Wan2.2 - continuous generation (subgraphs)
詳細
ファイルをダウンロード
このバージョンについて
モデル説明
編集3:I2V lightx2vがまもなく公開される可能性がありますが、ネイティブ側にはまだ大きな改善は見られません。その際、v0.4の2サンプラー版を作成するかもしれません。
編集2:さらにいくつかテストを実施しました。現在の状態と比較して、トランジションに大きな改善は見られず、ほとんどは問題なく動作し、残りの部分もそれほど悪くありません。
ComfyUIがSI2Vモデルに対して行ったように、Wan2.2用のネイティブな拡張ノードが追加されるまで休憩します。その過程でサブグラフの問題も修正されるかもしれません。
あなたの創造的な生成物の共有をまだお待ちしています :)
編集:Context Windowsで結果がまちまちだったため、いまだにv0.5を公開していません。
v0.4;
これをv0.3.1と呼ぶべきか、v0.4と呼ぶべきか迷いましたが、いくつかの問題を解決するのに時間がかかったため、v0.4とします。
タイルデコードがこれほど多くの問題を引き起こすとは思いもよりませんでしたが、現状就是这样です。ほとんどの目に見えるアーティファクトはそれに関連していました。そのため、従来のVAEデコードに切り替えました。また、その変数も編集しました。OOMが発生した場合はタイル化に切り替えて変数を下げてください。ただし、temporal_sizeを生成フレーム数より小さくすると、その周辺のフレームで色が変化するため、変更しないことをお勧めします。tile sizeも同様で、「タイル化」の四角い焼け付きを引き起こします。
また、品質損失を最小限に抑えるにはfp32のVAEを使用することをお勧めします; https://huggingface.co/Kijai/WanVideo_comfy/blob/main/Wan2_1_VAE_fp32.safetensors
テンポラルにいくつかフレームを追加しました。まだ完璧ではありませんが、前述の通り、ときにはうまく機能します。そのときの見た目は非常に良好です。
まだ1分付近に少しブロム効果が残っています。公式のlightx2v LoRAに切り替えましたが、それらはブロムを少し改善するものの、動画が進むにつれて過剰露出になるため、KijaiのリポジトリのLoRAをそのまま使用します。ただし、ゴースティングの問題にはご注意ください。
クオンタイズレベルが影響するかどうかはわかりませんが、システムが対応できる場合は、I2Vモデルには高品質なクオンタイズを推奨します。
サブグラフの更新についてComfyUI-Frontendをテストしていませんので、現時点では以下のように1.26.2版を使用してください:
.\python_embeded\python.exe -m pip install comfyui_frontend_package==1.26.2
T2Vの出力をどこにも接続しなければ、ワークフローはそれをスキップします。
また、Wan用の新しいノードが追加されたのを見ました。時間ができたときに確認します。
Redditに投稿していないと、生成物の共有が減ってしまうようです :( 皆さんはどんな秘密の生成物を生んでいるのでしょう?見せてください \o-o/
v0.3;
以前の編集でも述べましたが、今後安定版を確認できるまでComfyUI Frontend 1.26.2をご使用ください。コマンドはv0.2の下か、v0.3の変更ログでご確認いただけます。
今回は、最終マージ保存機能にわずかな改善を加えました。部品ファイルは個別に保存され、すべての処理が完了したときにのみマージされます。これにより、一時領域の使用量がより最適化され、最終保存以外では容量を節約できます。ただし、最終保存時にはすべてのデータを読み込むため、ややメモリを消費しますが、ファイルサイズは大きくありません。
非常に基本的なテンポラルモーションブラーを実装しました。実際には、前の5フレームを異なる重みでブレンドしています。すべてを解決するわけではありませんが、トランジションがシームレスに見えることがあります。重みを変更して、より良い結果を見つけてくれた方は、共有してください。
また、各部品ごとに3つのLoRAローダーノードを配置し、部品固有のLoRAを読み込む方法を示しました。これを基に拡張してください。
さらに、最終保存サブグラフ内に単純なアップスケールモデルノードを使用したアップスケールサブグラフを追加しました。または、そこに配置した基本的なアップスケール画像ノードを接続して使用できます。いずれも、アップスケールに時間がかかるため、デフォルトではバイパスされています。
そして、デフォルトの動画フォーマットは縦向きになりました。
仕上がりには少し満足していますが、プロンプトの遵守度が終盤でやや低下します。試していたシーンの問題かわかりませんが、より高品質なCLIPを使用すれば改善するかもしれません。
最後に、現在私が最も人気のあるアセットクリエイターのランキング1位となっています。これは非常に意味があります。ご協力いただいたすべての皆様、特にフィードバックや興味深い生成物を共有してくださった方々に感謝します。
今後もさらに多くの作品を楽しみにしています。素敵な生成を!
