WAN2.2 S2V Pro - AI Sound-to-Video Suite with Voice Cloning

詳細
ファイルをダウンロード
モデル説明
テキストや画像を超えてください。この革新的なワークフローは、音声をAIアニメーションの原動力として活用します。1枚の画像と任意の音声入力から、音声と同期した圧倒的な動画を生成できます。統合型ボイスクローン(TTS)機能により、スクラッチからナレーション付き動画を作成可能。WAN2.2の140億パラメータ音声→動画モデルを活用し、真正なマルチセンサリーなAI体験を実現します。
ワークフローの説明
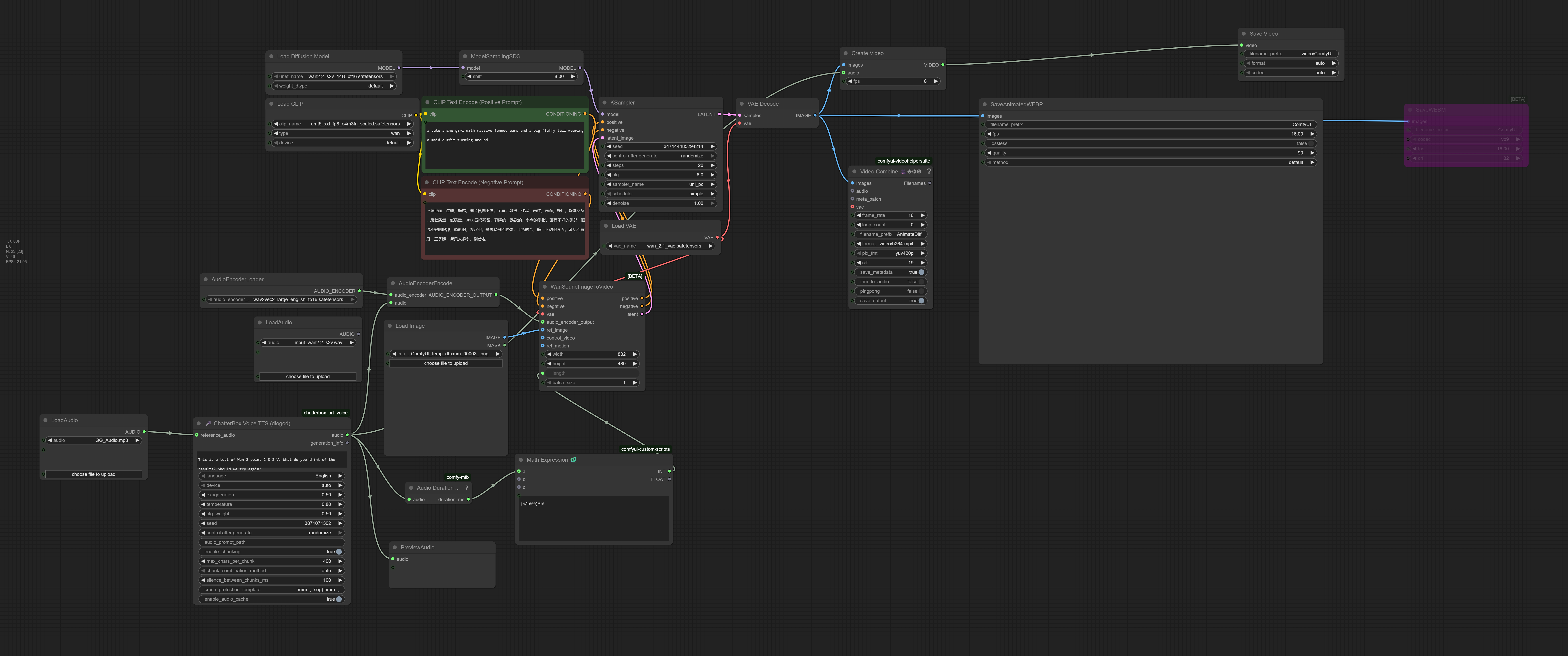
AI動画生成の次なるフロンティアへようこそ。このワークフローは、専用のWAN2.2 S2V(音声→動画)140億パラメータモデルを活用し、音声ソースと密接に連動するアニメーションを生成します。このモデルは音声を単に上書きするのではなく、音声の特性(会話、音楽、効果音)を活用して、生成される動画の動きとダイナミクスを制御します。
音声→動画の魔法:
ナレーション駆動のアニメーション: 文장을話すと、キャラクターの動きが言葉のパターンに微細に同期します。
ミュージックビデオ効果: 音楽トラックを入力すると、アニメーションの動きと流れがリズムとテンポに反応します。
完全なストーリーテリング: 統合型ボイスクローン機能により、1枚のキャラクター画像とスクリプトだけで、ナレーション付きの完全な物語を作成できます。
これは単なるアニメーションツールではなく、音声と映像のAI連携を探求するコンテンツクリエイター、ストーリーテラー、アーティストのための強力なパイプラインです。
機能と技術的詳細
🧩 コアコンポーネント:
モデル:
wan2.2_s2v_14B_bf16.safetensors(専用音声→動画モデル)VAE:
wan_2.1_vae.safetensorsCLIP:
umt5_xxl_fp8_e4m3fn_scaled.safetensors音声エンコーダ:
wav2vec2_large_english_fp16.safetensors(モデル用に音声をエンコード)
🎙️ 統合型ボイスクローン(TTS):
ノード:
ChatterBoxVoiceTTSDiogod機能: テキストからリアルな音声を生成。参照音声ファイル(
GG_Audio.mp3)から声をクローンできます。使用例: ノード内でナレーション用スクリプトを作成すると、生成された音声が動画アニメーションを駆動します。
🎬 出力とエンコード:
柔軟な出力形式: 最大限の互換性を確保するため、複数の形式で保存されます:
音声付きMP4動画:
CreateVideo+SaveVideoノードで出力。アニメーションWEBP: 高画質でファイルサイズの小さいループ用。
WEBM: 現代的な動画形式。
VHS_VideoCombine: 追加のエンコードオプションを提供。
自動再生時間計算: ワークフローは自動的に音声ファイルの長さに基づいて正しい動画長さを計算します。
使用方法 / 実行ステップ
前提条件:
専用モデル:
