Pony V7 base





















Details
Download Files (4)
Model description
Pony V7 is a versatile character generation model based on AuraFlow architecture. It supports a wide range of styles and species types (humanoid, anthro, feral, and more) and handles character interactions through natural language prompts.
Fictional
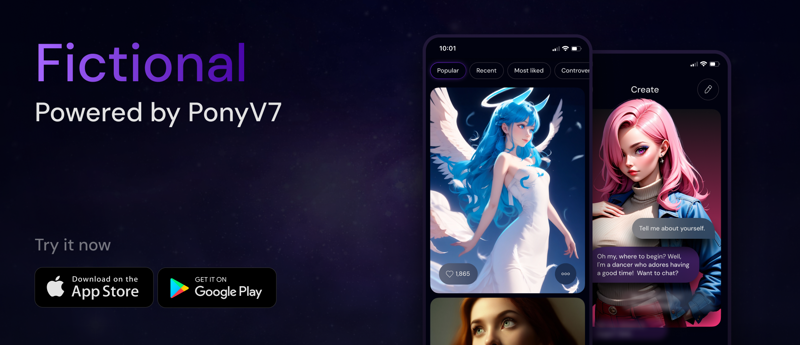
First, let me introduce Fictional - our multimodal platform where AI Characters come alive through text, images, voice, and (soon) video. Powered by PonyV7, V6, Chroma, Seedream 4, and other advanced models, Fictional lets you discover, create, and interact with characters who live their own lives and share their own stories.
Fictional is also what enables the development of models like V7, so if you’re excited about the future of multimodal AI characters, please download Fictional on iOS or Android and help shape our future!
iOS: https://apps.apple.com/us/app/fictional/id6739802573
Android: https://play.google.com/store/apps/details?id=ai.fictional.app
Get in touch with us
Please join our Discord Server if you have questions about Fictional and Pony models.
Important model information
Sorry to keep you waiting for so long, the landscape of the image generation model changes dramatically since the release of V6. Please check this article to learn more about why it took so long for us to ship V7 and upcoming model releases.
Model prompting
This model supports a wide array of styles and aesthetics but provides an opinionated default prompt template:
special tags, factual description of image, stylistic description of image, additional content tagsSpecial Tags
score_X, style_cluster_x, source_X - warning: V7 prompting may be inconsistent, please see the article as we are working on V7.1 to address this.
Factual description of image
Description of what is portrayed in the image without any stylistic indicators. Two recommendations:
Start with a single phrase describing what you want in the image before going into details
When referring to characters use pattern
<species> <gender> <name> from <source>For example "Anthro bunny female Lola Bunny from Space Jam".
This model is capable of recognizing many popular and obscure characters and series.
Stylistic description of image
Any information about image medium, shot type, lighting, etc. (More info TBD with captioning Colab)
Tags
V7 is trained on a combination of natural language prompts and tags and is capable of understanding both, so describing the intended result using normal language works in most cases, although you can add some tags after the main prompt to boost them.
Captioning Colab
To get a better understanding of V7 prompting, we are releasing a captioning Colab with all the models used for V7 captioning.
TBD (next week)
Supported inference settings
V7 supports resolutions in the range of 768px to 1536px. It is recommended to go for higher resolutions and at least 30 steps during inference.
Highlights compared to V6
Much stronger understanding of prompts, especially when it comes to spatial information and multiple characters
Much stronger background support - both generation of backgrounds and using background with character
Much stronger realism support out of the box
Ability to generate very dark and very light images
Resolution up to 1536x1536 pixels
Expanded character recognition (some V6 characters may get less recognized, but generally we extended the knowledge by a lot)
Special thanks
Iceman for helping to procure necessary training resources
Simo Ryu and the rest of FAL.ai team for creating AuraFlow and emotional support
City96 for help with GGUF support
diffusers team for supporting AuraFlow integration work
PSAI Server Subscribers for supporting the project costs
PSAI Server Moderators for being vigilant and managing the community
Many supporters that decided to remain anonymous but their help has been critical for getting V7 done.
Technical details
The model has been trained on ~10M images aesthetically ranked and selected from a superset of over 30M images with roughly 1:1 ratio between anime/cartoon/furry/pony datasets and 1:1 ratio between safe/questionable/explicit ratings. 100% of all images have been tagged and captioned with high quality detailed captions.
All images have been used in training with both captions and tags. Artists' names have been removed and source data has been filtered based on our Opt-in/Opt-out program. Any inappropriate explicit content has been filtered out.
Limitations
This model does not support text generation and has degraded text generation capabilities compared to base AuraFlow
Special tags (including quality tags) have much weaker performance compared to V6, meaning score_9 would not necessarily yield better results on some prompts. We are working on a V7.1 follow-up to improve this
Small details and especially faces may degrade significantly depending on art style, this is a combination of outdated VAE and insufficient training which we are trying to improve in V7.1
LoRA training
We recommend using SimpleTuner for LoRA training following this guide.
, please stand by for diffusers support, Comfy workflows and training guides.
Downloads
Comfy Workflow: TBD
Commercial API
We provide commercial API via our exclusive partner FAL.ai
License
This model is licensed under a Pony License
In short, you can use this model and its outputs commercially unless you provide an inference service or application, have a company with over 1M revenue or use in professional video production. This limitations do not apply if you use first party commercial APIs.
If you want to use this model commercially, please reach us at [email protected].
Explicit permission for commercial inference has been granted to CivitAi and Hugging Face.