v0.2;
編集2:
- リンクされたサブグラフとバイパス機能が壊れたため、現時点ではComfyUI Frontend 1.26.2にロールバックする必要があります。
.\python_embeded\python.exe -m pip install comfyui_frontend_package==1.26.2
編集:
- トランジションフレームが再び重複する問題を発見し、修正しました。
- 生成に失敗した場合、最新のマージ済み.mkvファイルをより小さなファイルに変換して開けるように、mp4変換ワークフローを追加しました。
- 推奨フレームレートがデフォルトで16を超える問題を修正しました。
さらにいくつか実験を行いました。サブグラフが気に入っていたため、より広く知られるようにしたいと思い、モデルロードや他のオプションをサブグラフ内に移動しました。これによりコミュニティが自由にカスタマイズできるようになり、メインページもすっきりしました。少し複雑になるかもしれませんが、説明のノートを追加したので、ぜひご確認ください。
動画マージを実装しました。ただし、各部品ごとに前のファイルと動的にマージされるため、圧縮アーティファクトが問題となりました。最初の部品が何度も圧縮されるためです。この問題を回避するため、これらの部品はロスレスのffv1-mkv形式で保存することにしました。ワークフローの最後には、最終出力をh264 mp4形式で保存するための「最終保存」ノードも用意されています。
デフォルト設定で、832x480x81x6 I2V部品で30秒の生成を行った場合、一時フォルダーの容量は1GB未満です(ComfyUIを再起動するたびにこのフォルダーは自動クリーンされます)。生成が完了したら手動で削除することもできます。
また、最終出力に使用したい場合のために補間ノード(デフォルトでバイパス)を追加しましたが、6x81フレームの処理には時間がかかります。
他にも、最後の画像をoutputsフォルダーに保存する機能を実装しました。また、すべてのサンプラーに適用できるグローバルシードオプションも追加しました。以前の生成を再開したり、特定のパラメータを変更して再生成したい場合に便利です。
不要な場合は、outputsフォルダーから定期的にこれらのファイルを削除するか、手動で無効化してください。
フィードバックをここやRedditで共有してくれたコミュニティの皆さん、ありがとうございます。ここにも生成物を共有していただけると嬉しいです :)
今後は、より滑らかなトランジションなど、本当に大きな機能を実装しない限り、すぐに次の更新を公開しないかもしれません。
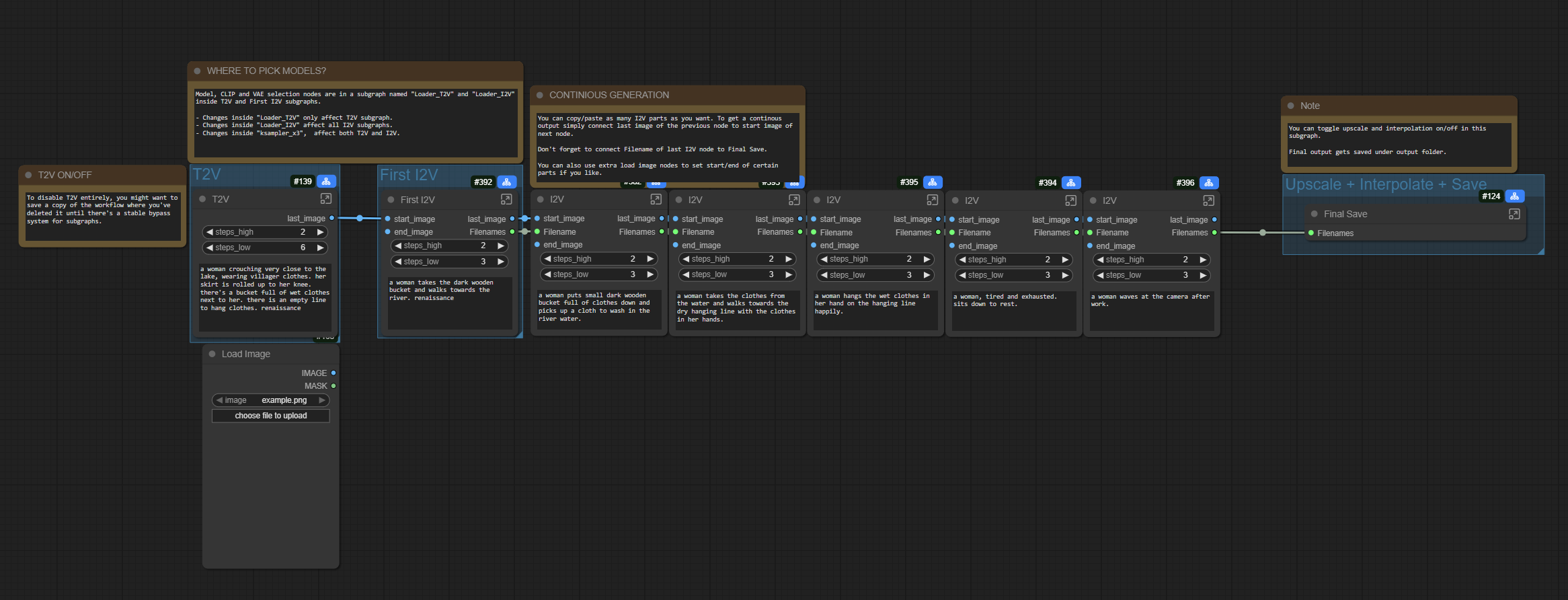
このワークフローは、ComfyUIの新しいサブノードを活用した実験です。