wan2.2_s2v_14B_bf16.safetensorsモデルを必ず準備してください。これは標準のT2V/I2Vモデルとは異なります。ComfyUI Manager: 欠けているカスタムノード(特に音声長さノード用の
comfy-mtb)をインストールするために必要です。音声ファイル: 音声ファイル(例:
input_wan2.2_s2v.wav)を用意するか、組み込みのTTSを使用します。
方法1:ご自身の音声ファイルを使用
画像を読み込む:
LoadImageノードで開始画像(例:キャラクターのポートレート)を選択します。音声を読み込む:
LoadAudioノードで.wavまたは.mp3ファイルを選択します。プロンプトを作成: Positive Prompt ノードでキャラクターまたはシーンを記述してください。Negative promptはすでに設定済みです。
プロンプトをキューイング: 音声がエンコードされ、画像のアニメーションを駆動します。
方法2:ボイスクローン(TTS)で音声を生成
画像を読み込む: 上記と同じく、開始画像を選択します。
声の参照音声を提供: 下部の
LoadAudioノードに、クローンしたい声の短い音声サンプル(GG_Audio.mp3)を指定します。スクリプトを入力:
ChatterBoxVoiceTTSDiogodノードで、声に言わせたいテキストを変更してください。例:"This is a test of Wan 2 point 2 S 2 V. What do you think of the results?"プロンプトをキューイング: ワークフローは以下の処理を実行します:
クローンした声でテキストから音声を生成。
生成された音声で動画アニメーションを駆動。
音声と同期した最終動画を保存。
⏯️ 出力: 動画は ComfyUI の output/ フォルダーに、選択された複数形式(MP4、WEBP、WEBM)で保存されます。
ヒントとコツ
音声品質: 最良の結果を得るには、背景ノイズのない明確な音声ファイルを使用してください。モデルは音声をエンコードするため、品質が重要です。
プロンプトは依然として重要: 動きは音声が駆動しますが、テキストプロンプトはキャラクターやスタイルを定義します。「笑顔で話す人物」のようなプロンプトは、一般的なプロンプトより音声とよく同期します。
音声を試してみてください: 音楽、効果音、会話など、さまざまな音声を試してみてください。それぞれ異なる動きのスタイルを生み出します。
長さの計算:
MathExpressionノードは動画長さを次のように計算します:(audio_duration_in_ms/1000)*16_fps。同じ音声クリップでより長いまたは短い動画を生成したい場合は、この式を調整できます(例:(a/1000)*8で8fpsのスローモーション効果)。トラブルシューティング: エラーが出た場合、まず標準のWANモデルではなく、正しい
wan2.2_s2v_14B_bf16.safetensorsモデルが使用されているか確認してください。
このワークフローは、AI動画生成における注目すべき、かつ未開拓の可能性を示しています。自動コンテンツ生成、ダイナミックなミュージックビジュアル、パーソナライズされた物語構築に広大な可能性を開きます。
音声が主役となったとき、あなたが創り出すものを見るのが楽しみです!