blocks.5.ffnorm
このノードを作成した後、あまりに細かすぎるのではないかと思いました。スライダー連動方式のテストのために作成しましたが、ComfyUIのマージノードに満足できない場合は、ぜひお試しください。
HiDream DeltaLoRAツール
HiDreamモデルは大きすぎて、ComfyUI上でマージツールを作成できませんでした。
代わりに、2つのモデルから差分LoRAを作成するツールを開発しました。これはそれほどメモリを消費しません。しかし、合計1615レイヤーの中でもDoubleBlocksとSingleBlockだけ使用しても、すべてのレイヤーの差分を取るとLoRAのサイズはとてつもなく大きくなるため、非常に限られたレイヤーのみを抽出して使用してください。このツールのMODEL出力は差分を考慮して作成されるため、保存することで部分的にマージされたモデルに近いものを得られます。より精密な調整には、LoRAとして使用し、強度を設定してください。
このツールはCUDA専用です。FP8(e4m3enなど)も入力ファイルとして使用できますが、内部ではBF16で処理されます。GPUがBF16をサポートしていない場合、FP32に変換されます。
*連続して処理を行うには、ComfyUI Managerの「Free model and node cache」ボタンを押してください。
Flux.1 マージャー
以前、SimpleFluxMergerを発表した際には、Schnellしか使っておらず、dev版と正しく互換性があるか確信がありませんでした。その後、ComfyUIのメモリ関連の動作が不安定になり、当時持っていた16GBカードでも画像生成が難しくなりました。
この問題は今日まで続いています。以前はあまり考えずに作ってもスムーズに動いていたのに、今はどれほど丁寧に作っても遅くなってしまいました。Flux.1を動作させるには少なくともGPUに64GBのメインメモリが必要です。
マージ時に約30GBのVRAMが使用されます。RTX 5090と互換性を持つように設計されていますが、それでもそれだけのメモリを消費します(ほぼVRAMを使わない遅いバージョンも作成しましたが、非常に遅いです)。多くの環境では、30GBの共有GPUメモリがあれば動作すると思います。
Chroma版と同様に、フルバージョンとシンプルバージョンがあり、それぞれに初期値が異なる3つのノードが用意されています。
注意点はChroma版とほぼ同じです。
いくつかのスクリーンショットではSamplerCustomAdvancedを使用していますが、これは大量のメモリを消費するため、マージにはKSamplerを使用するのが安全です。
 *TrainDifferenceの動作例
*TrainDifferenceの動作例
ChromaMerger
Chroma関連のツールが少ないため、ComfyUI用にこのマージノードを作成しました。
Chromaのすべてのレイヤーのブロックマージが可能です。スライダー範囲は-1~2で、AddDifferenceとTrainDifferenceと同等のモードを備えています。
CUDA専用です。ComfyUIは最新版に保ってください。
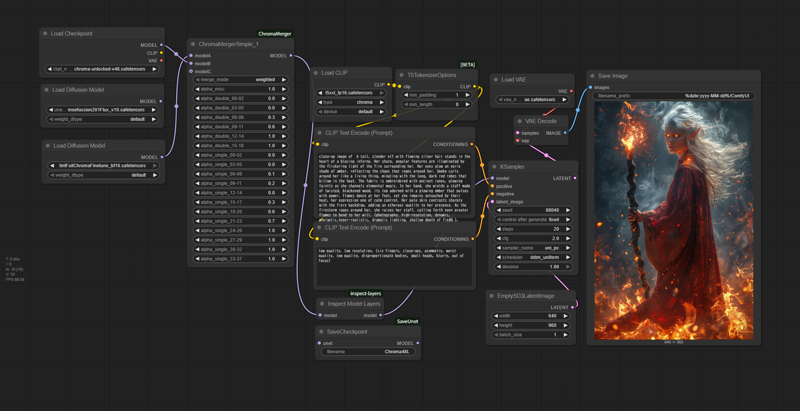 *シンプル版
*シンプル版
それぞれに通常版(66スライダー)とシンプル版(19スライダー)の3つのバージョンがありますが、初期スライダー値以外はすべて同じ動作をします。スライダー値を手動で変更するのは面倒なため、一括で変更したい場合は、新しい初期値を持つバージョンを読み込むだけで済みます。
追加ツールも含まれています:モデル構成をコンソールに表示するツールと、モデルのUnet部分をCheckpoint形式(Checkpoint Loaderで読み込める形式)で保存するツールです。これらは必須ではありませんが、役に立ちます。
注意:
スライダー値はSuperMergerなどに基づいています。α=1はModel Bを100%に設定します。これはComfyUIとは逆です。
GGUFは使用できません(おそらくNF4も?)。ロードが遅れるため、モデルを読み込んだ後にファイル自体にアクセスできず、情報が正しく取得できませんでした。事前に通常のsafetensorsファイルに展開してください(参考:https://github.com/purinnohito/gguf_to_safetensors)。
Chromaとしてリリースされたモデルには、複数の異なるテンソル形状が混在しています。自動調整を目指しましたが、メモリを多量に消費し、マージに問題が生じたため、断念しました。テンソル形状を確認するためのツールもアップロードしました。
大量のメインメモリとVRAMを消費します。Flux.1よりコンパクトであるべきですが、Flux.1はすべての内部処理がBF16で行われるため、メモリ消費量が少ないです。ChromaMergerはBF16を使用してメモリ消費を削減していますが、サンプラーその他のプログラムでFP32に拡張されるため、Flux.1よりも多くのVRAMを必要とします。メモリリークの警告は明らかに正常です。合計で約45GBの共有メモリを使用するため、事前に容量を確認してください。
モデルBとして指定されたモデルはVRAMに配置されます(AとCはメインメモリです)。GPUメモリ容量とBF16化されたモデルのサイズ(通常約11GB)を確認してください。
2回目以降はさらに多くのメモリを消費します。これは明らかにComfyUIの正常な動作ですが、以前使用したモデルがVRAMに残ったままになるため、特にサンプラーの速度が低下します。ComfyUIを再起動するのが通常はより高速です。ComfyUI Managerを使用している場合、続行する前に「Free model and node cache」ボタンを必ず押してください。
開発環境はメインメモリ64GB + VRAM 32GBです。低メモリGPUでの動作は保証されません。このコードは主にChatGPT 4.1が出力したものです。問題が発生した場合は、コードをChatGPTに送信してサポートを求めてください。
Flux.1では発生しなかったさまざまな問題が発生しています。その結果、使用環境は限定的で可用性はそれほど高くありませんが、最小限の処理が可能になりました。
Flux.1でLoRAを使用する場合、そのプラットフォームのライセンスが適用される可能性があることに注意してください。