動画生成の最後のフレームを次回生成の最初のフレームとして入力します。しかし、大量のノードが絡み合うスパゲッティではなく、同じKSAMPLERサブノードを共有し、繰り返しイテレーションする単一のI2Vノードで実現しています。これはComfyUI版のフレームパックと考えてください。また、各生成を個別にプロンプト設定できます。ネガティブは共通で保持していますが、動的に変更することも可能です。
後処理としてのスティッチング機能は実装していませんが、基本的な動画編集ソフトで処理しています。ただし、今後追加することも可能です。
編集:後でマージしないと決めたため、出力動画をoutputsフォルダーに保存するのを忘れていました。そのため、ファイルはcomfyui/tempフォルダーに保存されます。(このフォルダーは次回ComfyUIを起動するたびにクリアされます。)
v0.1の最初の動画は834x480、1 3 3サンプルで生成に23分かかりました。2番目は624x368、1 2 2サンプルで13分かかりました。2番目の動画は、last_frameが2回表示される問題を修正した最新版で生成されています。
古いバージョンは非常にバグが多いため、ComfyUI Frontendを必ず更新してください。まだいくつかバグが残っている可能性がありますのでご注意ください。ポータブル版の更新コマンド:
.\python_embeded\python.exe -m pip install comfyui_frontend_package --upgrade
サンプリングプロセスは1 + 3 + 3で、最初のステップはスピードLoRAを適用せず、以降のステップは基本的な高・低サンプリングにスピードLoRAを適用しています。すべてカスタマイズ可能ですが、「KSAMPLERサブノードはすべてのメインノードで共通して使用されているため、変更はすべてのノードに即座に適用されます!」。I2V_latentサブノードについても、出力解像度や各部品の長さを変更したい場合は同様です。
生成を拡張したい場合は、I2Vサブノードのいずれかをクリックしてコピーし、Ctrl+Shift+Vで接続を含めて貼り付け、前のノードの最後の画像をそのstart_image入力に接続してください。また、T2V生成をスキップしたい場合は、ロード画像ノードを最初のI2Vのstart_image入力に接続できます。(ノードをキーボードショートカットでバイパスしないでください。サブノードが破損する可能性があります。)
ネイティブモデルではシステムがクラッシュするため、すべてGGUFクオンタイズモデルで実装しています。プロセスを変更したり、Patch Sage Attentionを無効にしたり、モデルローダーサブノードからモデルコンパイルノードを有効にしたりすることは自由ですが、その分速度の低下が顕著です。
私の4070TiでSage++とTorch Compileを有効にした場合、T2V + 6x I2V(合計30秒)の生成には約20~25分かかりました。
今後、コミュニティからさらに優れたワークフローが登場することを楽しみにしています :)