Audio-Driven Video Generation | Wan2.2-S2V

Details
Download Files (1)
Model description
Try it out first to decide whether to install it. in case you are not satisfied.
https://www.runninghub.ai/post/1961049452163305473?inviteCode=rh-v1213
use my invitation code(rh-v1213) , you'll get 1000 points
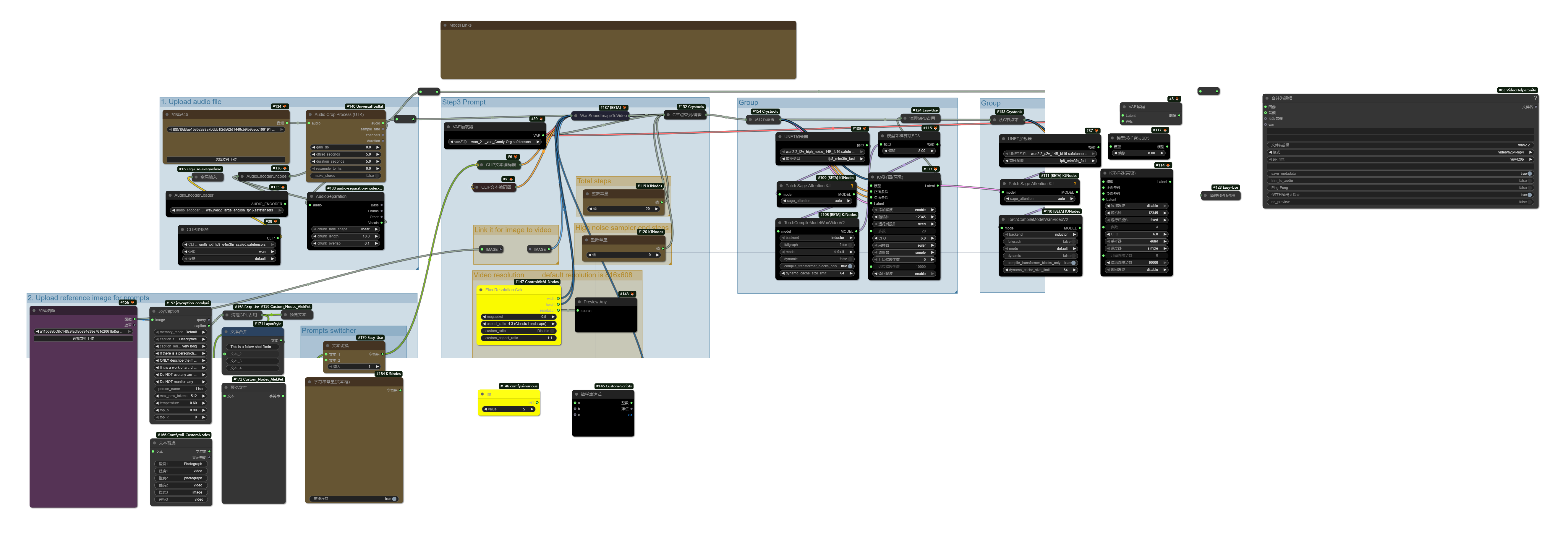
Upload a audio file and set duration
Enter prompts
You can find the associated model at Civitai.com
[wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors]
[wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors]
[wan_2.1_vae.safetensors]
Wan2.2-S2V is an AI video generation model that can convert static images and audio inputs into video content. The model can generate videos up to minute-level duration in a single generation, providing new solutions for video creation in digital human livestreaming, film production, and education industries.
The model performs well in film and television application scenarios, capable of generating facial expressions, body movements, and camera language. It supports full-body and half-body character generation, able to complete various content creation needs such as dialogue, singing, and performance.