Qwen Image In Context Control Union


詳細
ファイルをダウンロード
モデル説明
"""
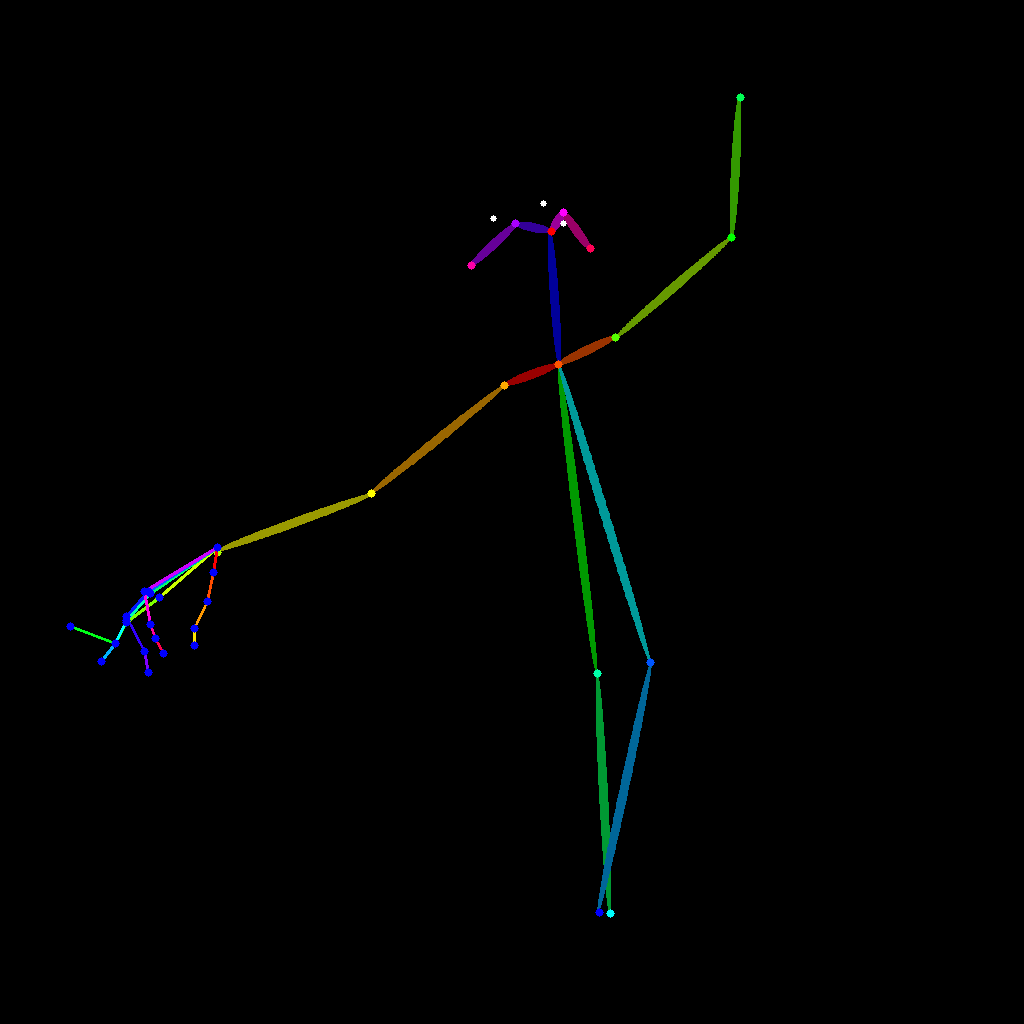
このモデルは、Qwen-Imageを基盤として、In Context技術を採用して訓練された画像構造制御用LoRAです。複数の条件をサポートしています:canny、depth、lineart、softedge、normal、openpose。訓練フレームワークはDiffSynth-Studioに基づいて構築されており、使用したデータセットはQwen-Image-Self-Generated-Datasetです。入力プロンプトは「Context_Control.」で始めることが推奨されます。
https://www.modelscope.cn/models/DiffSynth-Studio/Qwen-Image-In-Context-Control-Union
"""
このモデルで生成された画像
画像が見つかりません。